I Won’t Share You
Yesterday we looked at where table variables can have a surprising! impact on performance. We’ll talk more about them later, because that’s not the only way they can stink. Not by a long shot. Even with 1 row in them.
Anyway, look, today’s post is sort of like yesterday’s post, except I’ve had two more drinks.
What people seem to miss about scalar valued functions is that there’s no distinction between ones that touch data and ones that don’t. That might be some confusion with CLR UDFs, which cause parallelism issues when they access data.
Beans and Beans
What I want to show you in this post is that it doesn’t matter if your scalar functions touch data or not, they’ll still have similar performance implications to the queries that call them.
Now look, this might not always matter. You could just use a UDF to assign a value to a variable, or you could call it in the context of a query that doesn’t do much work anyway. That’s probably fine.
But if you’re reading this and you have a query that’s running slow and calling a UDF, it just might be why.
- If the UDF queries table data and is inefficient
- If the UDF forces the outer query to run serially
They can be especially difficult on reporting type queries. On top of forcing them to run serially, the functions also run once per row, unlike inline-able constructs.
Granted, this once-per-row thing is worse for UDFs that touch data, because they’re more likely to encounter the slings and arrows of relational data. The reads could be blocked, or the query in the function body could be inefficient for a dozen reasons. Or whatever.
I’m Not Touching You
Here’s a function that doesn’t touch anything at all.
CREATE OR ALTER FUNCTION dbo.little_function (@UserId INT)
RETURNS BIGINT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @d DATETIME = GETDATE();
RETURN
(
(
SELECT @UserId
)
)
END
GO
I have the declared variable in there set to GETDATE() to disable UDF inlining in SQL Server 2019.
Yes, I know there’s a function definition to do the same thing, but I want you to see just how fragile a feature it is right now. Again, I love where it’s going, but it can’t solve every single UDF problem.
Anyway, back to the story! Let’s call that function that doesn’t do anything in our query.
SELECT TOP (1000)
c.Id,
dbo.little_function(c.UserId)
FROM dbo.Comments AS c
ORDER BY c.Score DESC;
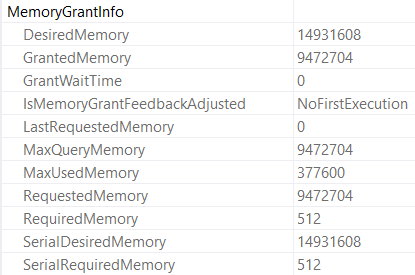
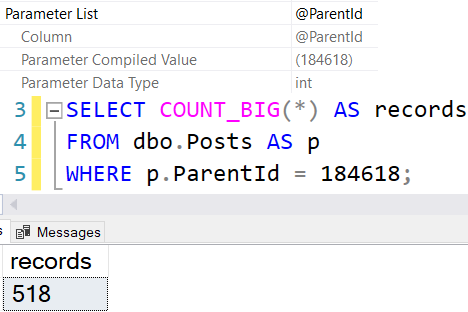
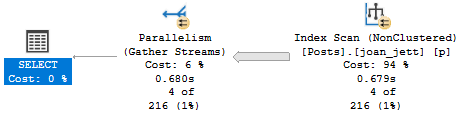
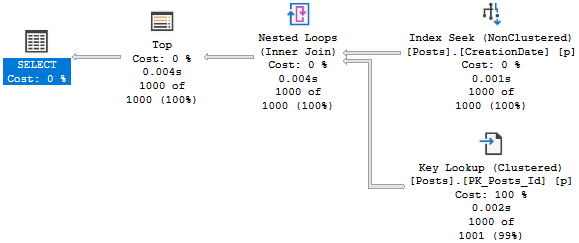
The query plan looks like so, with the warning in properties about not being able to generate a valid parallel plan.

In this plan, we see the same slowdown as the insert to the table variable. There’s no significant overhead from the function, it’s just slower in this case because the query is forced to run serially by the function.
This is because of the presence of a scalar UDF, which can’t be inlined in 2019. The serial plan represents, again, a significant slowdown over the parallel plan.
Bu-bu-bu-but wait it gets worse
Let’s look at a worse function.
