Just A Friend
Missing index requests aren’t perfect, and that’s okay. But you need to know where they’re not okay so you can start creating better ones.
Let’s start with some basics:
- They really only care about the where clause
- Joins always seem to end up in the INCLUDE list
- Column suggestions are not in any particular order
- Outside of being grouped into equality and inequality predicates
- The impact is based on operator costs, which is often complete crap
There’s more, but this is a good start. Good starts are good. Nice things are nice.
And of course, the day this blog published, Microsoft published a huge update to missing index docs, by way of the fabulous Kendra Little.
Let’s move on.
Users
The Users table looks like this. It’s important for me to show you this up front, because column ordinal position in the table is important for understanding missing index requests.
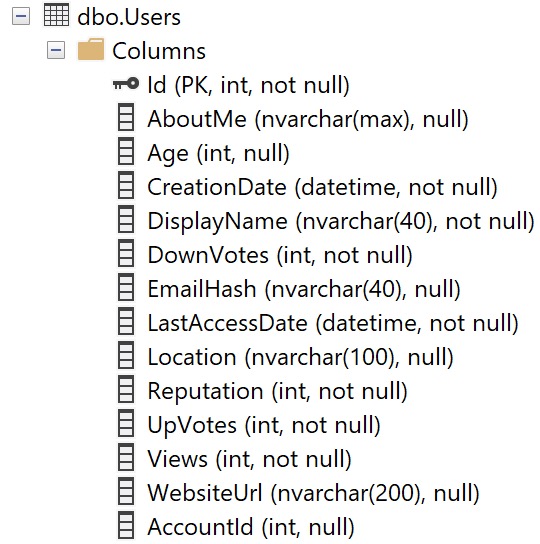
Keep this in mind — the columns aren’t in alphabetical order, or how selective they are, or by data type, etc.
They’re in the order that they are when the table was created, and then if any of them were added later on.
That’s all.
Long Time
Let’s take this query:
SELECT TOP (10000)
u.Id,
u.AccountId,
u.DisplayName,
u.Reputation,
u.Views,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Views = 0
ORDER BY u.CreationDate DESC;
Is it very useful? No. But it’ll help us paint the right picture. The query plan doesn’t matter, because it’s just a clustered index scan, and it’ll be a clustered index scan for every other permutation, too.
The missing index for this query is like so:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Users] ([Views]) INCLUDE ([CreationDate],[DisplayName],[Reputation],[AccountId])
Only the Views column is in the key of the index, even though CreationDate is an order by column.
In this case, it would be beneficial to have it as the second key column, because it would be sorted for free for us after an equality predicate.
You may also notice that Id is not part of the definition too. That’s because it’s the clustered index, so it will be inherited by any nonclustered indexes we create.
Normal
Okay, now let’s look at this query, with a slightly different where clause:
SELECT TOP (10000)
u.Id,
u.AccountId,
u.DisplayName,
u.Reputation,
u.Views,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Views = 0
AND u.Reputation = 1
ORDER BY u.CreationDate DESC;
We’re adding another predicate on Reputation = 1 here. The missing index request now looks like this:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Users] ([Reputation],[Views]) INCLUDE ([CreationDate],[DisplayName],[AccountId])
Neither one of these predicates is particularly selective (7,954,119 and 6,197,417, respectively) but Reputation ends up first in the key column list because its ordinal position in the table is first.
Frequency
How about if we add a really selective predicate to our query?
SELECT TOP (10000)
u.Id,
u.AccountId,
u.DisplayName,
u.Reputation,
u.Views,
u.CreationDate
FROM dbo.Users AS u
WHERE u.AccountId = 12462842
AND u.Views = 0
ORDER BY u.CreationDate DESC;
Now our missing index request looks like this:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Users] ([Views],[AccountId])
Two things happened:
- We don’t have any included columns anymore
- AccountId is second in the key columns
This is amusing because the missing index request machine seems to understand that this will only ever one row via the equality predicate on AccountId but it still gets enumerated as the second index key column.
In other words, it doesn’t put the most selective column first. It gives you an index designed, like other examples, based on the column’s ordinal position in the table.
Nothing else, at least not so far.
Inequality
Where missing index requests will change column order is when it comes to inequality predicates. That doesn’t just mean not equal to, oh no no no.
That covers any “range” predicate: <, <=, >, >=, <> or !=, and IS NOT NULL.
Take this query for example:
SELECT TOP (10000)
u.Id,
u.AccountId,
u.DisplayName,
u.Reputation,
u.Views,
u.CreationDate
FROM dbo.Users AS u
WHERE u.AccountId = 0
AND u.Reputation < 0
AND u.Views < 0
ORDER BY u.CreationDate DESC;
The missing index request looks like this:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Users] ([AccountId],[Reputation],[Views])
Now AccountId is the leading key column, but Reputation and Views are still in ordinal position order as inequality predicates.
Wink Wink
Now, look, I started off by saying that missing index requests aren’t perfect, and that’s okay. They’re not meant to replace a well-trained person. They’re meant to help the hapless when it comes to fixing slow queries.
As you get more comfortable with indexes and how to create them to make queries go faster, you’ll start to see deficiencies in missing index requests.
But you don’t want the optimizer spending a long time in the index matching/missing index request phases. That’s a bad use of its time.
As you progress, you’ll start treating missing index requests like a crying baby: something might need attention, but it’s up to you as an adult DBA or developer to figure out what that is.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
“As you progress, you’ll start treating missing index requests like a crying baby: something might need attention, but it’s up to you as an adult DBA or developer to figure out what that is.”
Nice analogy
HAHAHA, thanks!