Statistical Legacy
A client question that I get quite a bit is around why queries in production get a bad query plan that queries in dev, QA, or staging don’t get is typically answered by looking at statistics.
Primarily, it’s because of the cardinality estimates that queries get around ascending keys. It usually gets called the ascending key problem, but the gist is that:
- You have a pretty big table
- You’re using the legacy cardinality estimator
- A whole bunch of rows get inserted, but not enough to trigger an auto stats update
- You’re not using compatibility level >= 130 or trace flag 2371
- Queries that look for values off an available histogram get a one row estimate using the legacy Cardinality Estimator or a 30% estimate using the default Cardinality Estimator
Which is a recipe for potentially bad query plans.
Reproductive Script
Here’s the full repro script. If you’re using a different Stack Overflow database, you’ll need to adjust the numbers.
USE StackOverflow2013;
/*Figure out the 20% mark for stats updates using legacy compat levels*/
SELECT
c = COUNT_BIG(*),
c20 = CEILING(COUNT_BIG(*) * .20)
FROM dbo.Users AS u;
/*Stick that number of rows into a new table*/
SELECT TOP (493143)
u.*
INTO dbo.Users_Holder
FROM dbo.Users AS u
ORDER BY u.Id DESC;
/*Delete that number of rows from Users*/
WITH
del AS
(
SELECT TOP (493143)
u.*
FROM dbo.Users AS u
ORDER BY u.Id DESC
)
DELETE
FROM del;
/*I'm using this as a shortcut to turn off auto stats updates*/
UPDATE STATISTICS dbo.Users WITH NORECOMPUTE;
/*Put the rows back into the Users Table*/
SET IDENTITY_INSERT dbo.Users ON;
INSERT
dbo.Users
(
Id,
AboutMe,
Age,
CreationDate,
DisplayName,
DownVotes,
EmailHash,
LastAccessDate,
Location,
Reputation,
UpVotes,
Views,
WebsiteUrl,
AccountId
)
SELECT
uh.Id,
uh.AboutMe,
uh.Age,
uh.CreationDate,
uh.DisplayName,
uh.DownVotes,
uh.EmailHash,
uh.LastAccessDate,
uh.Location,
uh.Reputation,
uh.UpVotes,
uh.Views,
uh.WebsiteUrl,
uh.AccountId
FROM dbo.Users_Holder AS uh;
SET IDENTITY_INSERT dbo.Users OFF;
/*Figure out the minimum Id we put into the holder table*/
SELECT
m = MIN(uh.Id)
FROM dbo.Users_Holder AS uh;
/*Compare estimates*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id > 2623772
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id > 2623772
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
/*Cleanup*/
UPDATE STATISTICS dbo.Users;
TRUNCATE TABLE dbo.Users_Holder;
Query Plans
Here are the plans for the stars of our show:
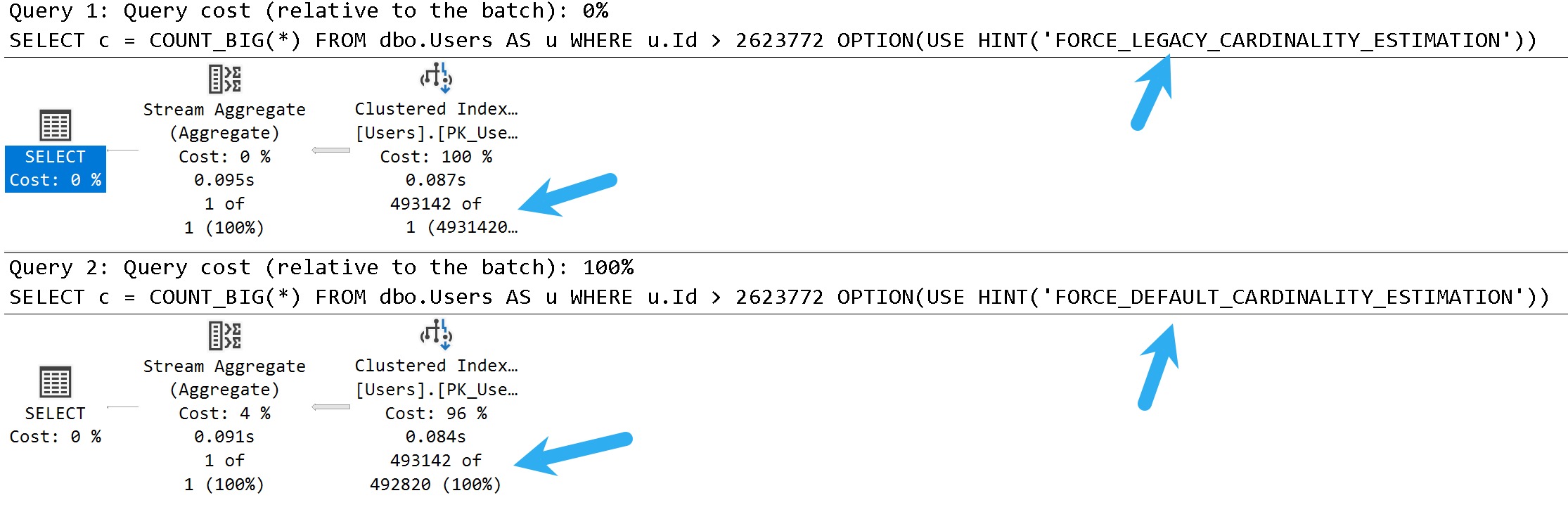
In these query plans, you can see the legacy cardinality estimator gets a one row estimate, and the default cardinality estimator gets a 30% estimate.
There isn’t necessarily a one-is-better-than-the-other answer here, either. There are times when both can cause poor plan choices.
You can think of this scenario as being fairly similar to parameter sniffing, where one plan choice does not fit all executions well.
Checkout
There are a lot of ways that you can go about addressing this.
In some cases, you might be better off using trace flag 2371 to trigger more frequent auto stats updates on larger tables where the ~20% modification counter doesn’t get hit quickly enough. In others, you may want to force one estimator over the other depending on which gets you a better plan for most cases.
Another option is to add hints to the query in question to use the default cardinality estimator (FORCE_DEFAULT_CARDINALITY_ESTIMATION), or to generate quick stats for the index/statistics being used (ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS). Documentation for both of those hints is available here. Along these lines, trace flags 2389, 2390, or 4139 may be useful as well.
Of course, you could also try to address any underlying query or index issues that may additionally contribute to poor plan choices, or just plan differences. A common problem in them is a seek + lookup plan for the one row estimate that doesn’t actually make sense when the actual number of rows and lookup executions are encountered at runtime.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.