Teeth To Grit
I’ve always had trouble standing still on SQL Server versions, but most companies don’t. Hardly anyone I talk to is on SQL Server 2017, though these days SQL Server 2016 seems more common than SQL Server 2012, so at least there’s that. Mostly I’m happy to not see SQL Server 2014. God I hate SQL Server 2014.
Despite the lack of adoption, I’ve been moving all my training material to SQL Server 2019. Heck, in a few years, my old posts might come in handy for you.
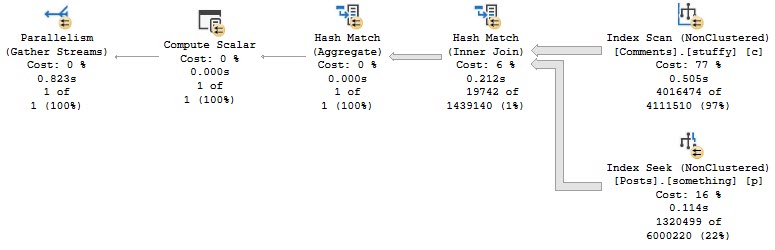
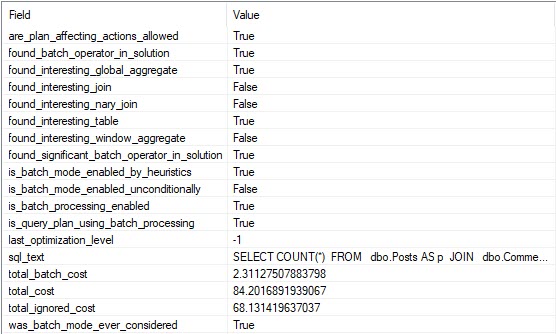
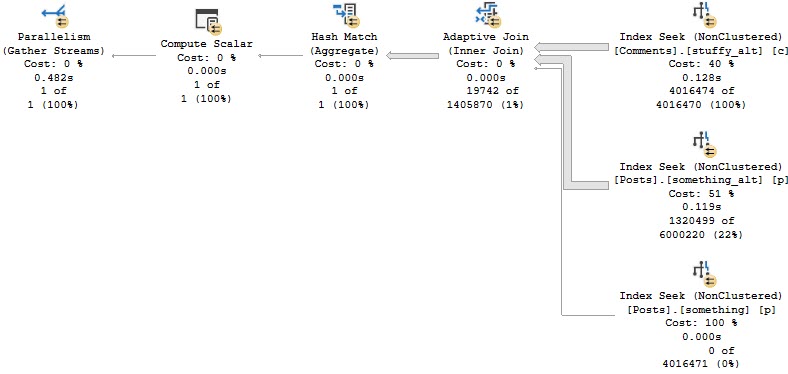
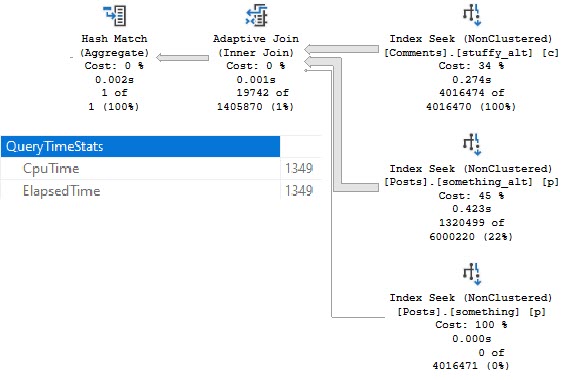
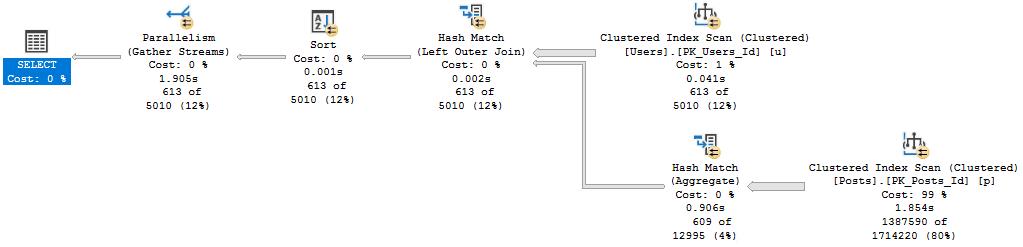
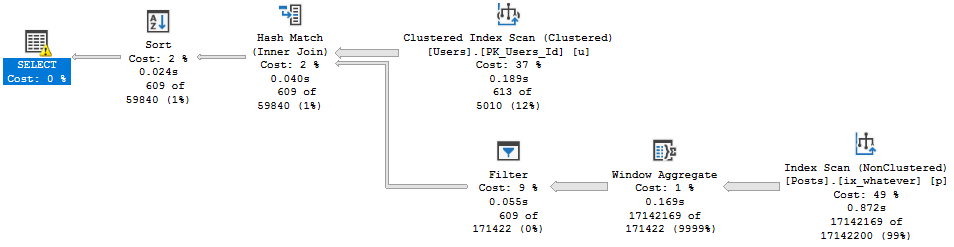
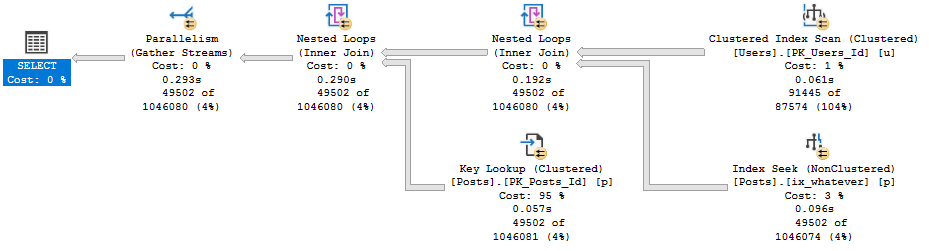
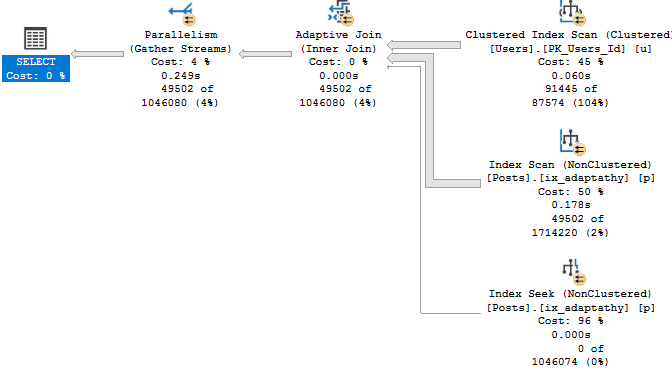
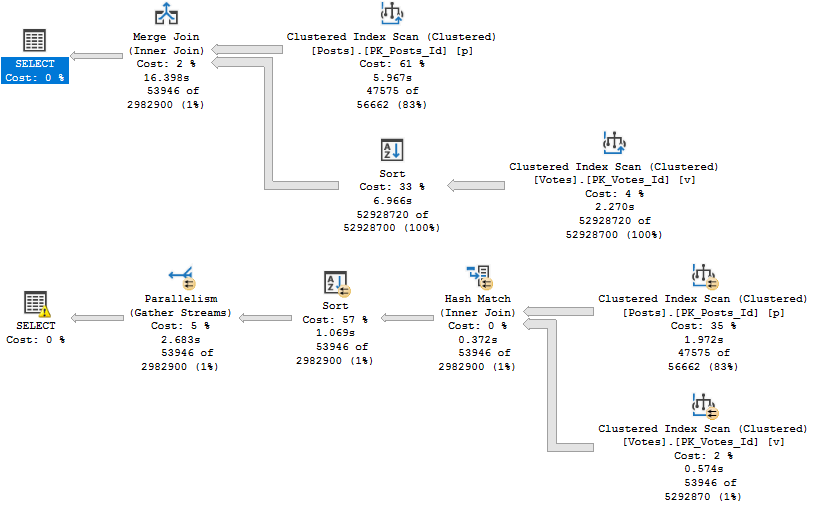
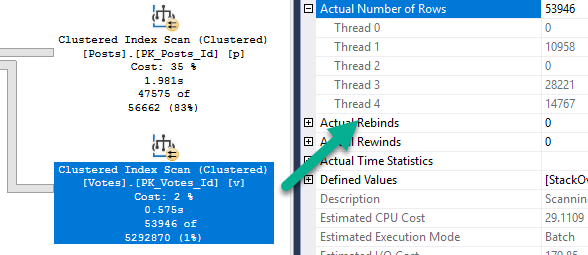
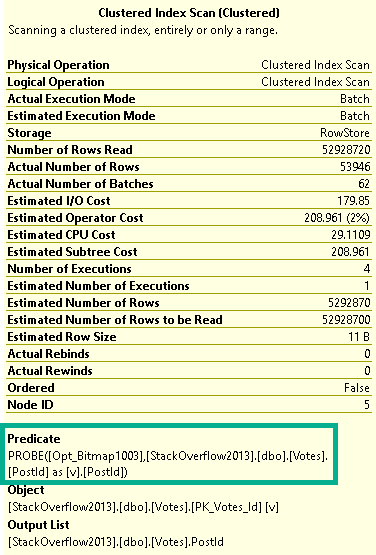
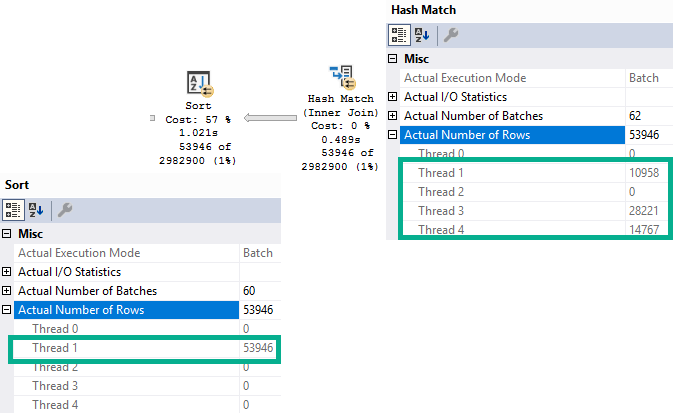
But during that process, I kept running into the same problem: The demos generally still worked for the OLTP-ish queries, but for the report-ish queries Batch Mode On Rowstore (BMOR, from here) was kicking butt (most of the time anyway, we’re gonna look at some hi-jinks this week).
The problem, so far as I could tell, was that the Stack Overflow 2013 database just wasn’t enough database for SQL Server 2019 (at least with my hardware). My laptop is quad core (8 with HT) @2.9GHz, with 64GB of RAM, and max server memory set to 50GB. The SO2013 database is… just about 50GB.
While it’s fun to be able to create performance problems even with the whole database in memory, it doesn’t match what lot of people are dealing with in real life.
