Are You Sure You’re Sure?
UNION and UNION ALL seem to get used with the same lack of discretion and testing as several other things in T-SQL: CTEs vs temp tables, temp tables vs. table variables, etc.
There are many times I’ve seen developers use UNION when result sets have no chance of being non-unique anyway, and many times I’ve seen them use UNION ALL when there would be a great benefit to discarding unnecessary duplicates.
Even worse is when the whole query is written incorrectly in the first place, and both DISTINCT and UNION are dumped all over queries to account for unwanted results across the board.
For example, someone may test a query in isolation, decide that DISTINCT needs to be applied to that result set, and then use UNION when appending another set of results to the final query. Throw in the typical slew of NOLOCK hints and one is left to wonder if anyone even understands what correct output might look like at all.
The answer to most questions about the correct way to write a query of course hinge on the quality of the underlying data, and any observed flaws reported by end users or QA testers.
This all becomes quite difficult to wade through, because developers may understand the correct logic, but not the correct way to implement it.
Just An Onion
To start, let’s flesh out what each operator means in the most basic way.
Using a nifty SQL Server 2022 function, and the power of batch separator loops, we’re going to load the numbers 1-2 into two tables, twice.
CREATE TABLE
#t1
(
i integer
);
INSERT
#t1 (i)
SELECT
gs.*
FROM GENERATE_SERIES(1, 5) AS gs;
GO 2
CREATE TABLE
#t2
(
i integer
);
INSERT
#t2 (i)
SELECT
gs.*
FROM GENERATE_SERIES(1, 6) AS gs;
GO 2
Doing this will provide a unique set of the numbers 1-6 from both temporary tables.
SELECT
t.i
FROM #t1 AS t
UNION
SELECT
t.i
FROM #t2 AS t;
Which is not logically equivalent to doing this:
SELECT DISTINCT
t.i
FROM #t1 AS t
UNION ALL
SELECT DISTINCT
t.i
FROM #t2 AS t;
The first query will not only deduplicate rows within each query, but also in the final result.
The second query will only deduplicate results from each query, but not from the final result.
To avoid playing word games with you, the first query will return the numbers 1-6 only once, and the second query will return 1-5 once, and 1-6 once.
Some additional sense can be made of the situation by looking at the query plans, and where the distinctness is applied.
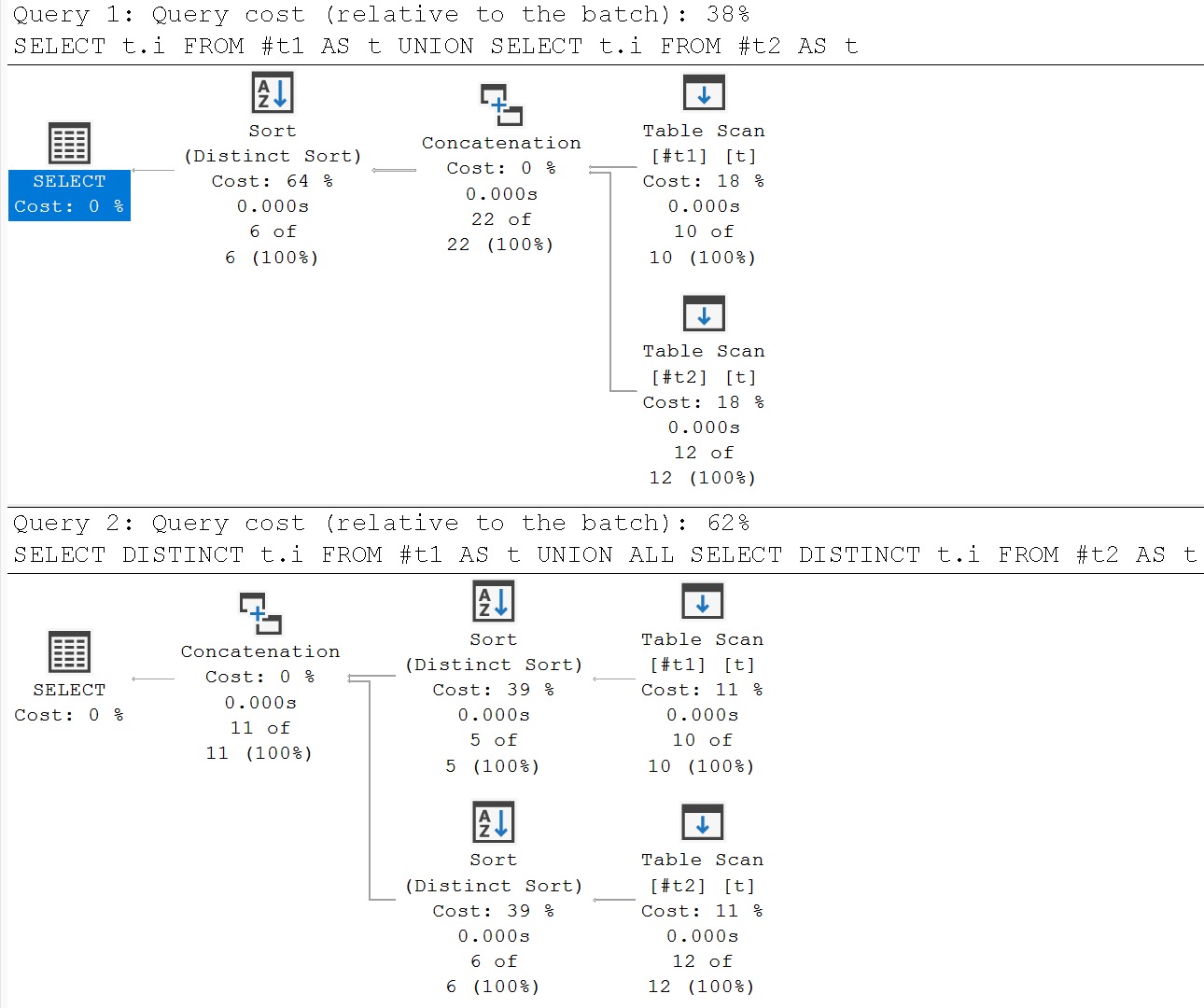
