Errant Hairs
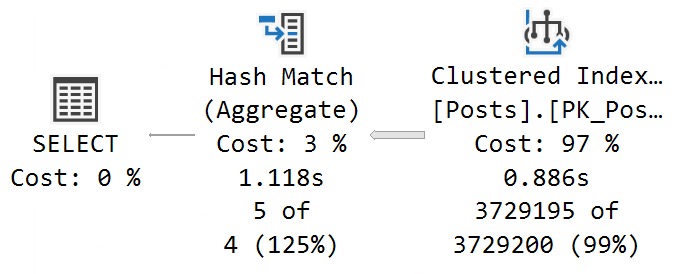
I’ve used this procedure as an example in the past. It’s a great parameter sniffing demo.
Why is it great? Because there’s exactly one value in the Posts table that causes an issue. It causes that issue because someone hated the idea of normalization.
The better thing to do here would be to have separate tables for questions and answers. Because we don’t have those, we end up with a weird scnenario.
In the Posts table, because questions and answers are lumped in together, there are certain traits that different types of posts can’t share:
- Answers can’t have answers
- Questions can’t have parent questions
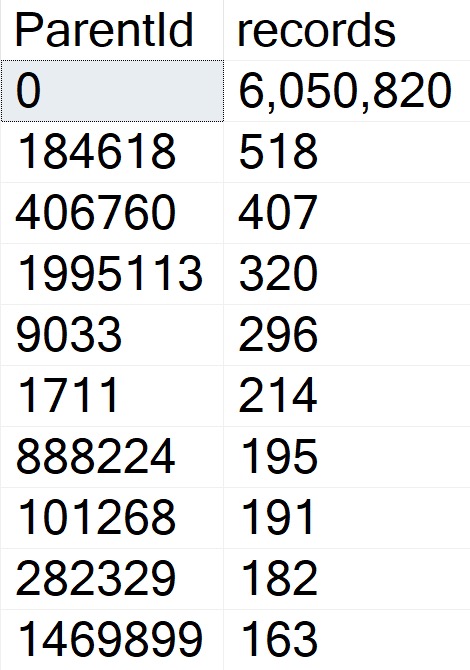
