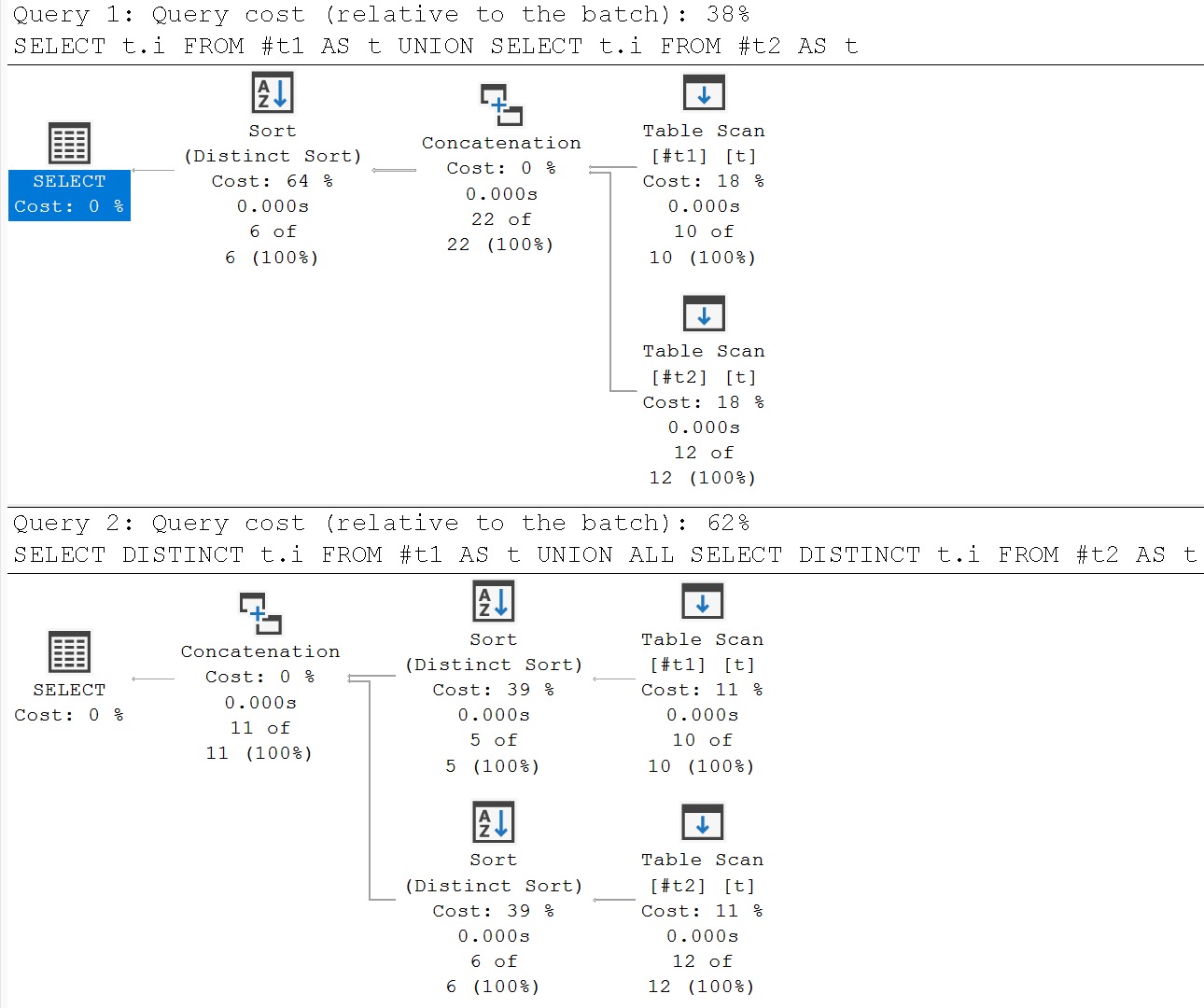
Who Am I Kidding?
I have never once seen anyone use these. The most glaring issue with them is that unlike a lot of other directives in SQL, these ones just don’t do a good job of telling you what they do, and their behavior is sort of weird.
Unlike EXISTS and NOT EXISTS, which state their case very plainly, as do UNION and UNION ALL, figuring these out is not the most straightforward thing. Especially since INTERSECT has operator precedence rules that many other directives do not.
- INTERSECT gives you a set of unique rows from both queries
- EXCEPT gives you a set of unique rows from the “first” query
So, cool, if you know you want a unique set of rows from somewhere, these are good places to start.
What’s better, is that they handle NULL values without a lot of overly-protective syntax with ISNULL, COALESCE, or expansive and confusing OR logic.
The tricky part is spotting when you should use these things, and how to write a query that makes the most of them.
And in what order.
Easy Examples
Often the best way to get a feel for how things work is to run simple queries and test the results vs. your expectations, whatever they may be.
I like these queries, because the UserId column in the Comments table is not only NULLable, but contains actual NULLs. Wild, right?
