Um Hello
WHAT DO YOU MEAN YOU’RE NOT ON SQL SERVER 2019 YET.
Oh. Right.
That.
Regressed
Look, whenever you make changes to the optimizer, you’re gonna hit some regressions.
And it’s not just upgrading versions, either. You can have regressions from rebuilding or restarting or recompiling or a long list of things.
Databases are terribly fragile places. You have to be nuts to work with them.
I’m not mad at 2019 or Batch Mode On Rowstore (BMOR) or anything.
But if I’m gonna get into it, I’m gonna document issues I run into so that hopefully they help you out, too.
One thing I ran into recently was where BMOR kicked in for a query and made it slow down.
Repro
Here’s my index:
CREATE INDEX mailbag ON dbo.Posts(PostTypeId, OwnerUserId) WITH(DATA_COMPRESSION = ROW);
And here’s my query:
SELECT u.Id, u.DisplayName, u.Reputation,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pq WHERE pq.OwnerUserId = u.Id AND pq.PostTypeId = 1) AS q_count,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pa WHERE pa.OwnerUserId = u.Id AND pa.PostTypeId = 2) AS a_count
FROM dbo.Users AS u
WHERE u.Reputation >= 25000
ORDER BY u.Id;
It’s simplified a bit from what I ran into, but it does the job.
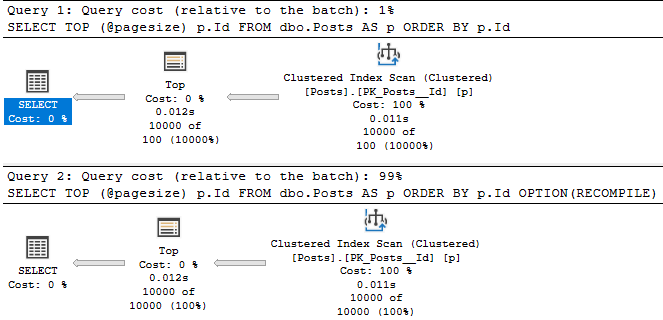
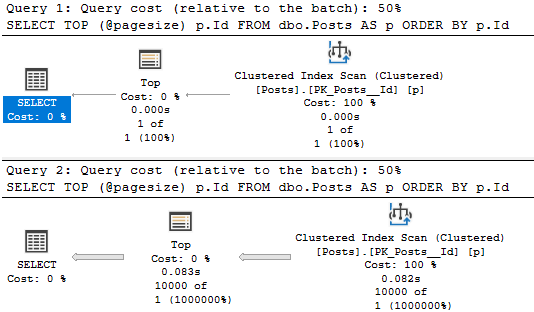
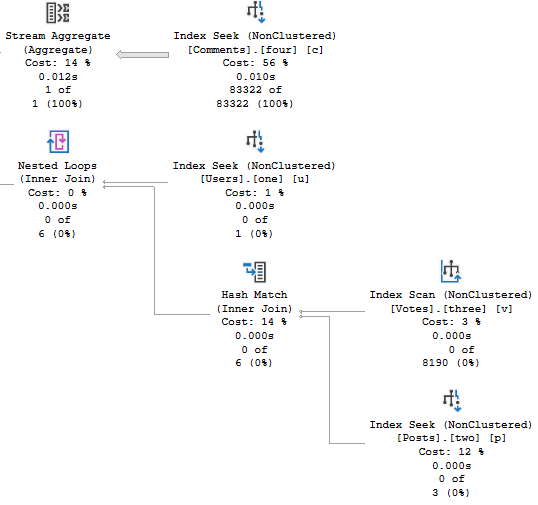
Batchy
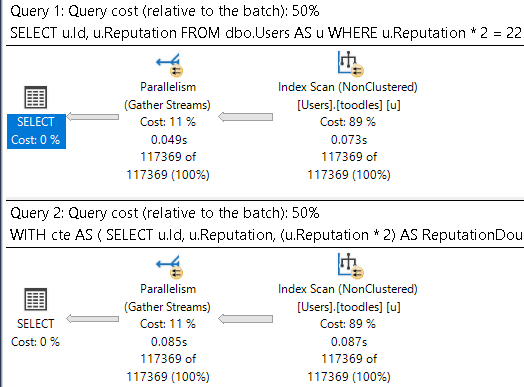
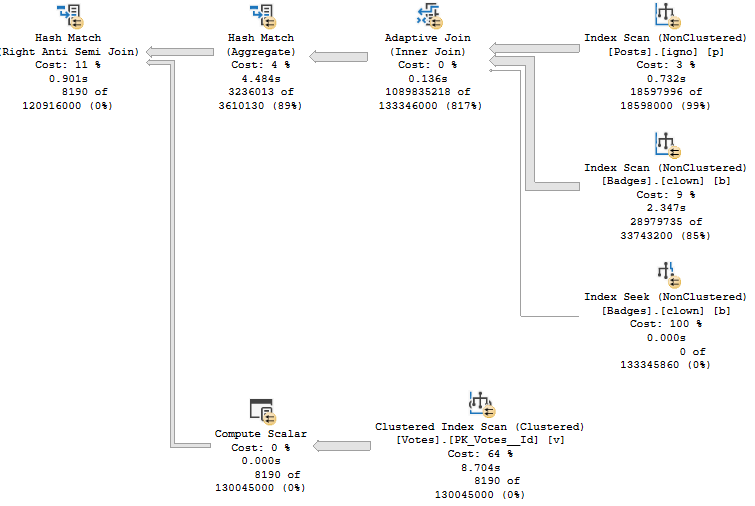
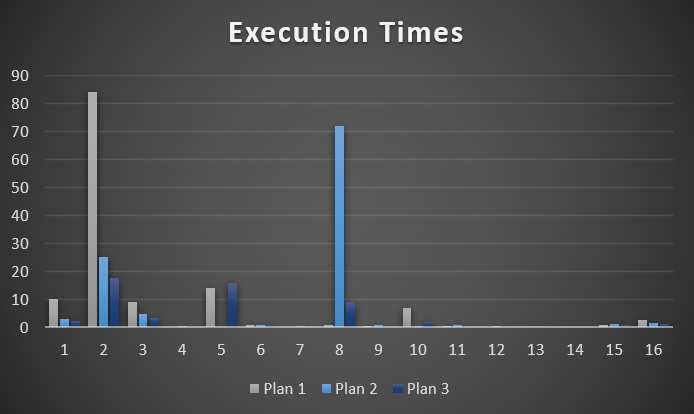
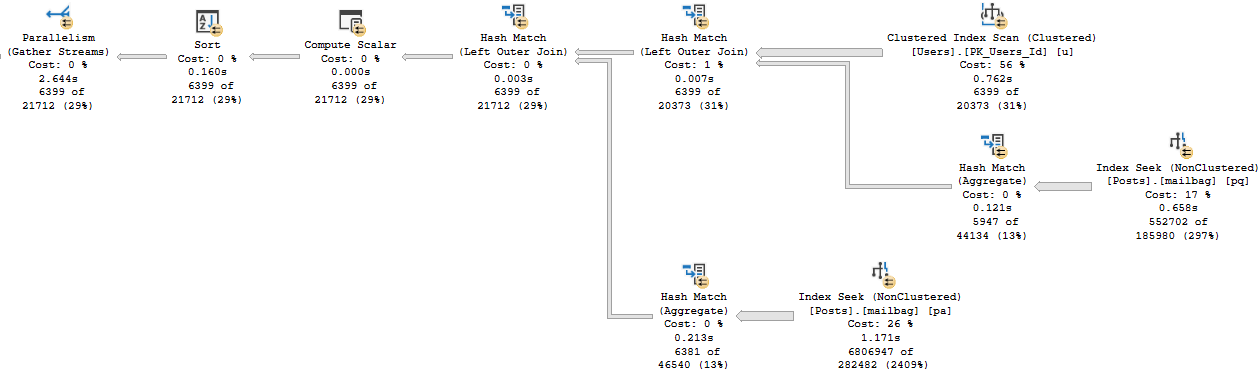
This is the batch mode query plan. It runs for about 2.6 seconds.
