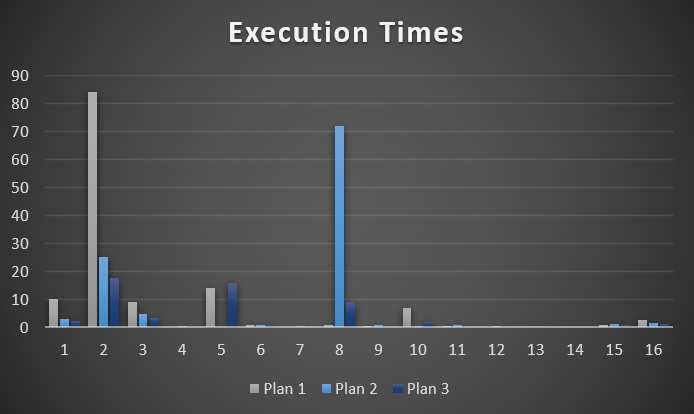
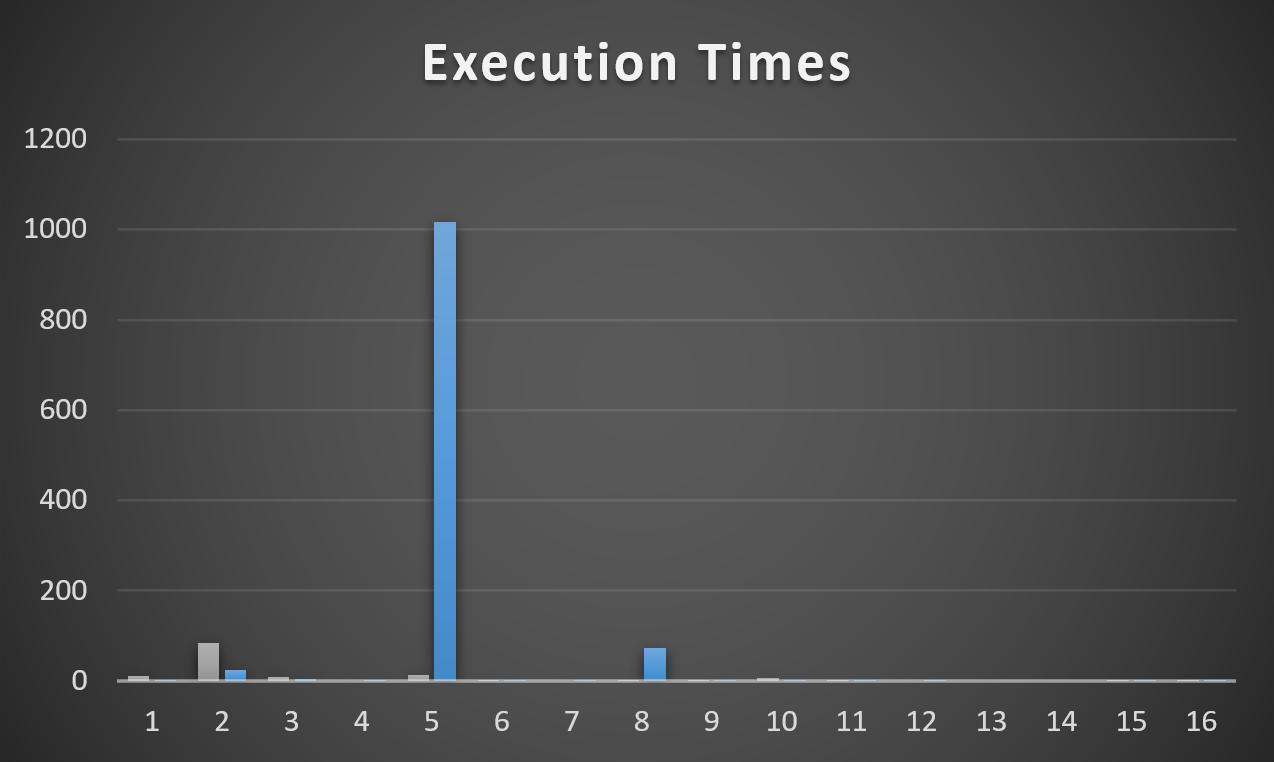
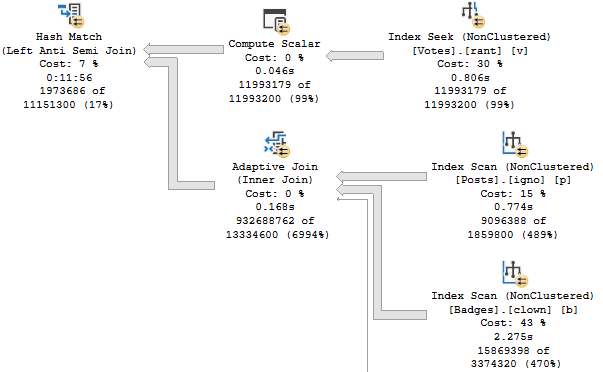
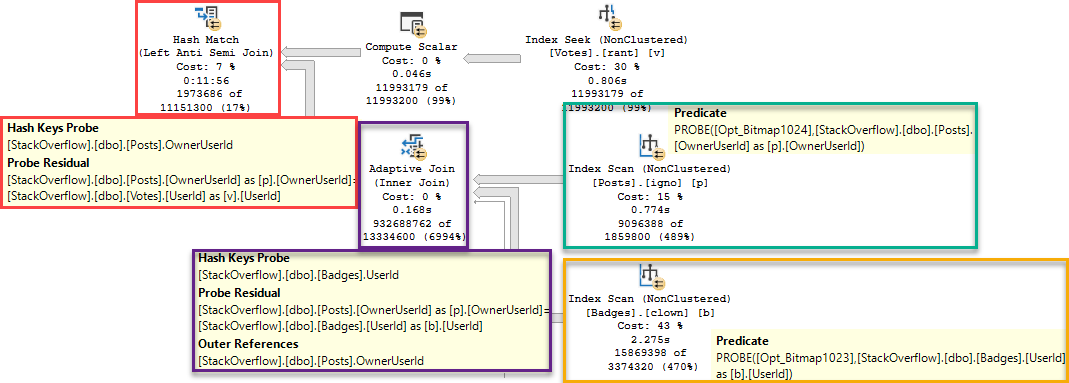
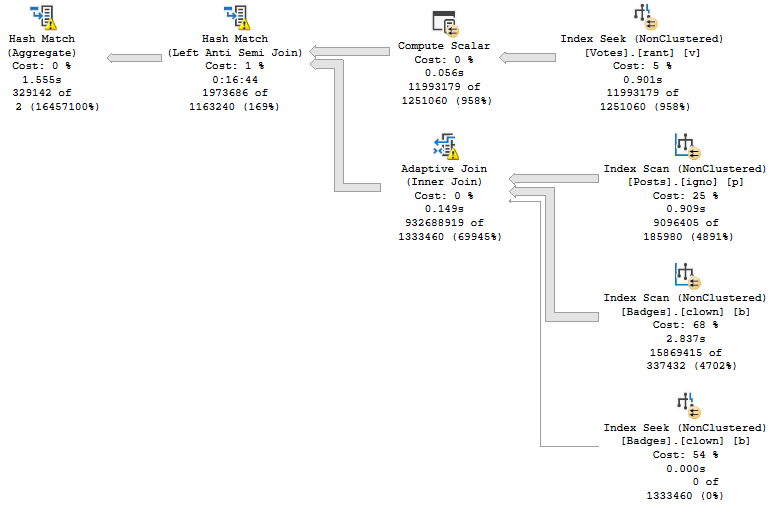
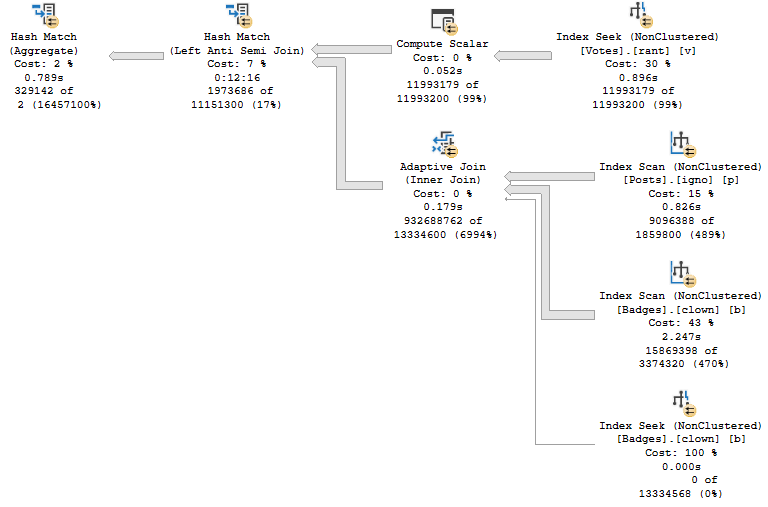
We Will Talk About Things And Have Fun Now
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
USE StackOverflow;
EXEC dbo.DropIndexes;
/*
CREATE INDEX east
ON dbo.Posts
(PostTypeId, Score, OwnerUserId)
WITH ( MAXDOP = 8,
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = ROW );
*/
DROP TABLE IF EXISTS #t;
GO
SELECT
u.Id,
u.Reputation,
u.DisplayName,
p.Id AS PostId,
p.Title
INTO #t
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE u.Reputation >= 1000
AND p.PostTypeId = 1
AND p.Score >= 1000
ORDER BY u.Reputation DESC;
/*
CREATE INDEX east
ON dbo.Posts(PostTypeId, Score, OwnerUserId);
*/
SELECT
t.Id,
t.Reputation,
(
SELECT
MAX(p.Score)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = t.Id
AND p.PostTypeId IN (1, 2)
) AS TopPostScore,
t.PostId,
t.Title
FROM #t AS t
ORDER BY t.Reputation DESC;
/*
Usually I love replacing select
list subqueries with APPLY
Just show the saved plan here
*/
SELECT
t.Id,
t.Reputation,
pq.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --We have to use outer apply to not restrict results!