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 2
INTERSECT
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 3
ORDER BY
c.Score;
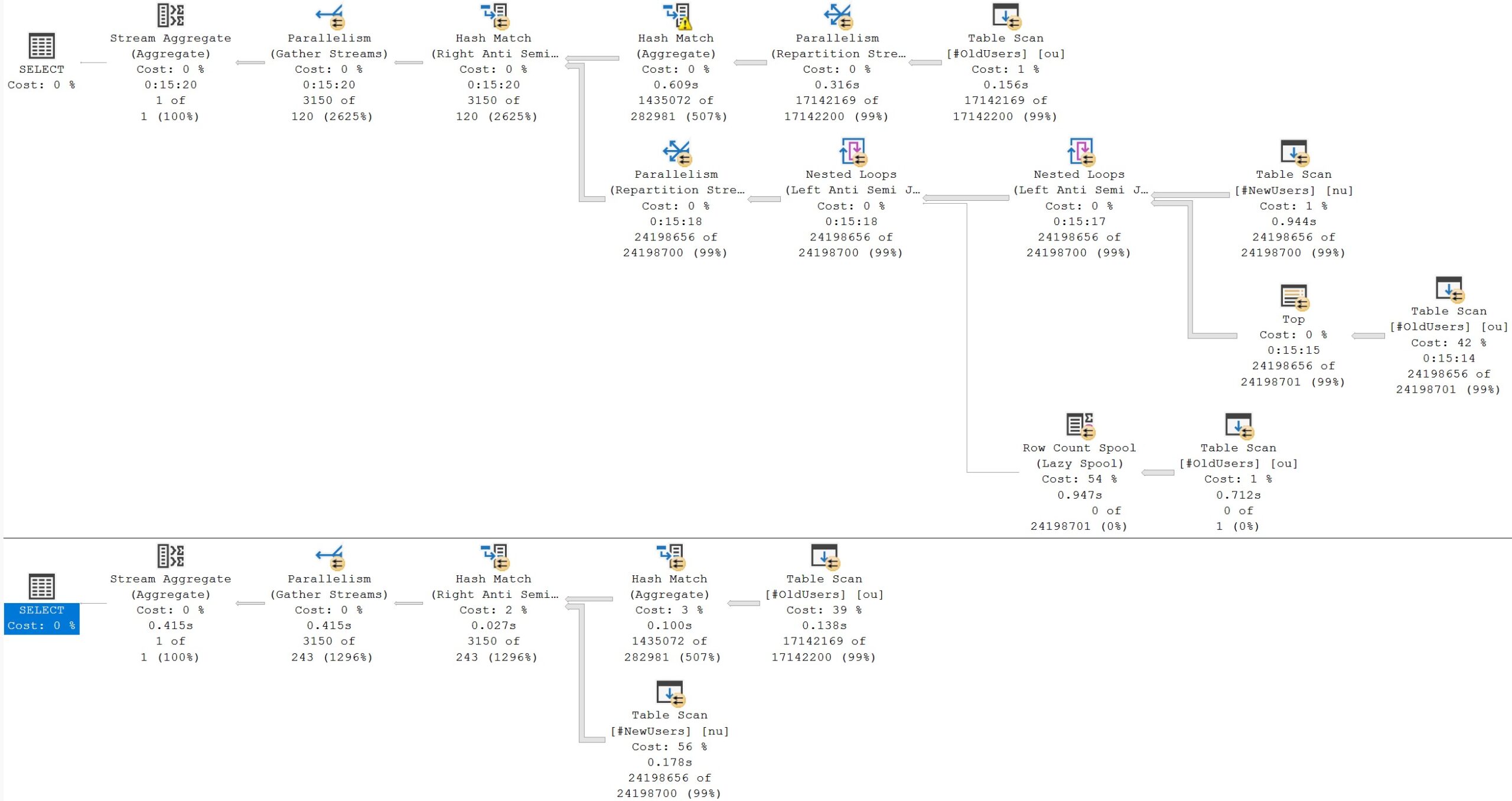
Running this will return results where a Comment’s Score is greater than 3 only, because that’s the starting point for where both query results begin to match results across all the columns.
Note that the UserId column being NULL doesn’t pose any problems here, and doesn’t require any special handling. Like I said. And will keep saying. Please remember what I say, I beg of you.
Moving on to EXCEPT:
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 2
EXCEPT
SELECT
c.*
FROM dbo.Comments AS c
WHERE c.UserId IS NULL
AND c.Score > 3
ORDER BY
c.Score;
This will only return results from the “first” query (often referred to as the left, or outer query) with a Score of 3, because that’s the only data that exists in it that isn’t also in the “second” (or right, or inner) query.
Both queries will find many of the same rows after Score hits 2 or 3, but those get filtered out to show only the difference(s) between the two.
In case it wasn’t obvious, it’s a bit like using NOT EXISTS, in that rows are only checked, and not projected from the second/right/inner query, looking for Scores greater than 3.
Again, NULLs in the UserId column are handled just fine. No ISNULL/COALESCE/OR gymnastics required.
I’m really trying to drive this home, here.
In The Year 2000
SQL Server 2022 introduced some “modern” ANSI syntax. By modern, I mean that IS DISTINCT FROM was introduced to the standard in 1999, and IS NOT DISTINCT FROM was introduced in 2003.
While no database platform adheres strictly or urgently to ANSI standards, waiting 20 years for an implementation in SQL Server is kind of really-extra-super-duper son-of-a-gun boy-howdy dag-nabbit-buster alright-bucko hold-your-horses listen-here-pal levels of irritating.
Think of all the useless, deprecated, and retired things we’ve gotten in the past 20 years instead of basic functionality. It’s infinitely miffing.