There are other examples, but those are the two most obvious ones. But anyway, because of that, every Question has a ParentId of zero, and every Answer has the ParentId of the question it was posted under.
With around 6 million questions in the Posts table, that means there are around 6 million rows with a ParentId of zero, and around 11 million rows with other values.
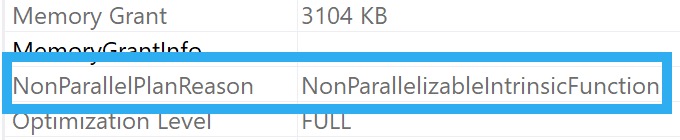
Current Affairs
In compat level 150, if I run this procedure like so:
EXEC dbo.OptionalRecompile
@ParentId = 184618;
EXEC dbo.OptionalRecompile
@ParentId = 0;
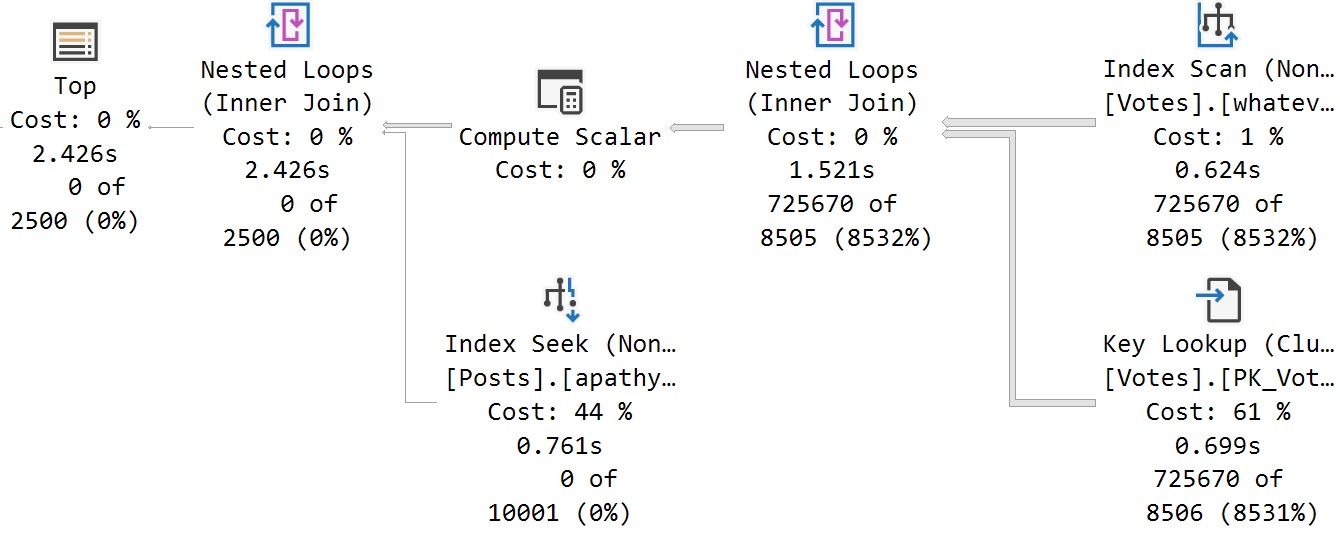
The query plan is shared, and the second execution eats it:
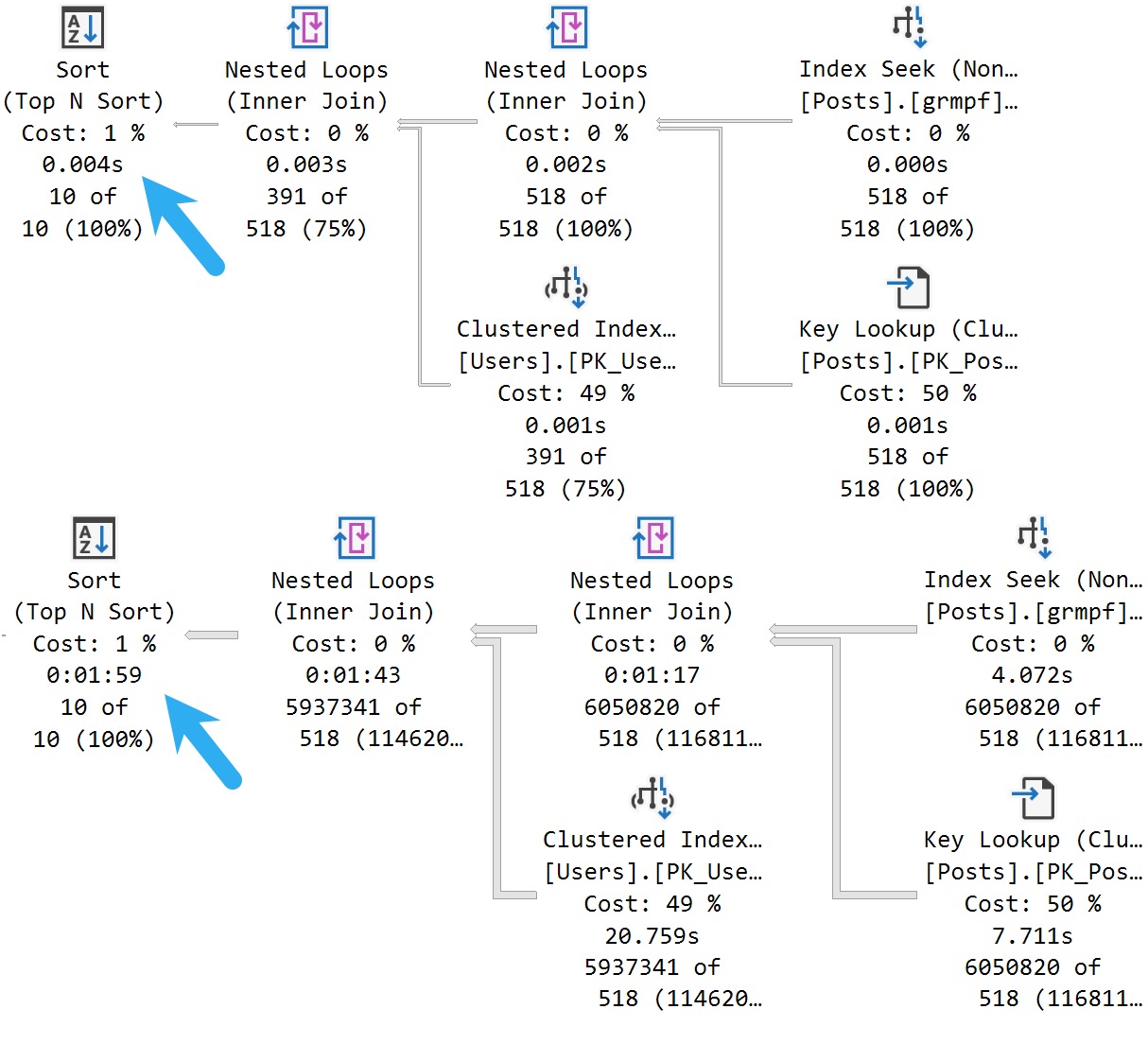
From 4ms to 2 minutes is pretty bad.