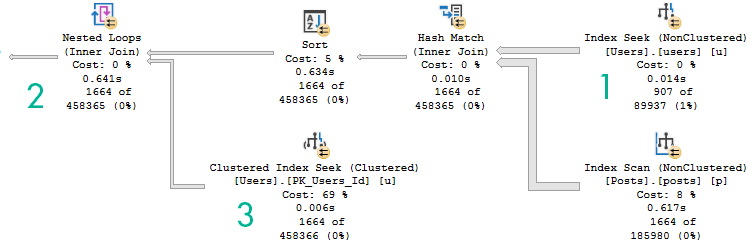
Rowy
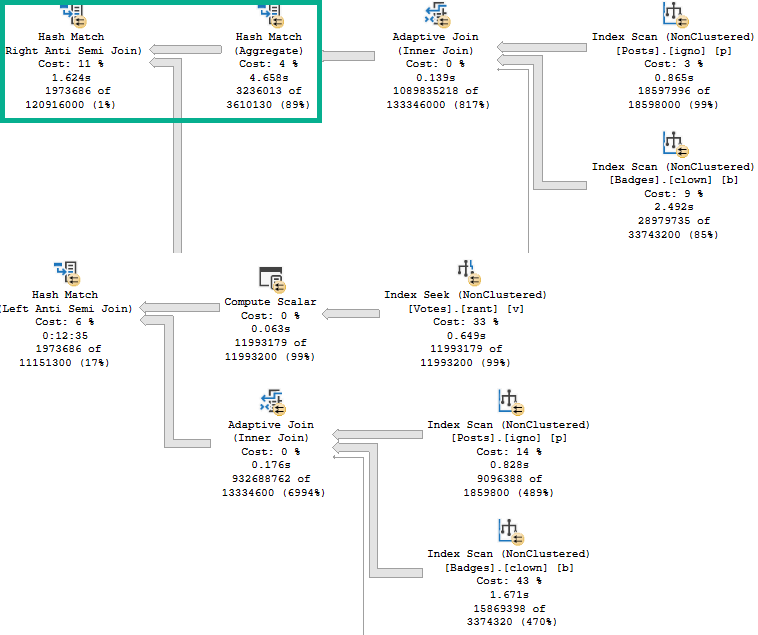
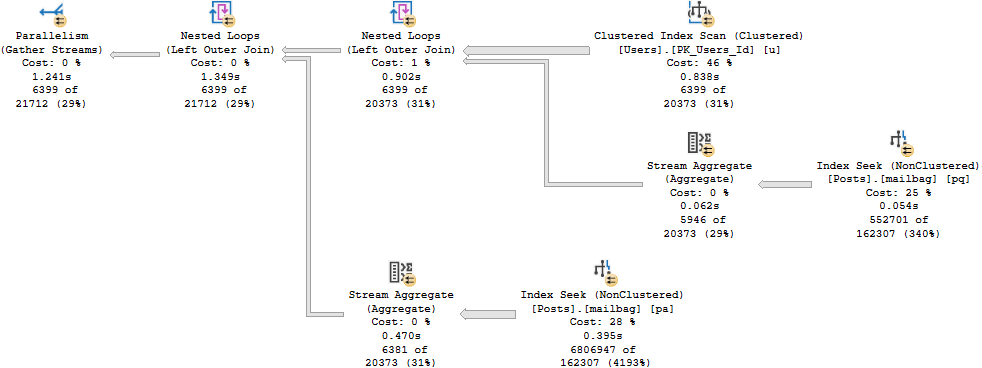
And here’s the row mode query plan. It runs for about 1.3 seconds.
What Happened?