Anyway, I like these additions quite a lot. In many ways, these are extensions of INTERSECT and EXCEPT, because the workarounds involved for them involved those very directives. Sort of like Microsoft finally adding GREATEST and LEAST, after decades of developers wondering just what the hell to do instead, I hope they didn’t show up too late to keep SQL Server from being bullied by developers who are used to other platforms.
We can finally start to replace mutton-headed, ill-performing syntax like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.LastEditorUserId
OR (p.LastEditorUserId IS NULL);
With stuff that doesn’t suck, like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id IS NOT DISTINCT FROM p.LastEditorUserId;
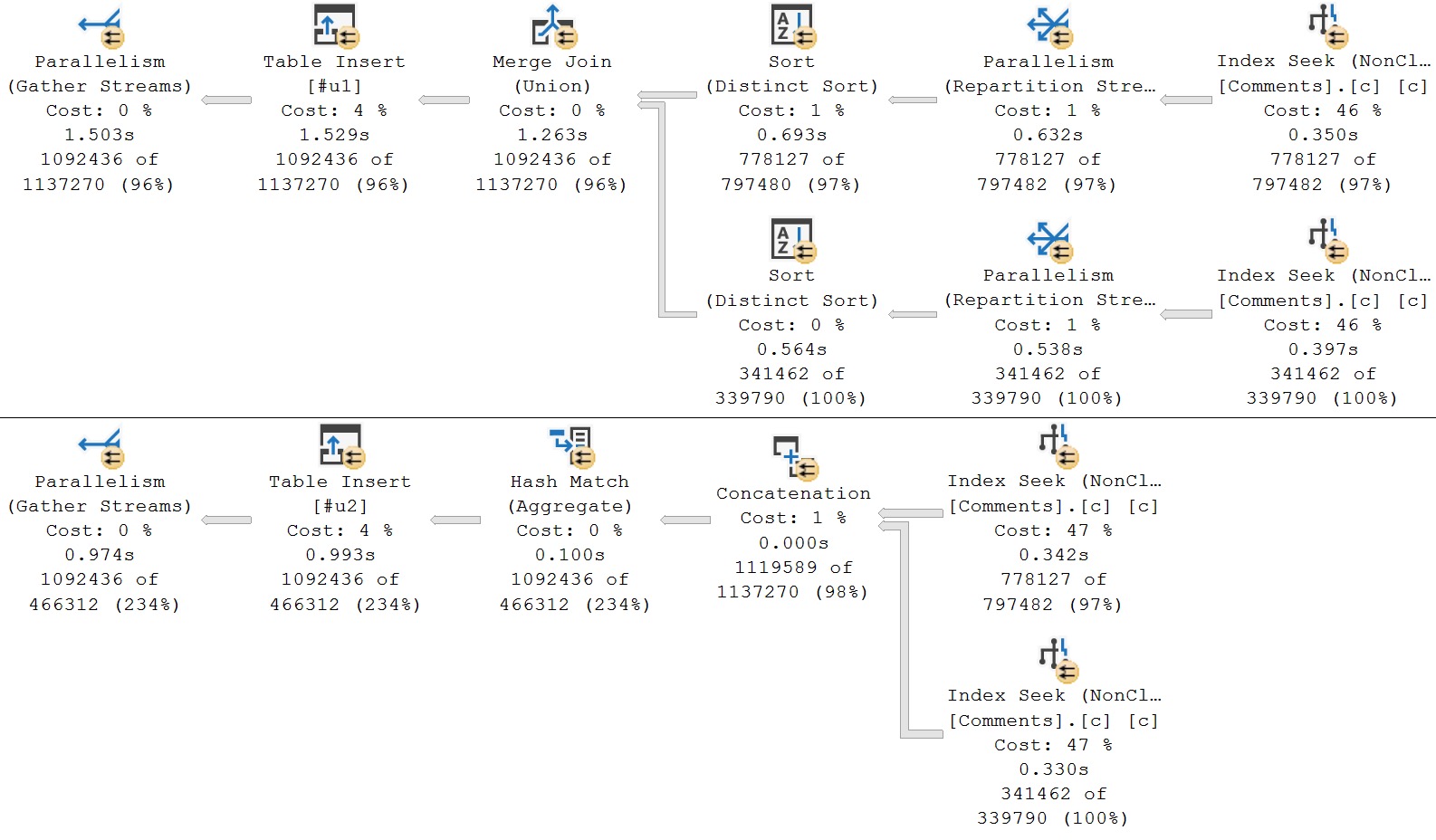
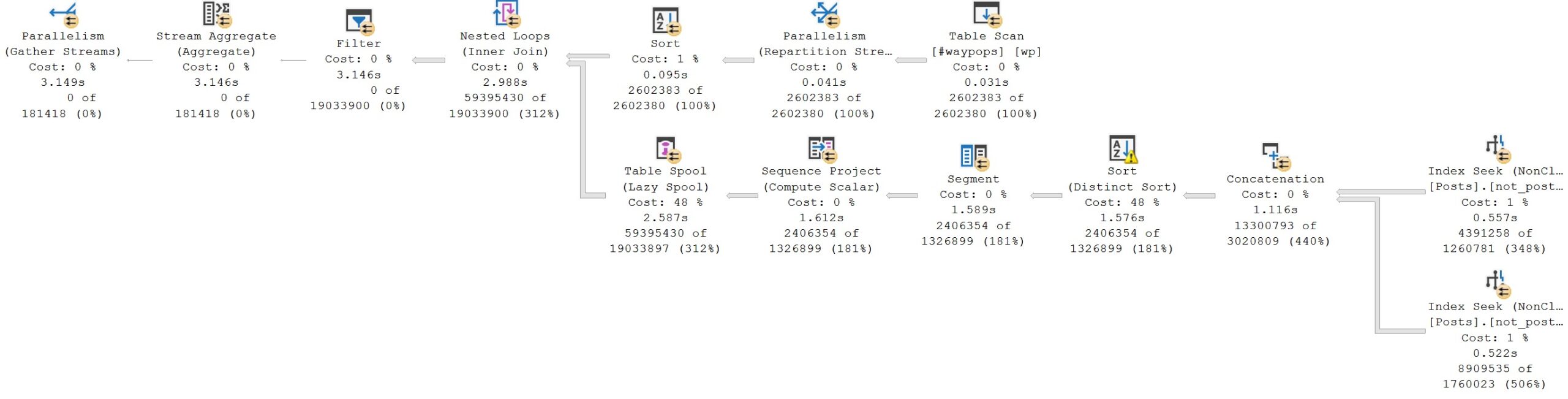
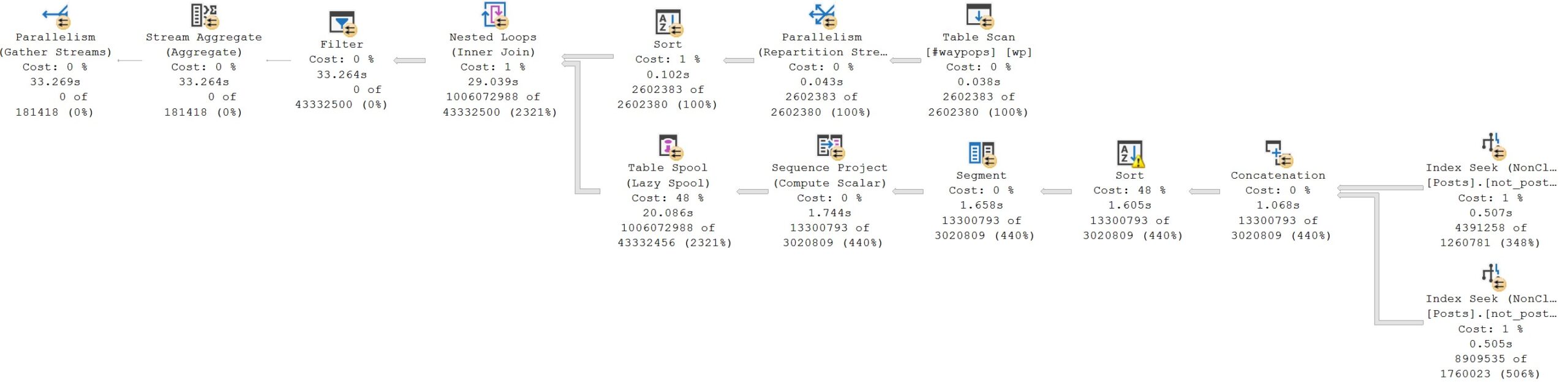
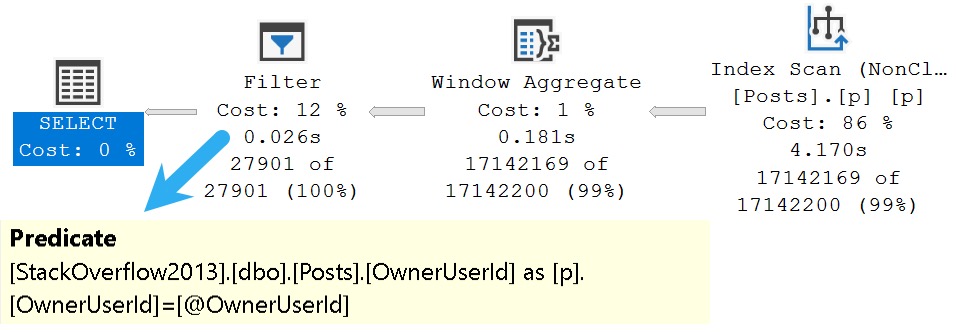
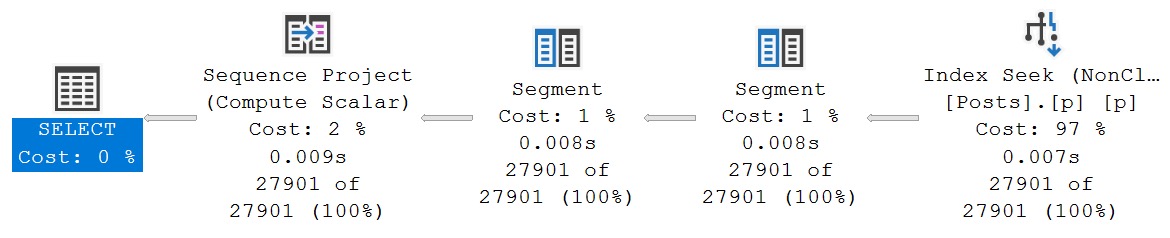
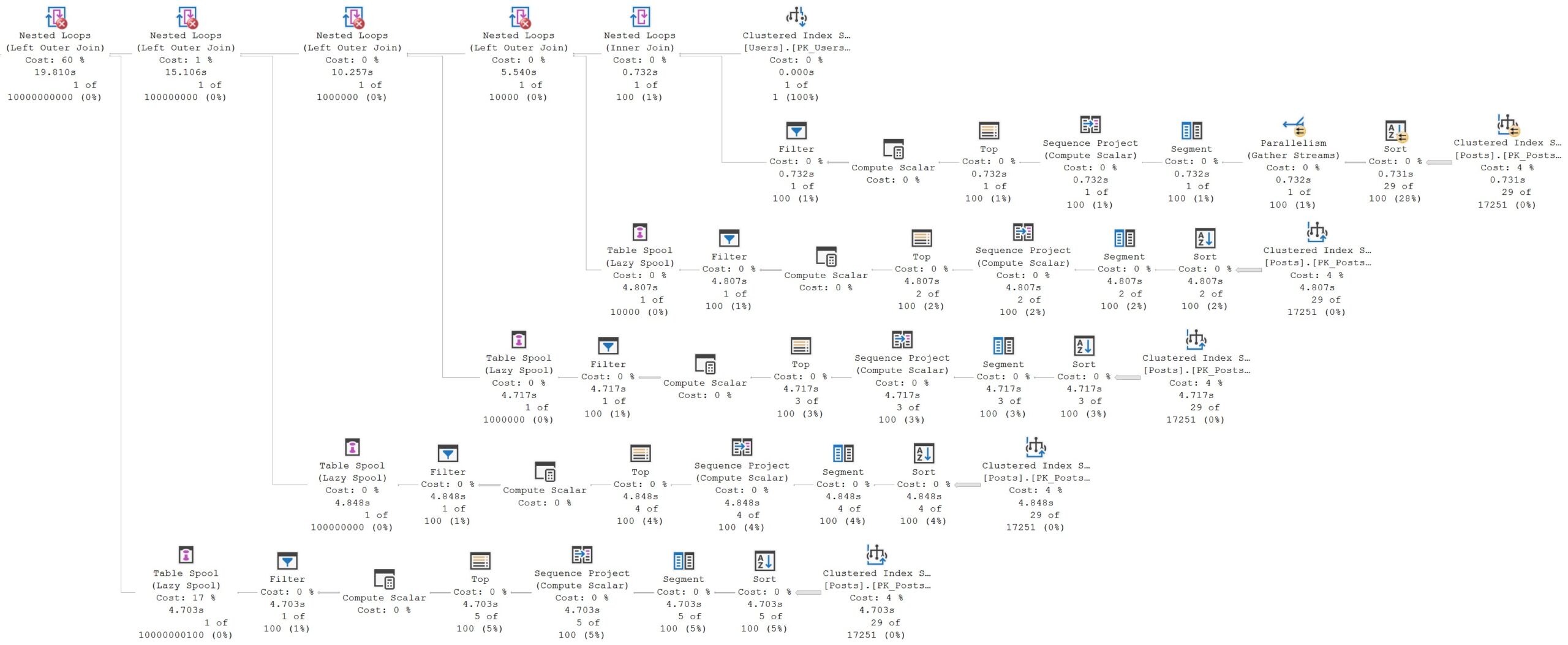
