If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Why Performance Tuners Need To Use The Right Type Of Join In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
User Experience Under Different Isolation Levels In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Loops, Transactions, and Transaction Log Writes In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
ED: I moved up this post’s publication date after Mr. O posted this question. So, Dear Brent, if you’re reading this, you can consider it my humble submission as an answer.
It’s really not up my alley. I love performance tuning SQL Server, but occasionally things like this come up.
Sort of recently, a client really wanted a way to figure out if support staff was manipulating data in a way that they shouldn’t have. Straight away: this method will not track if someone is inserting data, but inserting data wasn’t the problem. Data changing or disappearing was.
The upside of this solution is that not only will it detect who made the change, but also what data was updated and deleted.
It’s sort of like auditing and change data capture or change tracking rolled into one, but without all the pesky stuff that comes along with auditing, change tracking, or change data capture (though change data capture is probably the least guilty of all the parties).
Okay, so here are the steps to follow. I’m creating a table from scratch, but you can add all of these columns to an existing table to get things working too.
Robby Tables
First, we create a history table. We need to do this first because there will be computed columns in the user-facing tables.
/*
Create a history table first
*/
CREATE TABLE
dbo.things_history
(
thing_id int NOT NULL,
first_thing nvarchar(100) NOT NULL,
original_modifier sysname NOT NULL,
/*original_modifier is a computed column below, but not computed here*/
current_modifier sysname NOT NULL,
/*current_modifier is a computed column below, but not computed here*/
valid_from datetime2 NOT NULL,
valid_to datetime2 NOT NULL,
INDEX c_things_history CLUSTERED COLUMNSTORE
);
I’m choosing to store the temporal data in a clustered columnstore index to keep it well-compressed and quick to query.
Next, we’ll create the user-facing table. Again, you’ll probably be altering an existing table to add the computed columns and system versioning columns needed to make this work.
/*Create the base table for the history table*/
CREATE TABLE
dbo.things
(
thing_id int
CONSTRAINT pk_thing_id PRIMARY KEY,
first_thing nvarchar(100) NOT NULL,
original_modifier AS /*a computed column, computed*/
ISNULL
(
CONVERT
(
sysname,
ORIGINAL_LOGIN()
),
N'?'
),
current_modifier AS /*a computed column, computed*/
ISNULL
(
CONVERT
(
sysname,
SUSER_SNAME()
),
N'?'
),
valid_from datetime2
GENERATED ALWAYS AS
ROW START HIDDEN NOT NULL,
valid_to datetime2
GENERATED ALWAYS AS
ROW END HIDDEN NOT NULL,
PERIOD FOR SYSTEM_TIME
(
valid_from,
valid_to
)
)
WITH
(
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.things_history,
HISTORY_RETENTION_PERIOD = 7 DAYS
)
);
A couple things to note: I’m adding the two computed columns as non-persisted, and I’m adding the system versioning columns as HIDDEN, so they don’t show up in user queries.
The WITH options at the end specify which table we want to use as the history table, and how long we want to keep data around for. You may adjust as necessary.
I’m tracking both the ORIGINAL_LOGIN() and the SUSER_SNAME() details in case anyone tries to change logins after connecting to cover their tracks.
Inserts Are Useless
Let’s stick a few rows in there to see how things look!