Just when you think the future is always faster, life comes at you like this.
So why is the oldmode query more than 2x faster than the newhotmode query?
There are a reason, and it’s not very sexy.
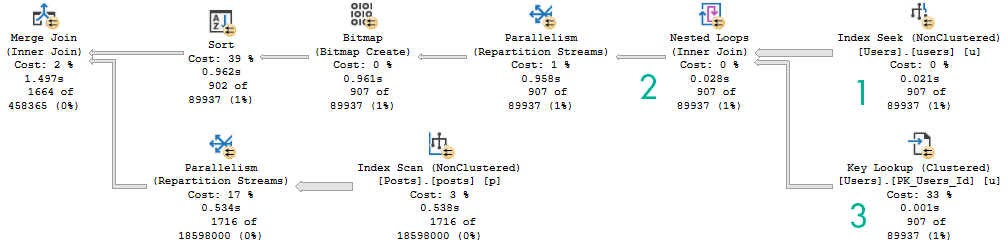
Batch Like That
First, the hash joins produce Bitmaps.
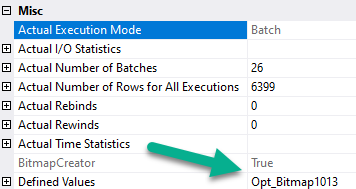
You don’t see Bitmaps in Batch Mode plans as operators like you’re used to in Row Mode plans. You have to look at the properties (not the tool tip) of the Hash Join operator.
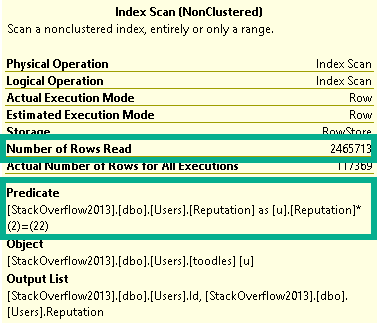
Even though both plans seek into the index on Posts, it’s only for the PostTypeId in the Batch Mode plan.
It would be boring to show you both, so I’m just going to use the details from the branch where we find PostTypeId = 2.
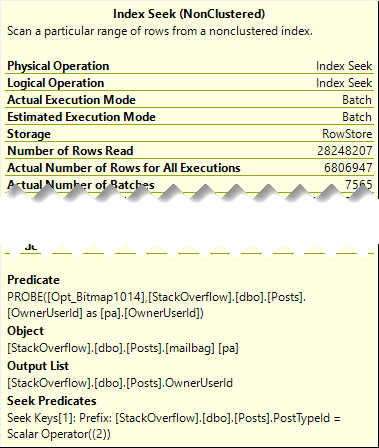
Remember this pattern: we seek to all the values where PostTypeId = 2, and then apply the Bitmap as a residual predicate.
You can pretty easily mentally picture that.