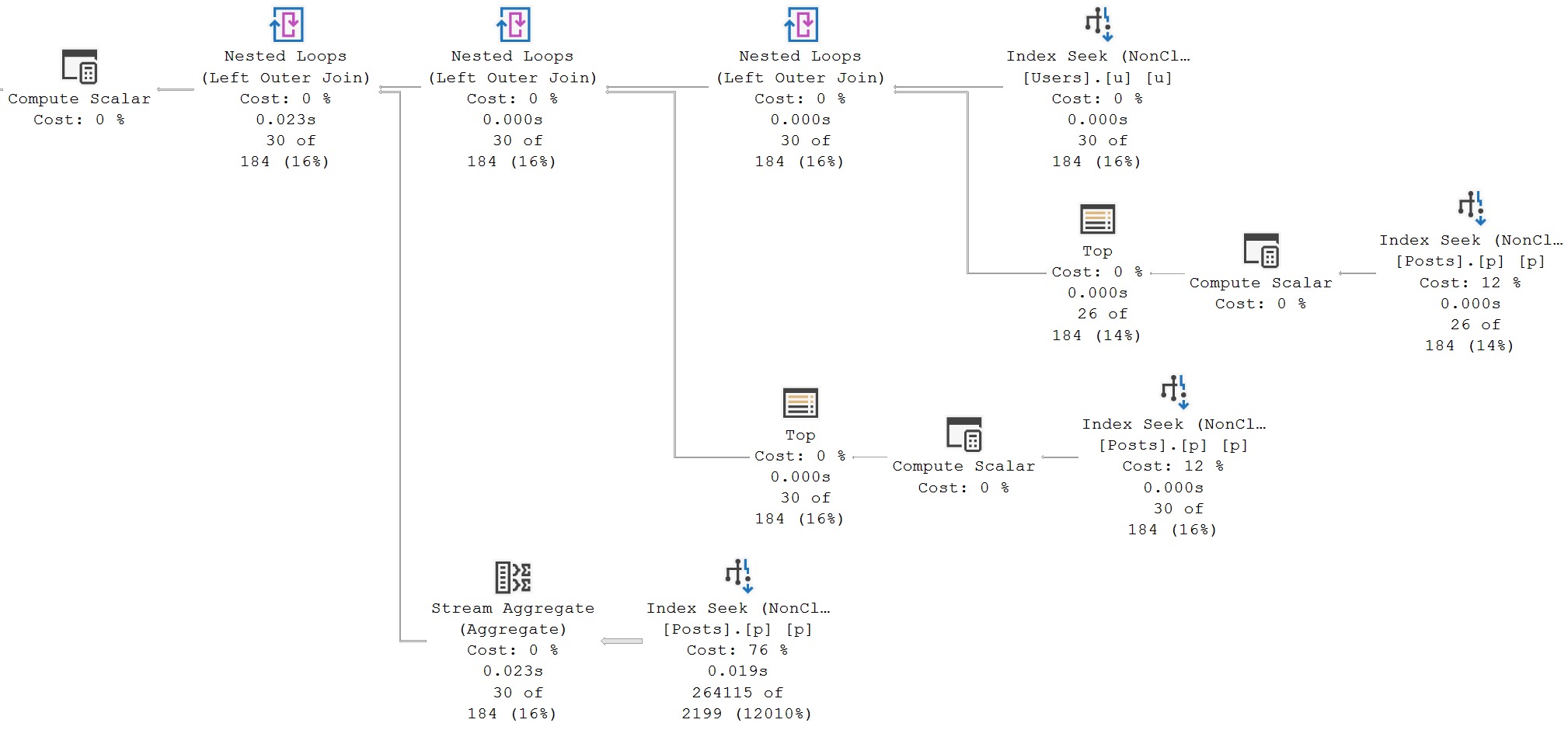
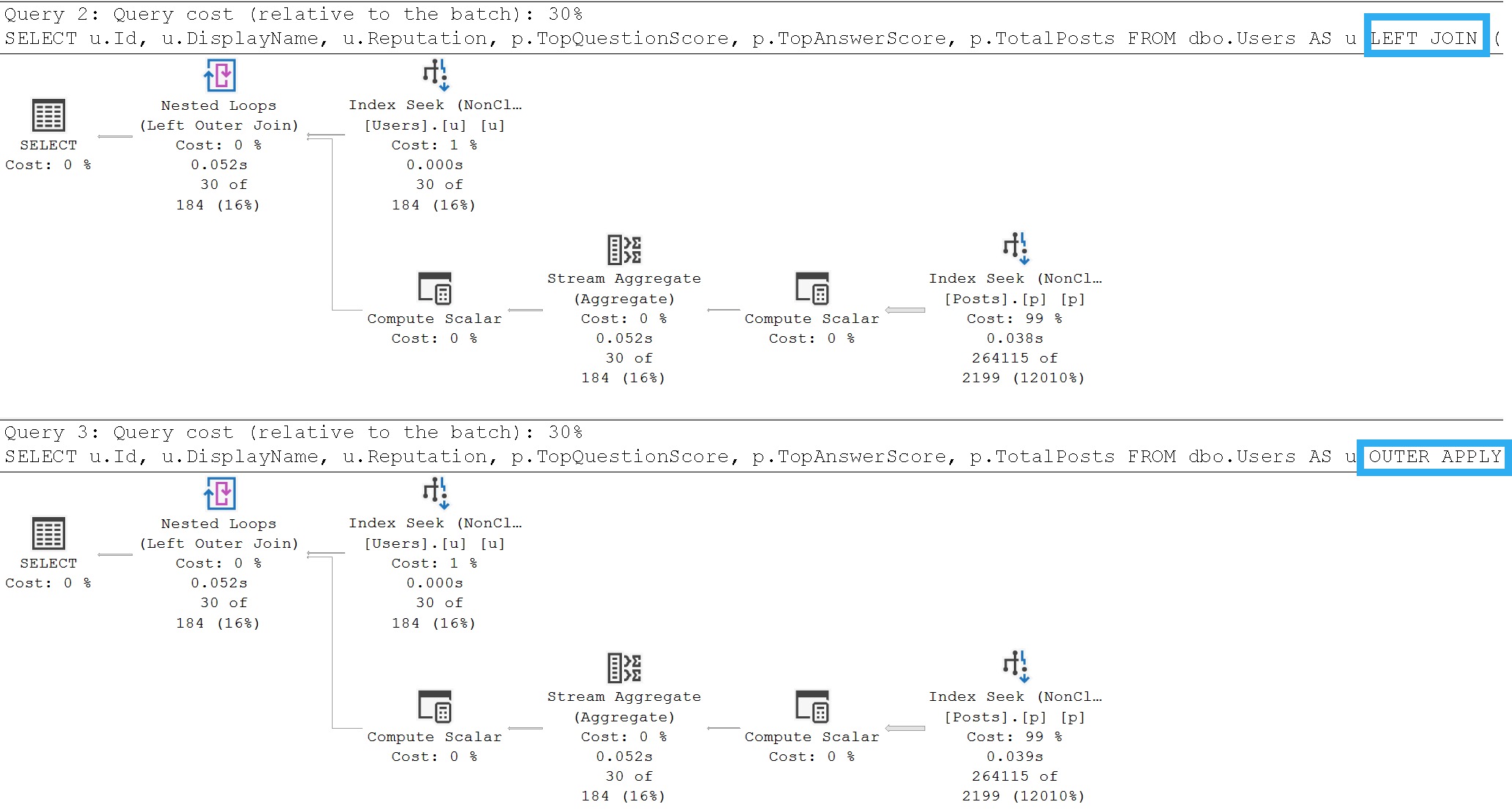
The query plan timings tell enough of a story here:

But not everyone is able to use the latest and greatest (or least and greatest, ha ha ha) syntax. And the newest syntax isn’t always better for performance, without additional tweaks.