SELECT
table_name =
'dbo.things',
t.thing_id,
t.first_thing,
t.original_modifier,
t.current_modifier,
t.valid_from,
t.valid_to
FROM dbo.things AS t;
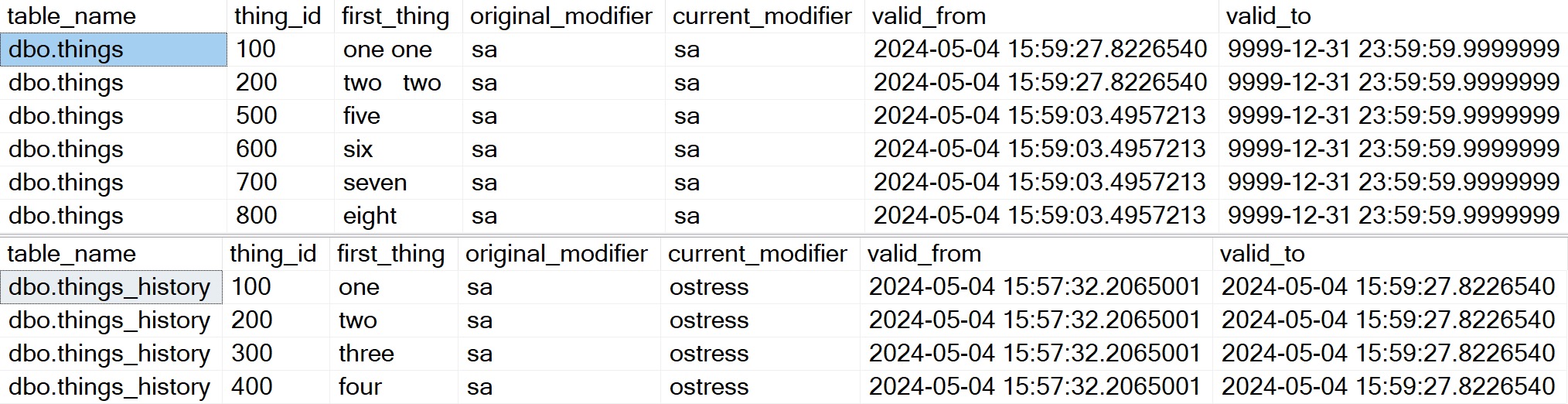
The results won’t make a lot of sense. Switching back and forth between the sa and ostress users, the original_modifier column will always say sa, and the current_modifier column will always show whichever login I’m currently using.
You can’t persist either of these columns, because the functions are non-deterministic. In this way, SQL Server is protecting you from yourself. Imagine maintaining those every time you run a different query. What a nightmare.
The bottom line here is that you get no useful information about inserts, nor do you get any useful information just by querying the user-facing table.
Updates And Deletes Are Useful
Keeping my current login as ostress, let’s run these queries:
UPDATE
t
SET
t.first_thing =
t.first_thing +
SPACE(1) +
t.first_thing
FROM things AS t
WHERE t.thing_id = 100;
UPDATE
t
SET
t.first_thing =
t.first_thing +
SPACE(3) +
t.first_thing
FROM things AS t
WHERE t.thing_id = 200;
DELETE
t
FROM dbo.things AS t
WHERE t.thing_id = 300;
DELETE
t
FROM dbo.things AS t
WHERE t.thing_id = 400;
Now, along with looking at the user-facing table, let’s look at the history table as well.
To show that the history table maintains the correct original and current modifier logins, I’m going to switch back to executing this as sa.
peekaboo i see you!
Alright, so here’s what we have now!
In the user-facing table, we see the six remaining rows (we deleted 300 and 400 up above), with the values in first_thing updated a bit.
Remember that the _modifier columns are totally useless here because they’re calculated on the fly every time
We also have the history table with some data in it finally, which shows the four rows that were modified as they existed before, along with the user as they logged in, and the user as the queries were executed.
This is what I would brand “fairly nifty”.
FAQ
Q. Will this work with my very specific login scenario?
A. I don’t know.
Q. Will this work with my very specific set of permissions?
A. I don’t know.
Q. But what about…
A. I don’t know.
I rolled this out for a fairly simple SQL Server on-prem setup with very little insanity as far as login schemes, permissions, etc.
You may find edge cases where this doesn’t work, or it may not even work for you from the outset because it doesn’t track inserts.
With sufficient testing and moxie (the intrinsic spiritual spark, not the sodie pop) you may be able to get it work under you spate of local factors that break the peace of my idyllic demo.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Since I first started reading about indexes, general wisdom has been to design the key of your indexes to support the most restrictive search predicates first.
I do think that it’s a good starting place, especially for beginners, to get acceptable query performance. The problem is that many databases end up designed with some very non-selective columns that are required for just about every query:
Soft deletes, where most rows are not deleted
Status columns, with only a handful of potential entries
Leaving the filtered index question out for the moment, I see many tables indexed with the “required” columns as the first key column, and then other (usually) more selective columns further along in the key. While this by itself isn’t necessarily a bad arrangement, I’ve seen many local factors lead to it contributing to bad performance across the board, with no one being quite sure how to fix it.
In this post, we’ll look at both an index change and a query change that can help you out in these situations.
Schema Stability
We’re going to start with two indexes, and one constraint.
CREATE INDEX
not_posts
ON dbo.Badges
(Name, UserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
not_badges
ON dbo.Posts
(PostTypeId, OwnerUserId)
INCLUDE
(Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
ALTER TABLE
dbo.Posts
ADD CONSTRAINT
c_PostTypeId
CHECK
(
PostTypeId > 0
AND PostTypeId < 9
);
GO
The index and constraint on the Posts table are the most important. In this case, the PostTypeId column is going to play the role of our non-selective leading column that all queries “require” be filtered to some values.