To put things plainly: if you’re already using UNION to bring to results together, there’s not a lot of sense in adding DISTINCT to each query.
Precedence, etc.
To better understand how UNION and UNION ALL are applied, I’d encourage you to use this simple example:
/*Changing these to UNION makes no difference*/ SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 /*Changing these to UNION makes a difference*/ UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3;
Specifically, look at the actual execution plans for these as you quote out ALL from the lines below the second comment.
You may even be surprised by what comes back when you get to the final UNION-ed select!
Orthodoxy
There has been quite a bit of performance debate about UNION and UNION ALL. Obviously, using UNION incurs some overhead to deduplicate results.
When you need it for result correctness, I’d encourage you to think about a few things:
- The number of columns you’re selecting
- The data types of the columns you’re selecting
- What data actually identifies a unique row
I’ve come across many queries that were selecting quite a long list of columns, with lots of string data involved, that did a whole lot better using windowing functions over one, or a limited number of columns, with more manageable data types, to produce the desired results.
Here is a somewhat undramatic example:
DROP TABLE IF EXISTS
#u1;
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
INTO #u1
FROM dbo.Comments AS c
WHERE c.Score IN (2, 9, 10)
AND c.UserId IS NOT NULL
UNION
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score IN (3, 9, 10)
AND c.UserId IS NOT NULL;
DROP TABLE IF EXISTS
#u2;
SELECT
y.CreationDate,
y.PostId,
y.Score,
y.Text,
y.UserId
INTO #u2
FROM
(
SELECT
x.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
x.UserId,
x.Score,
x.CreationDate,
x.PostId
ORDER BY
x.UserId,
x.Score,
x.CreationDate,
x.PostId
)
FROM
(
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score IN (2, 9, 10)
AND c.UserId IS NOT NULL
UNION ALL
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score IN (3, 9, 10)
AND c.UserId IS NOT NULL
) AS x
) AS y
WHERE y.n = 1;
In the first query, we’re doing a straight union of all the columns in the Comments table, which includes the Text column (nvarchar 700).
In the second query, the UNION has been replaced by UNION ALL, and I’m using ROW_NUMBER on the non-text columns, and filtering to only the first result.