CREATE OR ALTER FUNCTION dbo.big_function (@UserId INT)
RETURNS BIGINT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @d DATETIME = GETDATE();
RETURN
(
(
SELECT SUM(p.Score)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
) -
(
SELECT SUM(c.Score)
FROM dbo.Comments AS c
WHERE c.UserId = @UserId
)
)
END
GO
Not worse because it’s a different kind of function, just worse because it goes out and touches tables that don’t have any helpful indexes.
Getting to the point, if there were helpful indexes on the tables referenced in the function, performance wouldn’t behave as terribly. I’m intentionally leaving it without indexes to show you a couple funny things though.
Because this will run a very long time with a top 1000, I’m gonna shorten it to a top 1.
SELECT TOP (1)
c.Id,
dbo.big_function(c.UserId)
FROM dbo.Comments AS c
ORDER BY c.Score DESC;
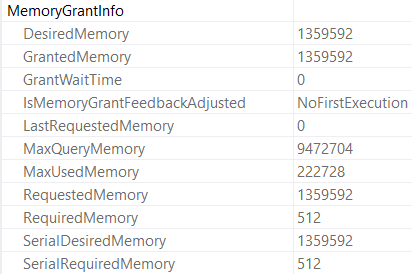
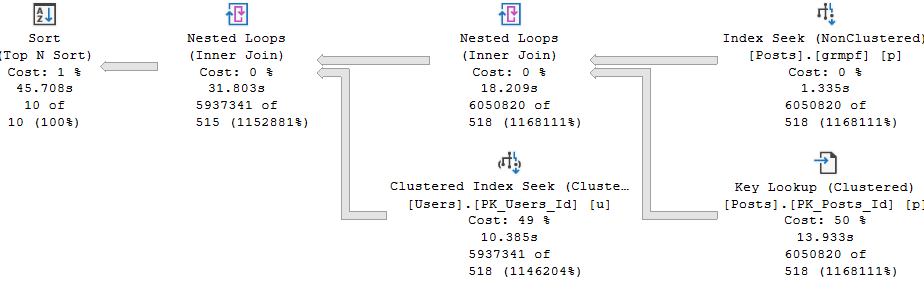
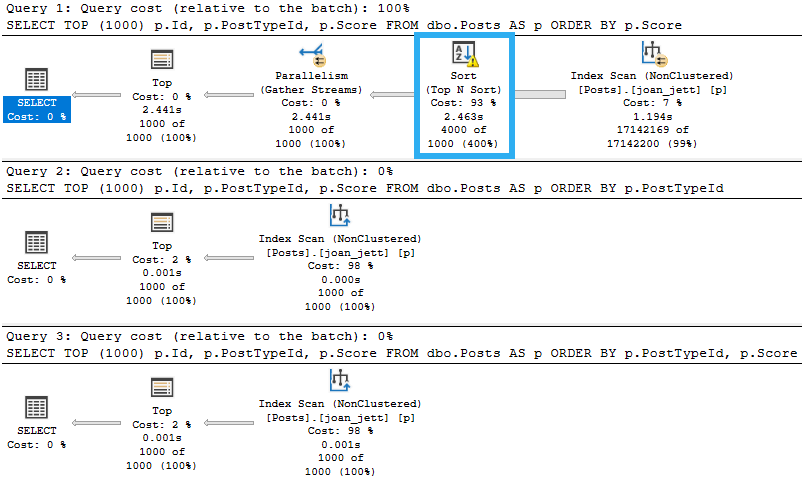
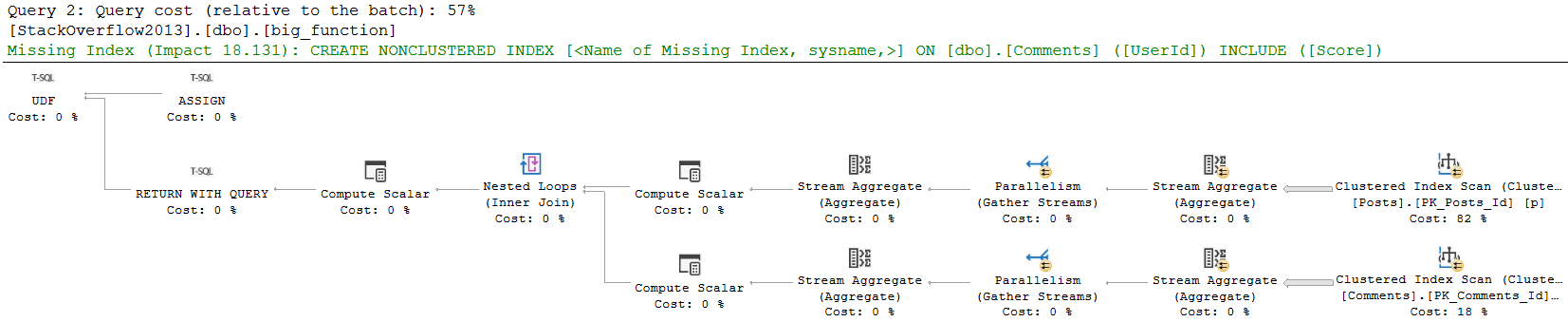
Notice that in this plan, the compute scalar takes up a more significant portion of query execution time. We don’t see what the compute scalar does, or what the function itself does in the actual query plan.

