Your Girlfriend
Anyone who tells you there are only three types of joins in SQL Server isn’t your friend.
Okay, maybe that’s harsh. Maybe they’re just getting you prepared for the bonne promenade through all the many different faces a join can wear in your query plans.
Maybe they have a great explanation for Grace Hash Joins in their back pocket that they’re waiting to throw in your face like a bunch of glitter.
Maybe.
Nested Loops Join
Nested loops are the join type that everyone starts talking about, so in the interest of historical familiarity, I will too. And you’ll like it. Because that’s what you’re used to.
Some things to look for in the properties of a Nested Loops join:
- Prefetching (can be ordered or not ordered)
- Vanilla Nested Loops (predicate applied at the join)
- Apply Nested Loops (Outer Reference at join operator, predicate applied at index)
- As part of a Lookup (key or bookmark)
Nested Loops work best a relatively small outer input, and an index to support whatever join conditions and other predicates against the inner table.
When the outer side of a Nested Loops Join results in N number of scans on the inner side, you can usually expect performance to be unsatisfactory.
This may be part of the reason why Adaptive Joins have the ability to make a runtime decision to choose between Hash and Nested Loops Joins.
Right now, Nested Loops Joins can’t execute in Batch Mode. They do support parallelism, but the optimizer is biased against those plans, and cost reductions are only applied to the outer side of the plan, not the inner side.
A fun piece of SQL Jeopardy for the folks watching along at home: these are the only type of joins that don’t require an equality predicate. Wowee.
This is how Microsoft keeps consultants employed.
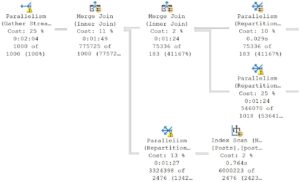
Merge Join
Traditionally in second place, though I wish they’d be done away with, are Merge Joins.
People always say things like “I wish I had a dollar for every time blah blah blah”, but at this point I think I do have a dollar for every time a Merge Join has sucked the life out of a query.
If you’ll permit me to make a few quick points, with the caveat that each should have “almost always” injected at some point:
- Many to Many Merge Joins were a mistake
trash - Sort Merge plans were a mistake
- Parallel Merge Joins were a mistake
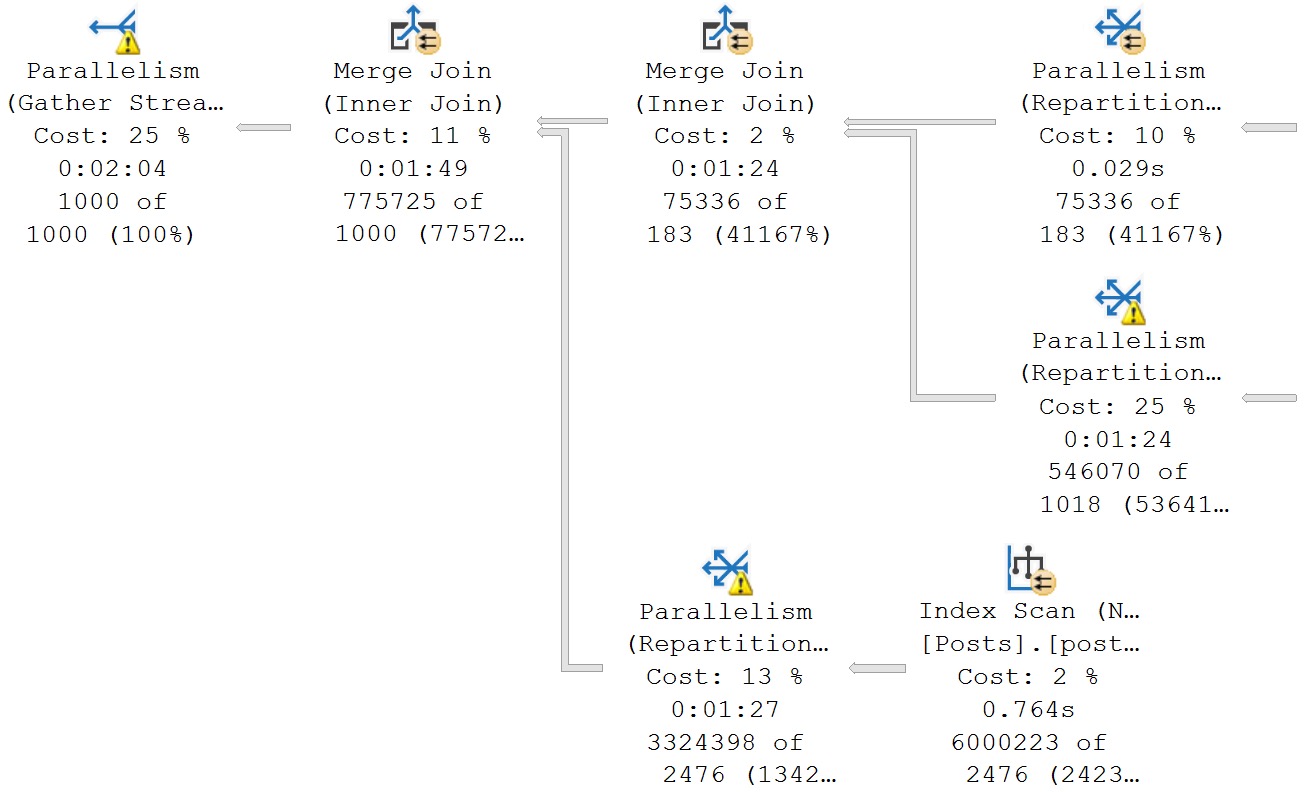
Merge joins don’t support Batch Mode, and are not part of the Adaptive Join decision making process. That’s how terrible they are.
Part of what makes them terrible is that they expect ordered input. If you don’t have an index that does that, SQL Server’s Cost Based Optimizer might fly right off the handle and add a Sort into your query plan to satisfy our precious little Merge Join.
The gall.
In a parallel plan, this can be especially poisonous. All that expected ordering can result in thread to thread dependencies that may lead to exchange spills or outright parallel deadlocks.
Merge Joins were a mistake.
Hash Join
Ah, Hash Joins. Old Glory. Supporters of Adaptive Joins and Batch Mode, and non-requirers of ordered inputs.
Hail To The Hash, baby.
That isn’t to say that they’re perfect. You typically want to see them in reporting queries, and you typically don’t want to see them in OLTP queries. Sometimes they’re a sign that of a lack of indexing in the latter case.
There are all sorts of neat little details about Hash Joins, too. I am endlessly fascinated by them.
Take bitmaps, for example. In parallel row mode plans, they’re way out in the open. In batch mode plans, they’re only noted in the hash join operator, where you’ll see the BitmapCreator property set to true. In serial row mode plans, they get even weirder. They’re always there, they’re always invisible, and there’s no way to visually detect them.
Semi Joins and Anti-Semi Joins
You may see these applied to any of the above types of joins, which are a bit different from inner, outer, full, and cross joins in how they accept or reject rows.
They’ll usually show up when you use
- EXISTS
- NOT EXISTS
- INTERSECT
- EXCEPT
Where they differ is in their:
- Treatment of duplicate matches
- Treatment of NULLs
- Ability to accept or reject rows at the join
Both EXISTS and NOT EXISTS stop looking once they find their first match. They do not produce duplicates in one to many relationships.
NOT EXISTS doesn’t get confused by NULLs the way that NOT IN does, and both INTERSECT and EXCEPT handle NULLs differently than equality predicates.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is the way you really need to learn about joins! Thank you very much
Aw, thanks! Glad you liked it.