(
SELECT
MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = t.Id
AND p.PostTypeId IN (1, 2)
) AS pq
ORDER BY t.Reputation DESC;
/*
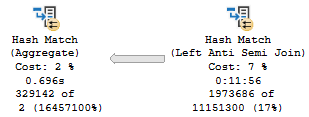
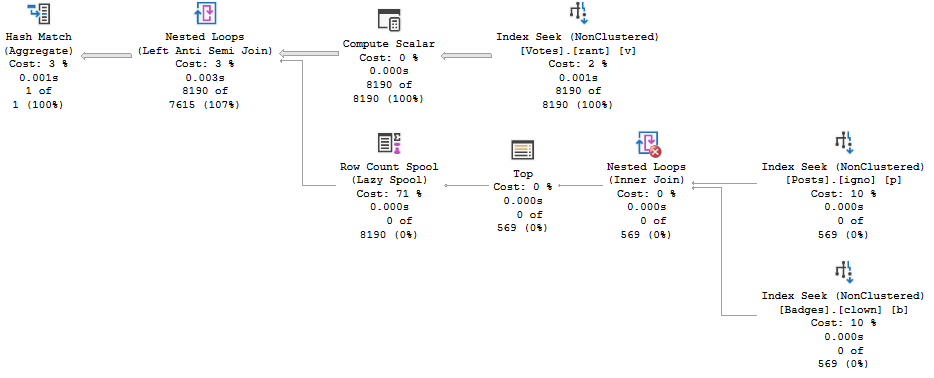
TOP (1) also spools
*/
SELECT
t.Id,
t.Reputation,
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS TopPostScore,
t.PostId,
t.Title
FROM #t AS t
ORDER BY t.Reputation DESC;
SELECT
t.Id,
t.Reputation,
pq.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq
ORDER BY t.Reputation DESC;
/*
CREATE INDEX east
ON dbo.Posts(PostTypeId, Score, OwnerUserId);
*/
SELECT
t.Id,
t.Reputation,
pq.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --This one is fast
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq
ORDER BY t.Reputation DESC;
SELECT
t.Id,
t.Reputation,
pa.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --This two is slow...
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pa
ORDER BY t.Reputation DESC;
/*
Use the Score!
*/
SELECT
t.Id,
t.Reputation,
ISNULL(pa.Score, pq.Score) AS TopPostScore,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --This one is fast
(
SELECT TOP (1)
p.Score --Let's get the top score here
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq
OUTER APPLY --This two is slow...