Especially you poor saps on Standard Edition.
My options seemed to be:
- Drop max server memory down
- Use a VM with lower memory
- Use the full size Stack Overflow database
Flipping and Flopping
Each of these has problems, though.
Dropping max server memory down is okay for the buffer pool, but SQL Server (it seems especially with column store/batch mode) is keen to use memory above that for other things like memory grants.
A lot of the interesting struggle I see on client servers between the buffer pool and query memory grants didn’t happen when I did that.
Using a VM with lower memory, while convenient, just didn’t seem as fun. Plus, part of the problem is that, while I make fun of other sample databases for being unrealistically tiny, at least they have relatively modern dates in some of them.
I was starting to feel really goofy having time stop on January 31st, 2013.
I suppose I could have updated all the CreationDate columns to modernize things, but who knows what that would have thrown off.
Plus, here’s a dirty little secret: all the date columns that start with “Last” that track stuff like when someone last logged in, or when a post was last active/edited, they don’t stop at 2013-12-31. They extend up to when the database was originally chopped down to size, in 2017 or so. I always found that a bit jarring, and I’d have to go and add time to them, too, to preserve the gaps.
It all starts to feel a bit like revisionist history.
The End Is Thigh
In the end, I settled on using the most recent version available here, but with a couple of the tables I don’t regularly use in demos cut out: PostHistory, and PostLinks. Once you drop those out, a 360GB database drops down to a much more manageable 150Gb or so.
If you’d like to get a copy, here’s the magnet link.
The nice thing is that the general cadence of the data is the same in many ways and places, so it doesn’t take a lot to adjust demos to work here. Certain Post and Vote Types, User Ids, Reputations, etc. remain skewed, and outliers are easy to find. Plus, at 3:1 data to memory, it’s a lot harder to keep everything safely in the buffer pool.
This does present different challenges, like index create time to set up for things, database distribution, etc.
But if I can give you better demos, that seems worth it.
Plus, I hear everything is in the cloud now anyway.
Alluding To
In the process of taking old demos and seeing how they work with the new database, I discovered some interesting stuff that I want to highlight a little bit. So far as I can tell, they’re not terribly common (yet), but that’s what makes them interesting.
If you’re the kind of person who’s looking forward to SQL Server 2019’s performance features solving some problems for you auto-magick-ally, these may be things you need to watch out for, and depending on your workload they may end up being quite a bit more common than I perceive.
I’m going to be specifically focusing on how BMOR (and to some extent Adaptive Joins) can end up not solving performance issues, and how you may end up having to do some good ol’ fashion query tuning on your own.
In the next post, we’ll look at how one of my favorite demos continues to keep on giving.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.