The compute scalar operator is what’s responsible for the scalar UDF being executed. In this case, it’s just once. If I had a top that asked for more than one row, It would be responsible for more executions.
We don’t see the function’s query plan in the actual query, because it could generate a different query plan on each execution. Would you really want to see 1000 different query plans?
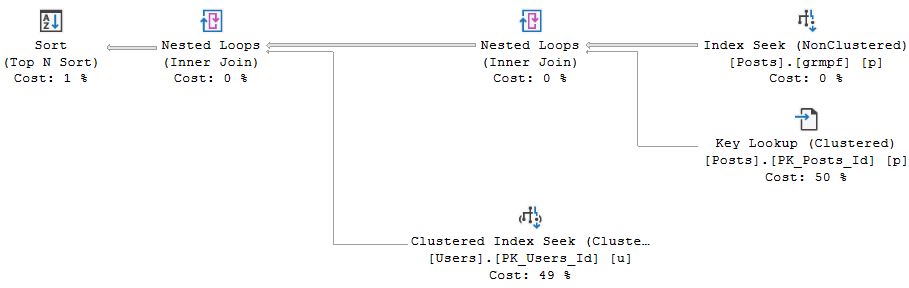
Anyway, it’s quite easy to observe with operator times where time is spent here. Most people read query plans from right to left, and that’s not wrong.
In that same spirit, we can add operator times up going from right to left. Each operator not only account for its own time, but for the time of all operators that come before it.
The clustered index scan takes 7.5 seconds, the Sort takes 3.3 seconds, and the compute scalar takes 24.9 seconds. Wee.
Step Inside
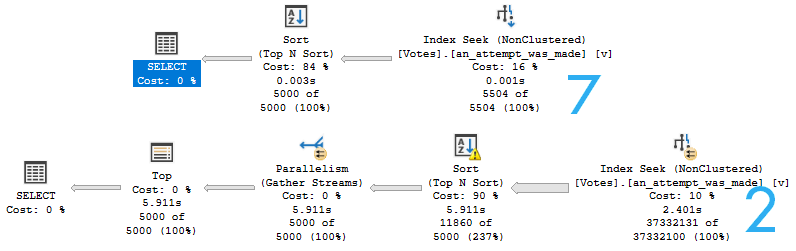
If you get an actual plan for this query, you won’t see what the function does. If you get an estimated plan, you can get a picture of what the function is up to.
This is what I meant by the function body being allowed to go parallel. This may lead to additional confusion when the calling query accrues parallel query waits but shows no parallel operators, and has a warning that a parallel plan couldn’t be generated.

It’s Not As Funny As It Sounds
If you look at a query plan’s properties and see a non-parallel plan reason, table variable modifications and scalar UDFs will be the most typical cause. They may not always be the cause of your query’s performance issues, and there are certainly many other local factors to consider.
It’s all a bit like a game of Clue. You might find the same body in the same room with the same bashed in head, but different people and blunt instruments may have caused the final trauma.
Morbid a bit, sure, but if query tuning were always a paint by numbers, no one would stay interested.
Anyway.
In the next posts? we’ll look at when SQL Server tells you it needs an index, and when it doesn’t.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.