2OH22
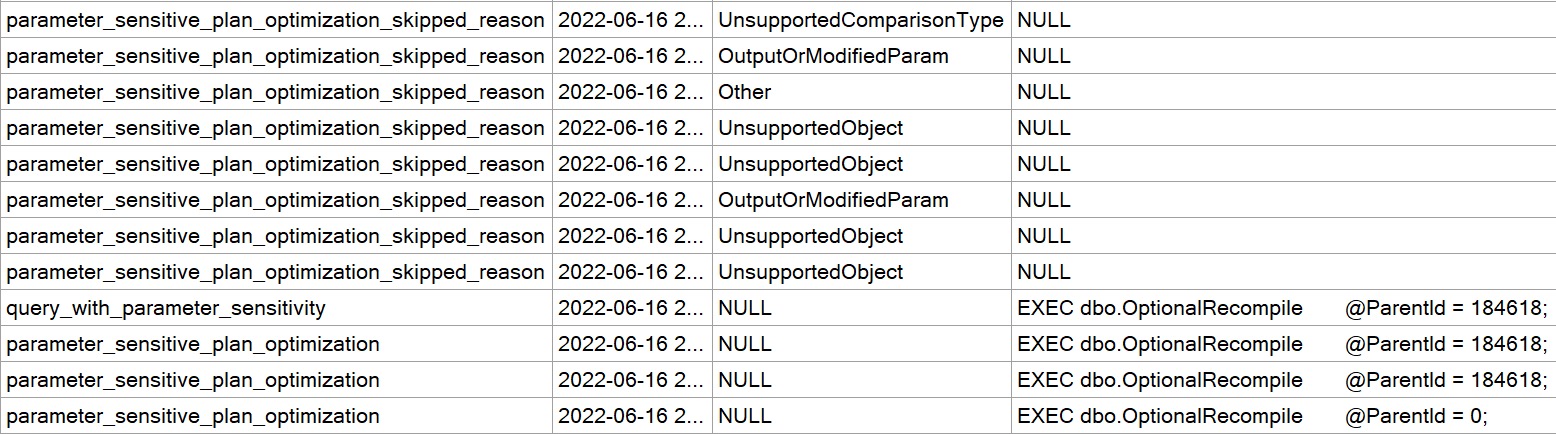
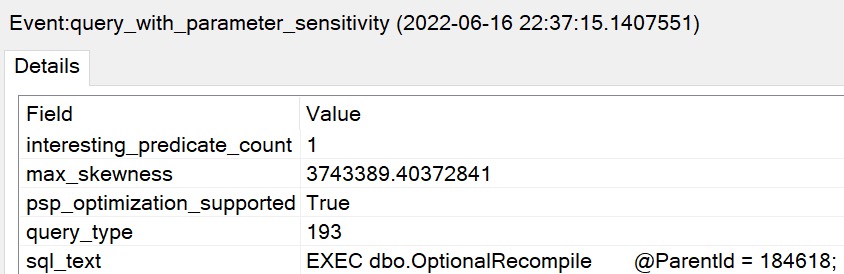
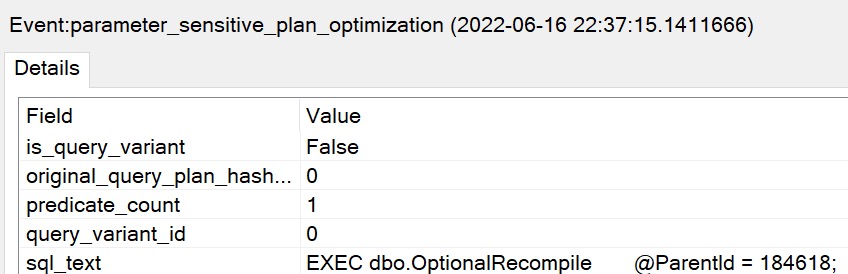
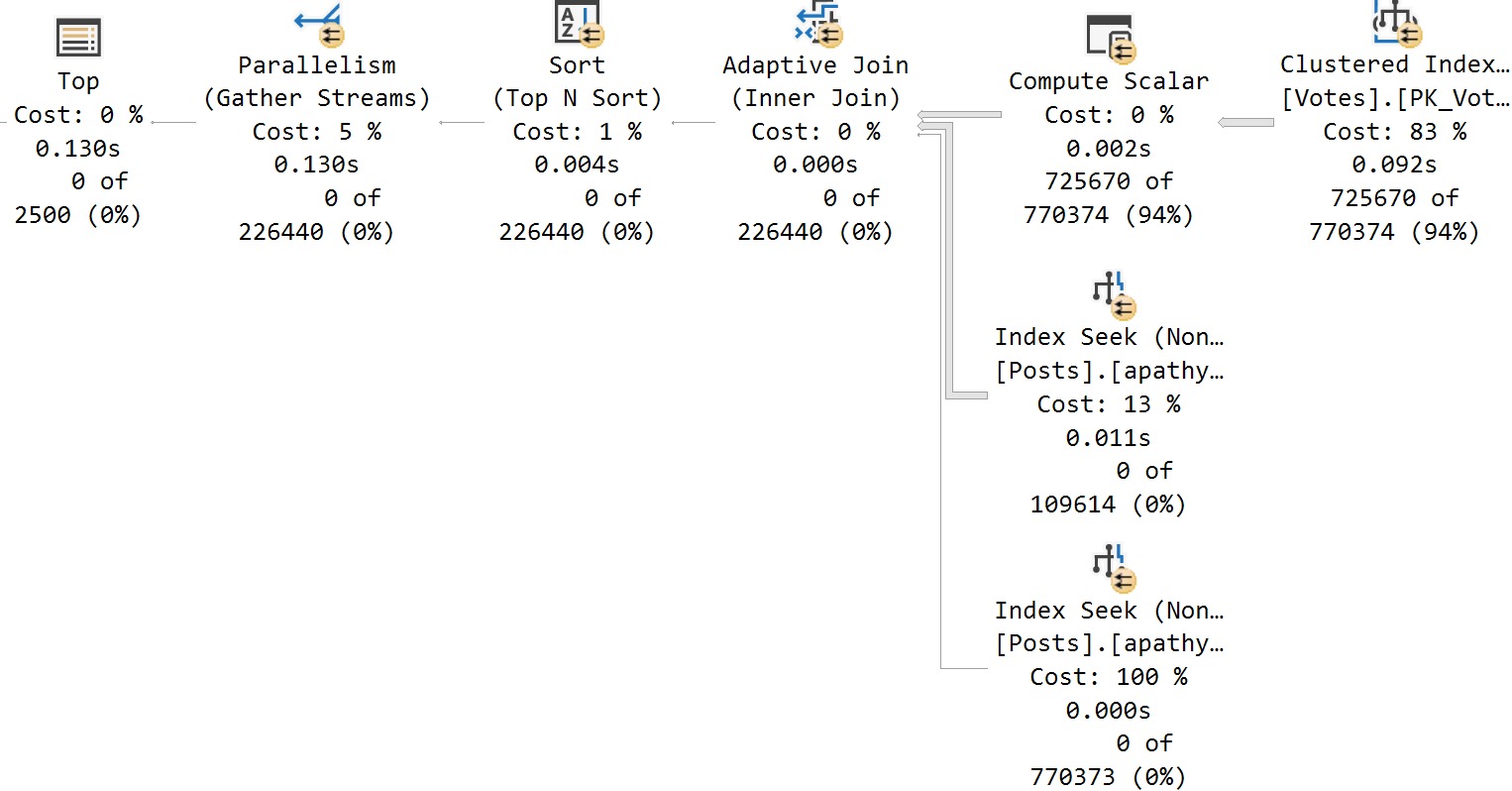
In compat level 160, if I do that exact same thing, the plans are immediately different for each execution:
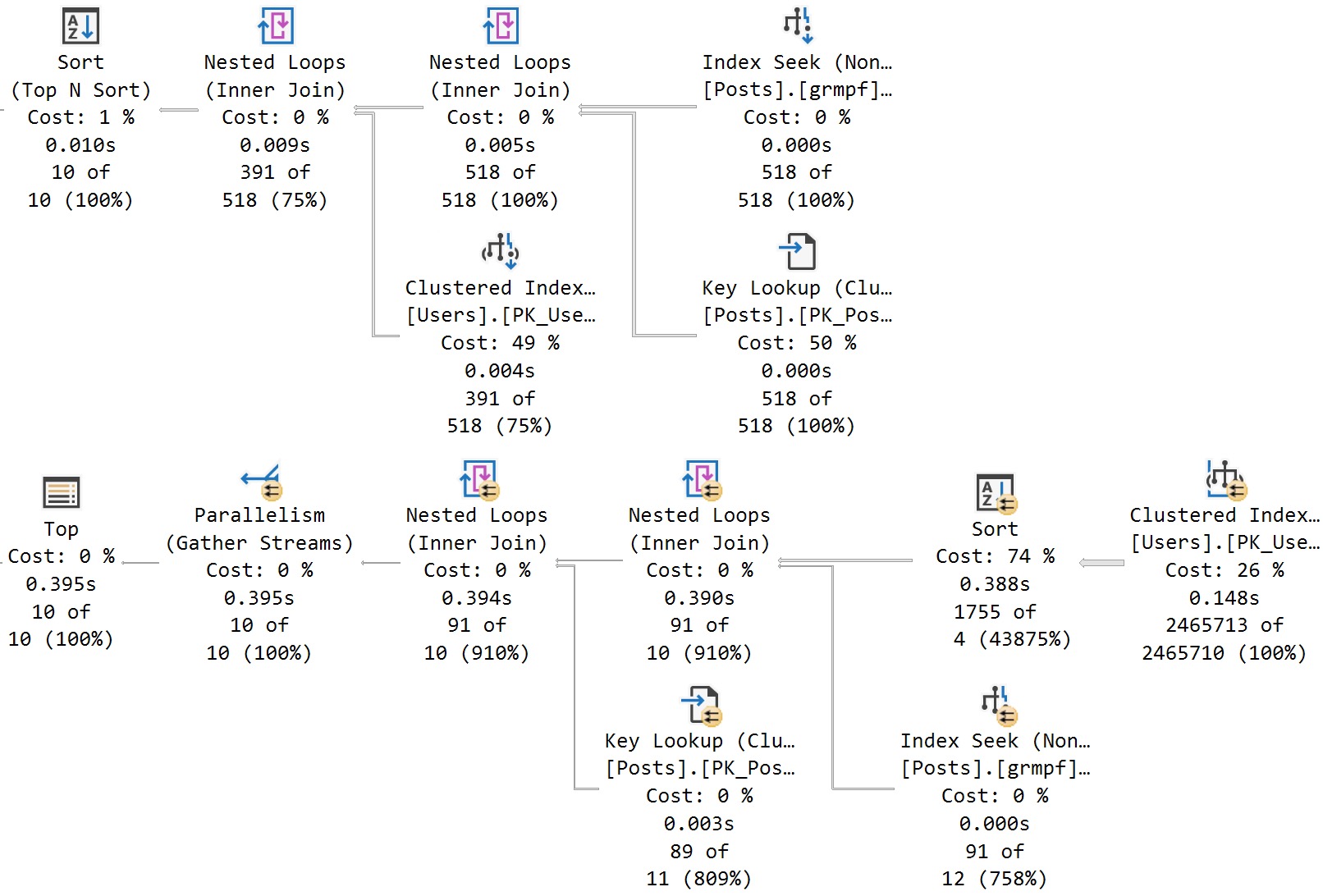
This is a much better situation. Each separate plan is perfectly eligible for reuse. Neat. Great.
This is exactly the kind of query plan shenanigans (plananigans?) that should be avoided.
The only difference in the query text is the QueryVariantID:
option (PLAN PER VALUE(QueryVariantID = 2, predicate_range([StackOverflow2013].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0))) option (PLAN PER VALUE(QueryVariantID = 3, predicate_range([StackOverflow2013].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
And over in Query Store, we have these little lovelies:
SELECT qspf.* FROM sys.query_store_plan_feedback AS qspf;
+------------------+---------+------------+--------------+-----------------------+-------+-------------------+
| plan_feedback_id | plan_id | feature_id | feature_desc | feedback_data | state | state_desc |
+------------------+---------+------------+--------------+-----------------------+-------+-------------------+
| 6 | 3 | 1 | CE Feedback | {"Feedback hints":""} | 1 | NO_RECOMMENDATION |
| 7 | 2 | 1 | CE Feedback | {"Feedback hints":""} | 1 | NO_RECOMMENDATION |
+------------------+---------+------------+--------------+-----------------------+-------+-------------------+
Good job, SQL Server 2022.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.