Here are the query plans:
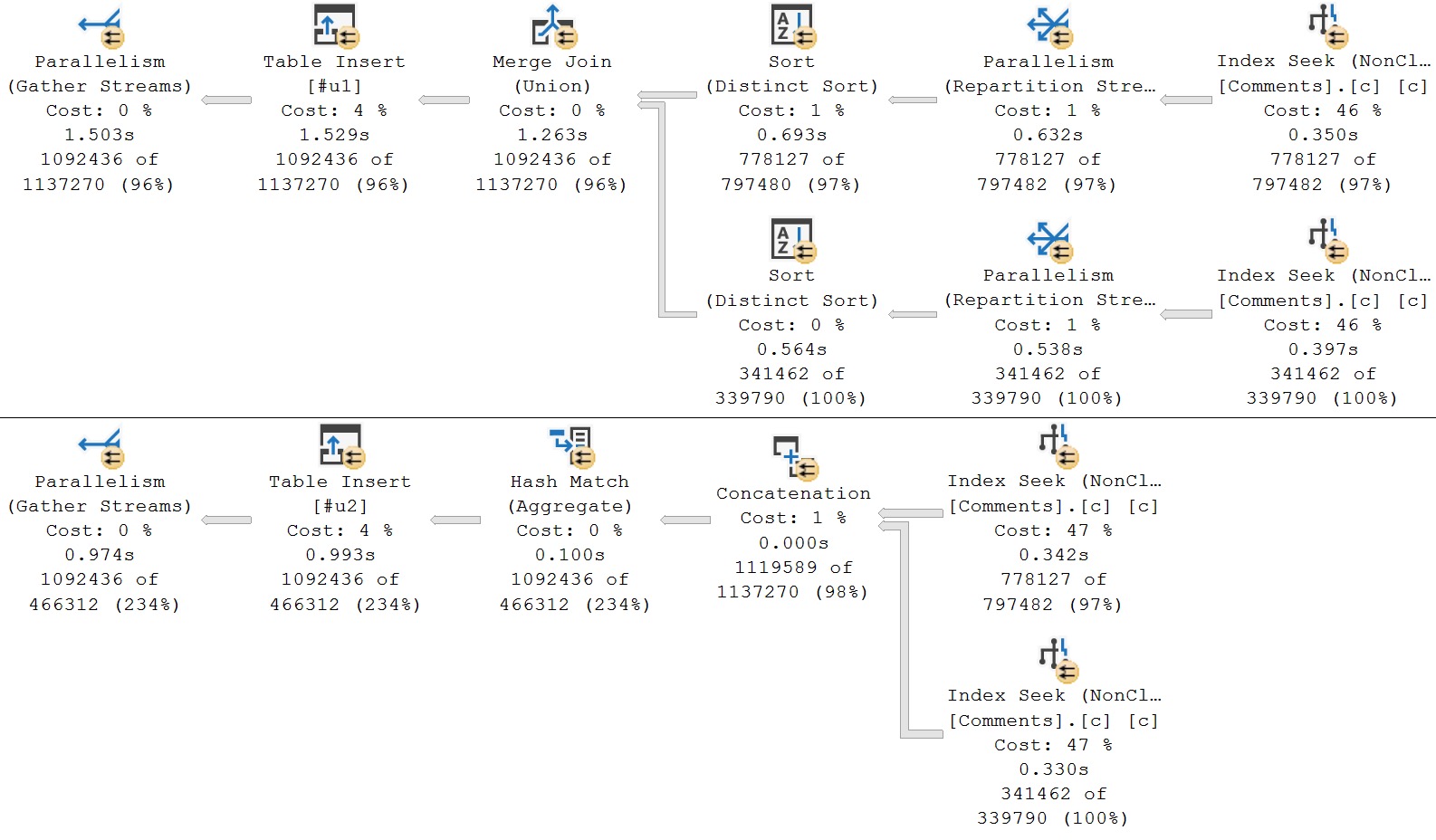
If you’re looking at the second query plan and wondering why you’re not seeing the usual traces of windowing functions (window aggregates, or segment and sequence project, a filter operator to get n = 1), I’d highly suggest reading Undocumented Query Plans: The ANY Aggregate.