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = t.Id
AND pq.Score < p.Score --Then use it as a filter down here
ORDER BY p.Score DESC
) AS pa
ORDER BY t.Reputation DESC;
SELECT
t.Id,
t.Reputation,
ISNULL(pq.Score, 0) AS Score,
t.PostId,
t.Title
INTO #t2
FROM #t AS t
OUTER APPLY --This one is fast
(
SELECT TOP (1)
p.Score --Let's get the top score here
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq;
SELECT
t.Id,
t.Reputation,
ISNULL(pa.Score, t.Score) AS TopPostScore,
t.PostId,
t.Title
FROM #t2 AS t
OUTER APPLY
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = t.Id
AND t.Score < p.Score --Then use it as a filter down here
ORDER BY p.Score DESC
) AS pa
ORDER BY t.Reputation DESC;
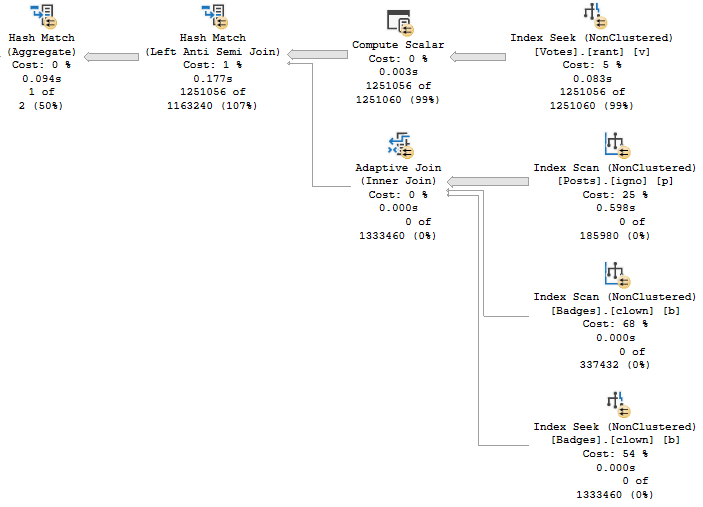
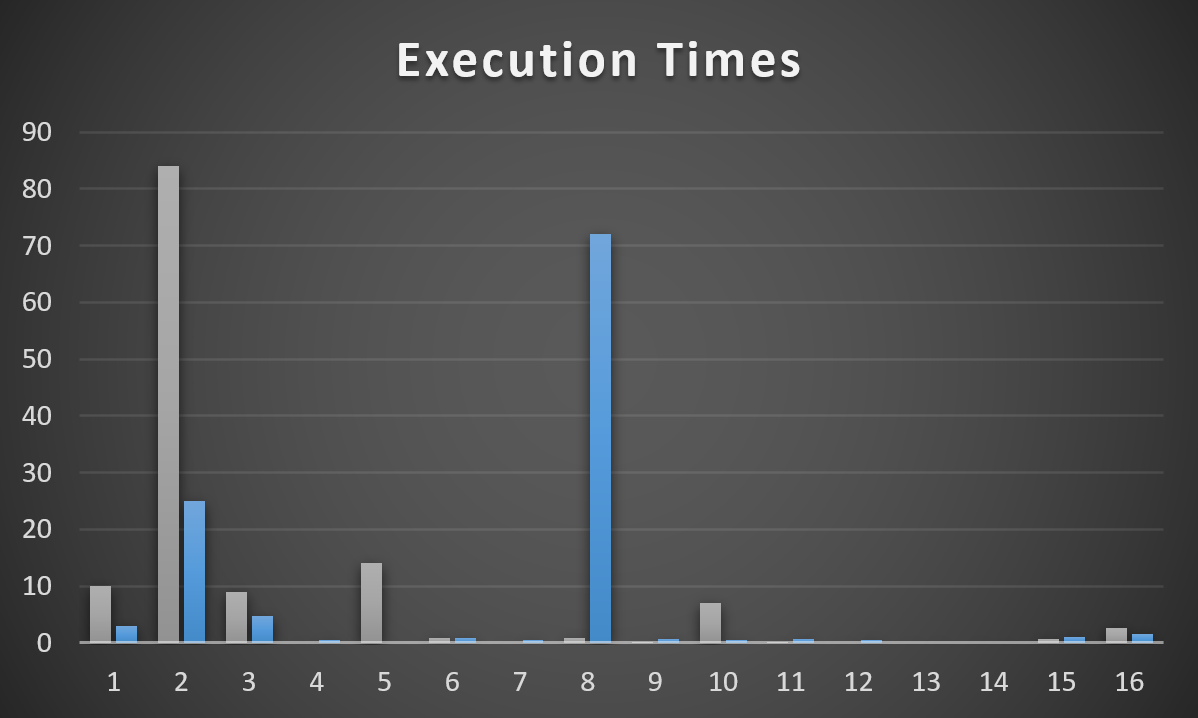
/*
What happened?
* Index key column order
* (PostTypeId, Score, OwnerUserId)
Other things we could try:
* Shuffling index key order, or creating a new index
* (PostTypeId, OwnerUserId, Score)
* Rewriting the query to use ROW_NUMBER() instead
* Have to be really careful here, probably use Batch Mode
*/
/*
CREATE TABLE dbo.t
(
id int NOT NULL,
INDEX c CLUSTERED COLUMNSTORE
);
*/
SELECT
t.Id,
t.Reputation,
pa.Score,
t.PostId,
t.Title
FROM #t AS t
LEFT JOIN dbo.t AS tt ON 1 = 0
OUTER APPLY
(
SELECT
rn.*
FROM
(
SELECT
p.*,
ROW_NUMBER()
OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
) AS n
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
) AS rn
WHERE rn.OwnerUserId = t.Id
AND rn.n = 1
) AS pa
ORDER BY t.Reputation DESC;
DROP TABLE #t, #t2;