And that’s okay with me. I do performance tuning for a living, and my job is to know all the available options and test them.
Like here. Like now.
The Only One I Know
Let’s compare these two queries. It’ll be fun, and if you don’t think it’s fun, that’s why you’ll pay me. Hopefully.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id IS NOT DISTINCT FROM p.LastEditorUserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.LastEditorUserId
WHERE EXISTS
(
SELECT p.LastEditorUserId FROM dbo.Posts AS p
INTERSECT
SELECT u.Id FROM dbo.Users AS u
);
Here’s the supporting index that I have for these queries:
CREATE INDEX
LastEditorUserId
ON dbo.Posts
(LastEditorUserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
It’s good enough. That’s what counts, I guess. Showing up.
20th Century Boy
At first glance, many queries may appear to be quite astoundingly better. SQL Server has many tricks up its sleeves in newer versions, assuming that you’re ready to embrace higher compatibility levels, and pay through the nose for Enterprise Edition.
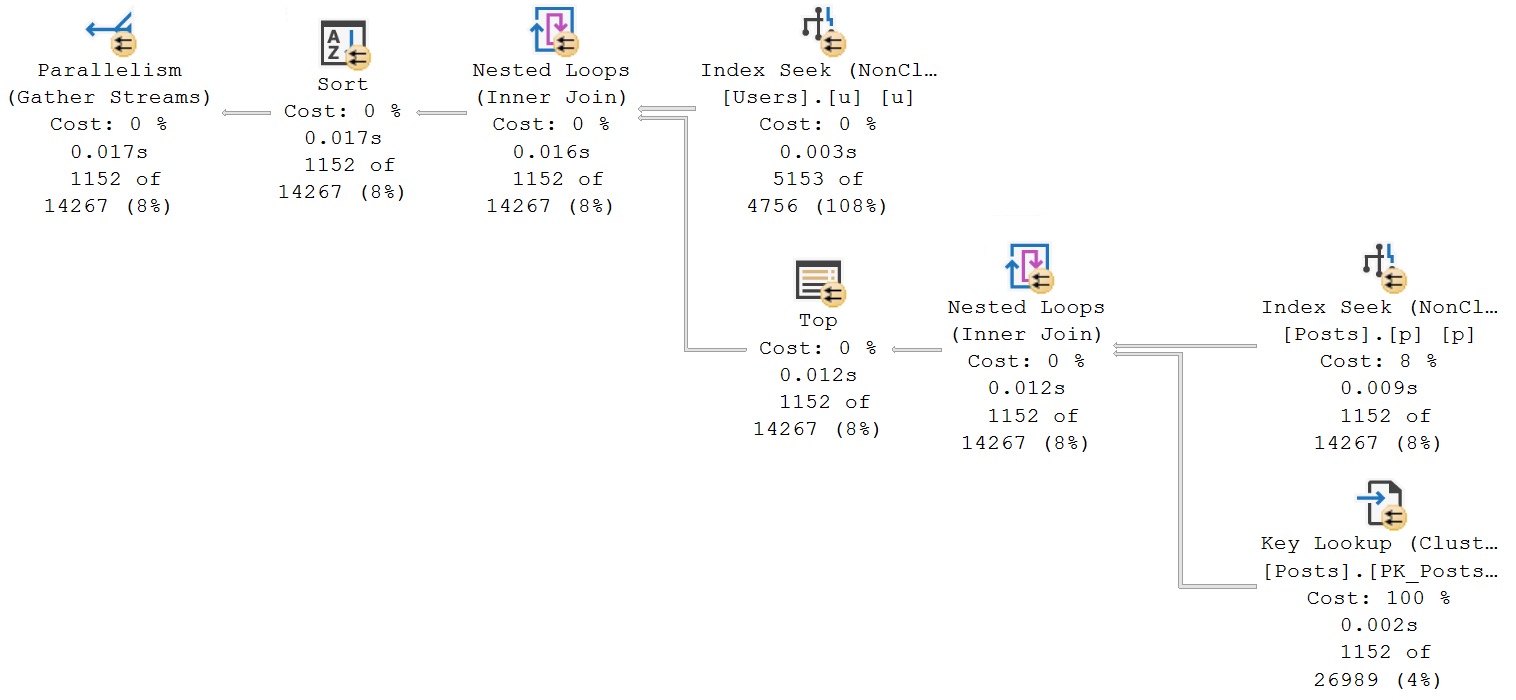
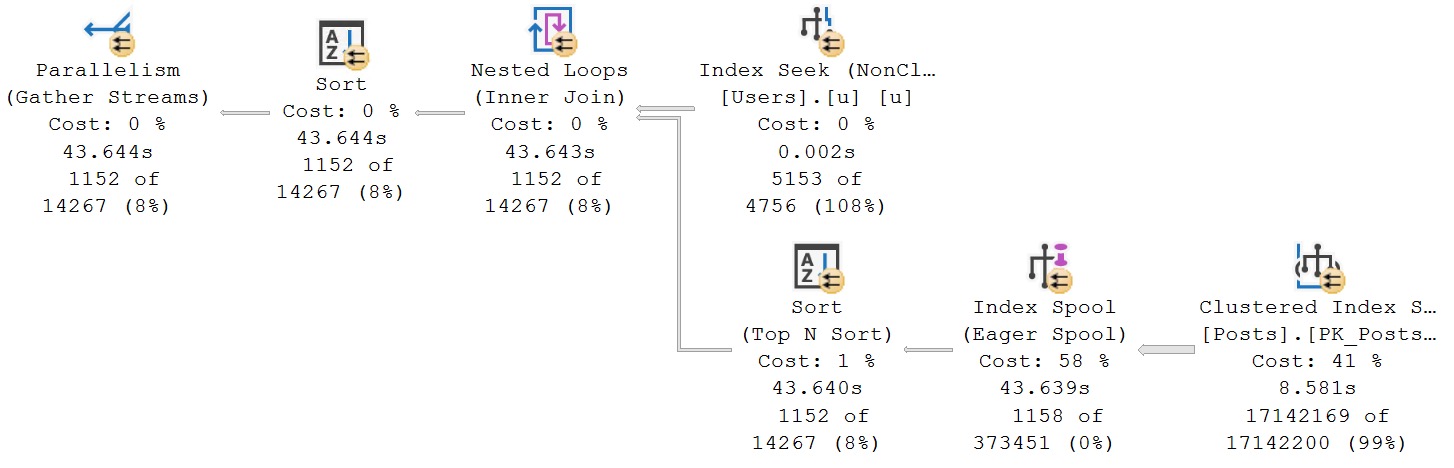
This is a great example. Looking at the final query timing, you might think that the new IS [NOT] DISTINCT FROM syntax is a real dumb dumb head.

But unless you’re invested in examining these types of things, you’ll miss subtle query plan difference, which is why you’ll pay me, hopefully,
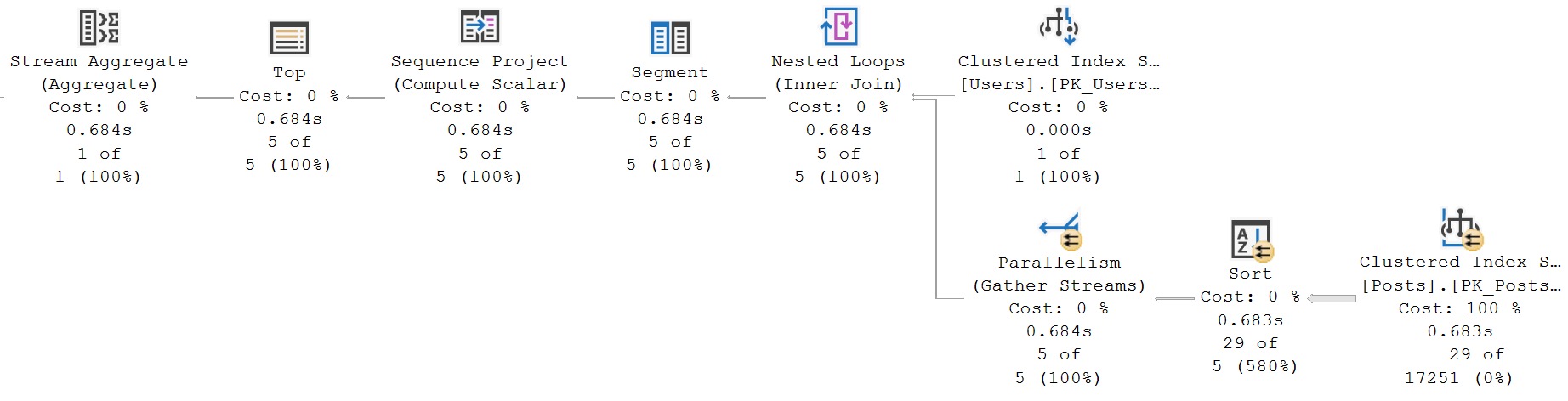
The second query receives the blessing of Batch Mode On Row Store, while the first does not. If we use the a helper object to get them both functioning on even terms, performance is quite close:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id IS NOT DISTINCT FROM p.LastEditorUserId
LEFT JOIN dbo.columnstore_helper AS ch
ON 1 = 0;

In this case, the slightly tweaked query just slightly edges out the older version of writing the query.
I Can’t Imagine The World Without Me
There are many ways to write a query, and examine the performance characteristics. As SQL Server adds more options, syntax, capabilities, and considerations, testing and judging them all (especially with various indexing strategies) becomes quite an endeavor.
I don’t blame developers for being unaware or, or unable to test a variety of different rewrites and scenarios. The level of understanding that it takes to tune many queries extends quite beyond common knowledge or sense.
The aim of these posts is to give developers a wider array of techniques, and a better understanding of what works and why, while exposing them to newer options available as upgrade cycles march bravely into the future.
Keeping up with SQL Server isn’t exactly a full time job. Things are changed and added from release to release, which are years apart.
But quite often I find companies full of people struggling to understand basic concepts, troubleshooting, and remediations that are nearly as old as patches for Y2K bugs.
My rates are reasonable, etc.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.