Like All Assumptions
You and Me might feel like the lower back end of a thing if we’re tuning a query that has other problems. Perhaps it’s running on one of those serverless servers with half a hyper-threaded core and 8kb of RAM, as an example.
When I’m working with clients, I often get put into odd situations that limit what I’m allowed to do to fix query performance. Sometimes code comes from an ORM or vendor binaries that can’t be changed, sometimes adding an index on a sizable table on standard edition in the middle of the day is just an impossibility, and of course other times things are just a spectacle du derrière that I’m allowed to do whatever I want. You can probably guess which one I like best.
This post is about the two other ones, where you’re stuck between derrière and ânesse.
For the duration of reading this, make the wild leap of faith that it takes to embrace the mindset that not everyone who works with SQL Server knows how to write good queries or design good indexes.
I know, I know. Leap with me, friends.
The Query And Execution Plan
Here’s what we’re starting with:
SELECT TOP (10)
DisplayName =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE u.Id = p.OwnerUserId
),
p.AcceptedAnswerId,
p.CreationDate,
p.LastActivityDate,
p.ParentId,
p.PostTypeId,
p.Score,
p.CommentCount,
VoteCount =
(
SELECT
COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
)
FROM dbo.Posts AS p
ORDER BY
p.Score DESC;
And resulting plan:

We can surmise a few things from this plan:
- If there are good indexes, SQL Server isn’t using them
- That hash spill is some extra kind of bad news
- Spools remain a reliable indicator that something is terribly wrong
Okay, so I’m kidding a bit on the last point. Sorta.
The Query Plan Details
You might look at all this work that SQL Server is doing and wonder why: With no good, usable indexes, and such big tables, why in the overly-ambitious heck are we doing all these nested loop joins?
And the answer, my friend, is blowing in the row goal.
The TOP has introduced one here, and it has been applied across the all of the operators along the top of the plan.
Normally, a row goal is when the optimizer places a bet on it being very easy to locate a small number of rows and produces an execution plan based on those reduced costs.
In this case, it would be 10 rows in the Posts table that will match the Users table and the Votes table, but since these are joins of the left outer variety they can’t eliminate results from the Posts table.
The row goals do make for some terrible costing and plan choices here, though.

orange = no row goal applied
This all comes from cardinality estimation and costing and all the other good stuff that the optimizer does when you throw a query at it.
The Query Rewrite
One way to show the power of TOPs is to increase and then decrease the row goal. For example, this (on my machine, at this very moment in time, given many local factors) will change the query plan entirely:
SELECT TOP (10)
p.*
FROM
(
SELECT TOP (26)
DisplayName =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE u.Id = p.OwnerUserId
),
p.AcceptedAnswerId,
p.CreationDate,
p.LastActivityDate,
p.ParentId,
p.PostTypeId,
p.Score,
p.CommentCount,
VoteCount =
(
SELECT
COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
)
FROM dbo.Posts AS p
ORDER BY
p.Score DESC
) AS p
ORDER BY
p.Score DESC;
You may need to toggle with the top a bit to see the change on your machine. The resulting plan looks a bit funny. You won’t normally see two TOPs nuzzling up like this.

But the end result is an improvement by a full minute and several seconds.
Because the inner TOP has a bigger row goal, the optimizer changes its mind about how much effort it will have to expend to fully satisfy it before clenching things down to satisfy the smaller TOP.
If you’re only allowed quick query rewrites, this can be a good way to get a more appropriate plan for the amount of work required to actually locate rows at runtime, when the optimizer is dreadfully wrong about things.
The Index Rewrite
In this case, just indexing the Votes table is enough to buy us all the performance we need, but in my personal row goal for completeness, I’m going to add in two indexes:
CREATE INDEX
v
ON dbo.Votes
(PostId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
p
ON dbo.Posts
(Score DESC, OwnerUserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Going back to the original query, we no longer need to play games with the optimizer and pitting TOPs against each other.
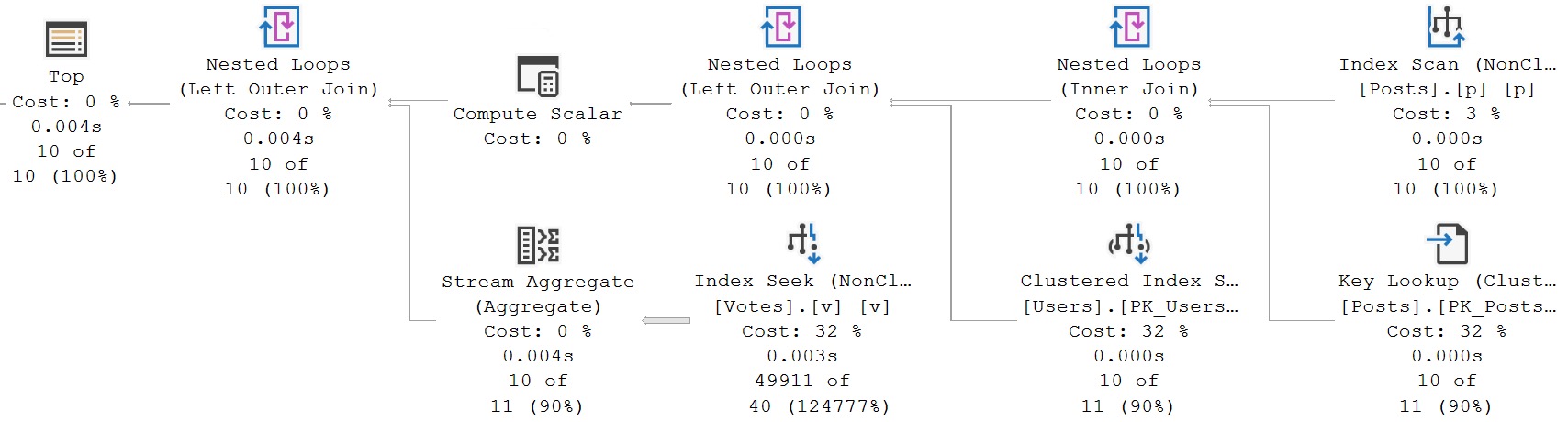
This is obviously much faster, if you’re in the enlightened and enviable position to create them.
Perhaps you are, but maybe not in the exact moment that you need to fix a performance problem.
In those cases, you may need to use rewrites to get temporary performance improvements until you’re able to.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
2 thoughts on “Two Ways To Tune A Slow Query In SQL Server”
Comments are closed.