Like I said, this is a somewhat undramatic example. It only shaves about 500ms off the execution time, though that is technically about 30% faster in this scenario. It’s a good technique to keep in mind.
The index in place for these queries has this definition:
CREATE INDEX
c
ON dbo.Comments
(UserId, Score, CreationDate, PostId)
INCLUDE
(Text)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Is UNION Ever Better Than UNION ALL?
There have been a number of times when producing distinct results has improved things rather dramatically, but there are a couple general characteristics they all shared:
- Producing unique rows, either via UNION or DISTINCT is not prohibitively time consuming
- The source being unique-ified feeds into an operation that is time consuming
Here’s an example:
CREATE INDEX
not_badges
ON dbo.Badges
(Name, UserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
not_posts
ON dbo.Posts
(OwnerUserId)
INCLUDE
(Score, PostTypeId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
DROP TABLE IF EXISTS
#waypops;
CREATE TABLE
#waypops
(
UserId integer NOT NULL
);
INSERT
#waypops WITH(TABLOCKX)
(
UserId
)
SELECT
b.UserId
FROM dbo.Badges AS b
WHERE b.Name IN
(
N'Popular Question', N'Notable Question',
N'Nice Question', N'Good Question',
N'Famous Question', N'Favorite Question',
N'Great Question', N'Stellar Question',
N'Nice Answer', N'Good Answer', N'Great Answer'
);
SELECT
wp.UserId,
SummerHereSummerThere =
SUM(ca.Score)
FROM #waypops AS wp
CROSS APPLY
(
SELECT
u.Score,
ScoreOrder =
ROW_NUMBER() OVER
(
ORDER BY
u.Score DESC
)
FROM
(
SELECT
p.Score,
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId = wp.UserId
AND p.PostTypeId = 1
UNION /*ALL*/
SELECT
p.Score,
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId = wp.UserId
AND p.PostTypeId = 2
) AS u
) AS ca
WHERE ca.ScoreOrder = 0
GROUP BY
wp.UserId
ORDER BY
wp.UserId;
Executing this query as UNION-ed results gives us a query that finishes in about 3 seconds.
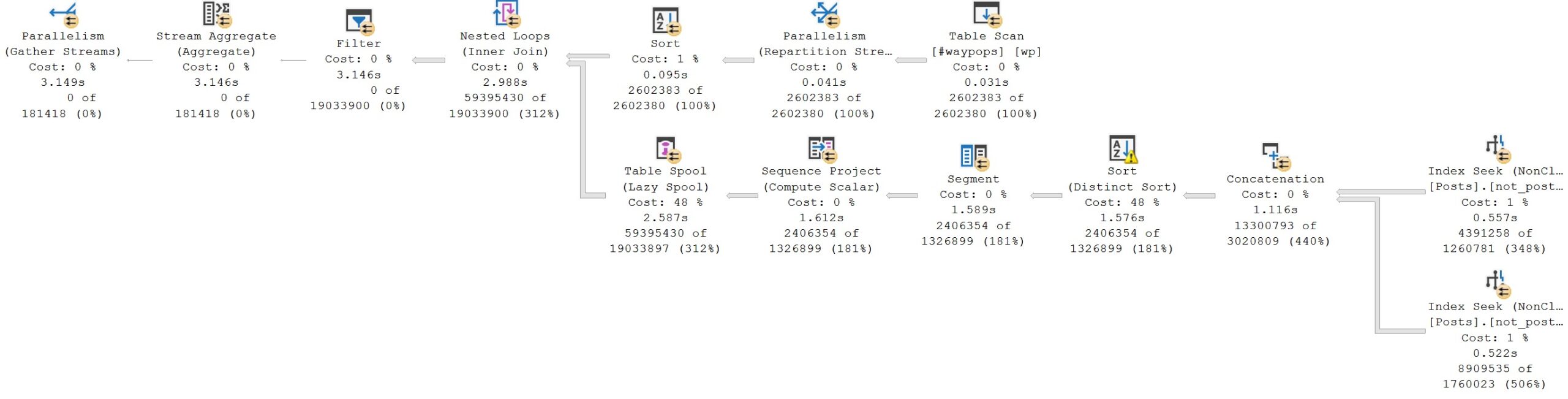
Note that the Distinct Sort operator chosen to implement the desired results of the UNION reduces the rows from 13,300,793 to 2,406,354. This is especially important when Lazy Table Spools are involved.