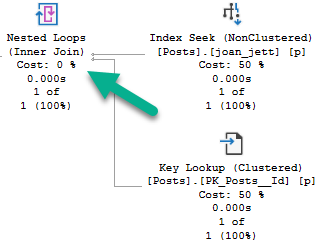
Rowbot
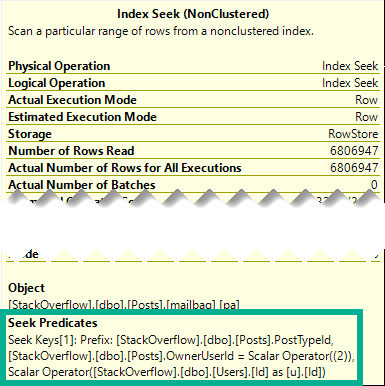
In the row mode plan, the Nested Loops Joins are transformed to Apply Nested Loops:

Which means on the inner side of the join, both the PostTypeId and the OwnerUserId qualify as seek predicates:
Reading Rainbow
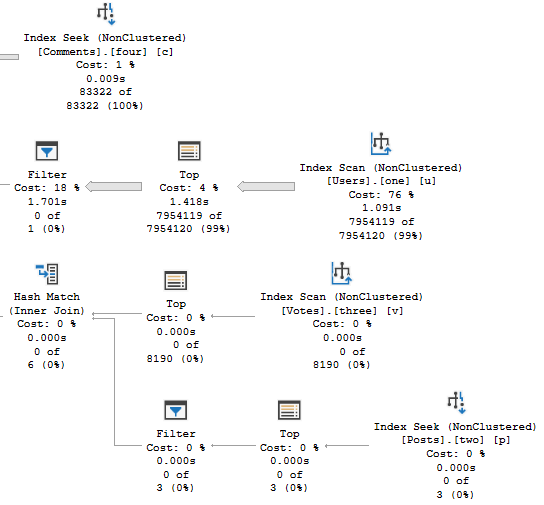
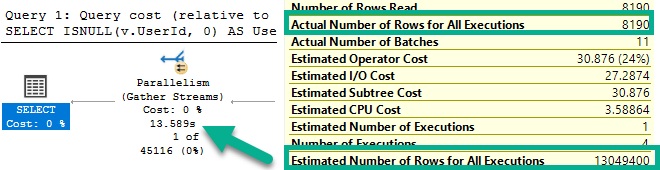
The better performance comes from doing fewer reads when indexes are accessed.
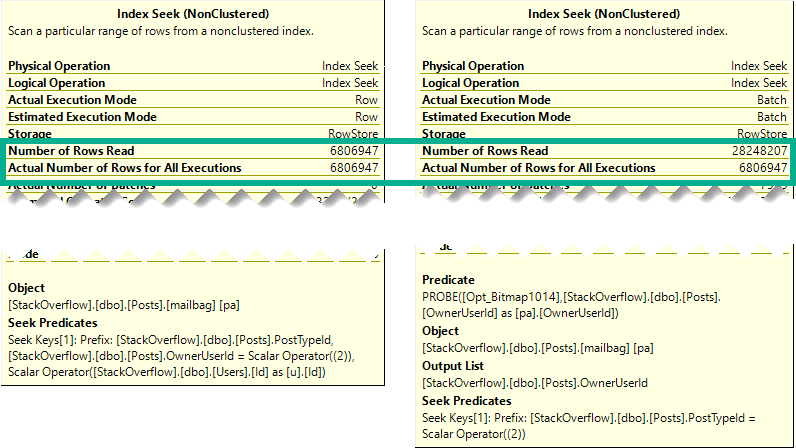
Though both produce the same number of rows, the Hash Join plan in Batch Mode reads 28 million rows, or about 21 million more rows than the Nested Loop Join plan in row mode. In this case, the double seek does far fewer reads, and even Batch Mode can’t cover that up.
Part of the problem is that the optimizer isn’t psychic.
Fixing It
There are two ways I found to get the Nested Loop Join plan back.
The boring one, using a compat level hint:
SELECT u.Id, u.DisplayName, u.Reputation,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pq WHERE pq.OwnerUserId = u.Id AND pq.PostTypeId = 1) AS q_count,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pa WHERE pa.OwnerUserId = u.Id AND pa.PostTypeId = 2) AS a_count
FROM dbo.Users AS u
WHERE u.Reputation >= 25000
ORDER BY u.Id
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
And the more fun one, rewriting the correlated subqueries as outer apply:
SELECT u.Id, u.DisplayName, u.Reputation, q_count, a_count
FROM dbo.Users AS u
OUTER APPLY(SELECT COUNT_BIG(*) AS q_count FROM dbo.Posts AS pq WHERE pq.OwnerUserId = u.Id AND pq.PostTypeId = 1) AS q_count
OUTER APPLY(SELECT COUNT_BIG(*) AS a_count FROM dbo.Posts AS pa WHERE pa.OwnerUserId = u.Id AND pa.PostTypeId = 2) AS a_count
WHERE u.Reputation >= 25000
ORDER BY u.Id;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.