Here’s the query plan when it’s executed with UNION ALL:
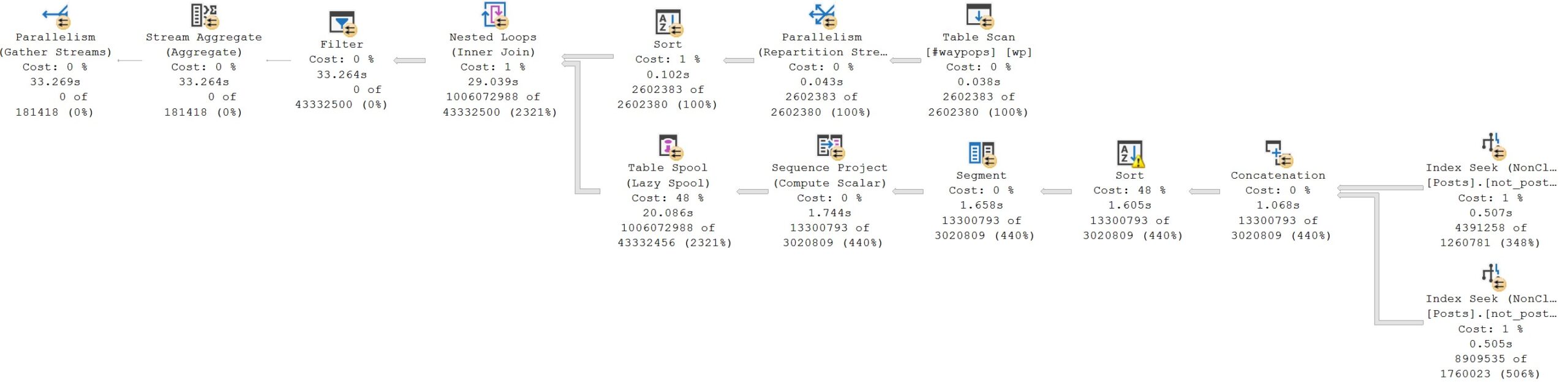
Execution time goes from 3 seconds to 33 seconds. You may notice that the numbers on the inner side of the nested loops join are much larger across the plan, and that the Lazy Table Spool goes from about 900ms (2.587 seconds minus 1.612 seconds) to taking about 18 seconds (20 seconds minus 1.7 seconds). The Nested Loops Join also suffers rather dramatically, taking nearly 9 seconds, instead of the original 300ms, largely owing to the fact that it has to deal with 946,677,558 additional rows.
You’d suffer, too. Mightily.
Championship Belt
Choosing between UNION and UNION ALL is of course primarily driven by logical query correctness, but you should fully consider which columns actually identify a unique row for your query.
There are sometimes better ways of identifying uniqueness than comparing every single column being selected out in the final result set.
When you run into slow queries that are using UNION and UNION ALL, it’s usually worth investigating the overall usage, and if using one over the other gives you better performance along with correct results.
Where UNION can be particularly troublesome:
- You’re selecting a lot of columns (especially strings)
- You’re attempting to deduplicating many rows
- You’re not working with a primary key
- You’re not working with useful supporting indexes
Where UNION ALL can be particularly troublesome:
- You’re selecting a lot of rows, and many duplicates exist in it
- You’re sending those results into other operations, like joins (particularly nested loops)
- You’re doing something computationally expensive on the results of the UNION ALL
Keep in mind that using UNION/UNION ALL is a generally better practice than writing some monolithic query with endless OR conditions in it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Related Posts
- The How To Write SQL Server Queries Correctly Cheat Sheet: INTERSECT And EXCEPT
- The How To Write SQL Server Queries Correctly Cheat Sheet: Views vs. Inline User Defined Functions
- The How To Write SQL Server Queries Correctly Cheat Sheet: Common Table Expressions
- The How To Write SQL Server Queries Correctly Cheat Sheet: IN And NOT IN
One thought on “The How To Write SQL Server Queries Correctly Cheat Sheet: UNION vs. UNION ALL”
Comments are closed.