You can think of it mentally like an account status, or payment status column. All queries need to find a particular type of “thing”, but what else the search is for is up to the whims and fancies of the developers.
A Reasonable Query?
Let’s say this is our starting query:
SELECT
DisplayName =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE u.Id = b.UserId
),
ScoreSum =
SUM(p.Score)
FROM dbo.Badges AS b
CROSS APPLY
(
SELECT
p.Score,
n =
ROW_NUMBER() OVER
(
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = b.UserId
AND p.PostTypeId < 3
) AS p
WHERE p.n = 0
AND b.Name IN (N'Popular Question')
GROUP BY
b.UserId;
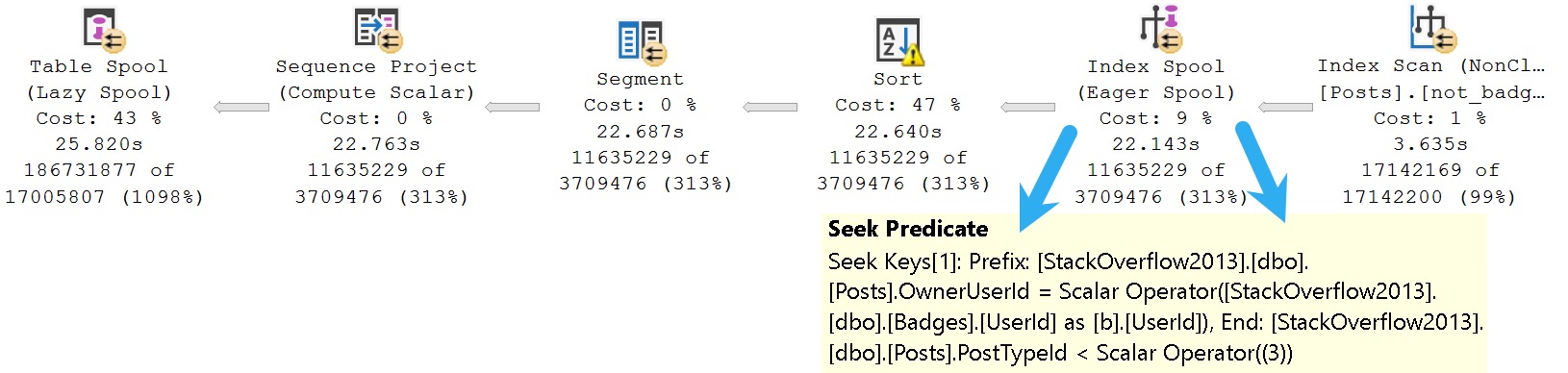
Focusing in on the CROSS APPLY section where the Posts table is queried, our developer has chosen to look for PostTypeIds 1 and 2 with an inequality predicate. Doing so yields the following plan, featuring an Eager Index Spool as the villain.
i came to drop crumbs
SQL Server decided to scan our initial index and create a new one on the fly, putting the OwnerUserId column first, and the Score column second in the key of the index. That’s the reverse of what we did.
Leaving aside all the icky internals of Eager Index Spools, one can visually account for about 20 full seconds of duration spent on the effort.
Query Hints To The Rescue?
I’ve often found that SQL Server’s query optimizer is just out to lunch when it chooses to build an Eager Index Spool, but in this case it was the right choice.
If we change the query slightly to use a hint (FROM dbo.Posts AS p WITH(FORCESEEK)) we can see what happens when we use our index the way Codd intended.
It is unpleasant. I allowed the query to execute for an hour before killing it, not wanting to run afoul of my laptop’s extended warranty.
The big problem of course is that for each “seek” into the index, we have to read the majority of the rows across two boundaries (PostTypeId 1 and PostTypeId 2). We can see that using the estimated plan:
in this case, < 3 is not a heart.
Because our seek crosses range boundaries, the predicate on OwnerUserId can’t be applied as an additional Seek predicate. We’re left applying it as a residual predicate, once for PostTypeId 2, and once for PostTypeId 1.
The main problem is, of course, that those two ranges encompass quite a bit of data.
If you have many ill-performing queries, you may want to consider changing the order of key columns in your index to match what would have been spooled:
CREATE INDEX
not_badges_x
ON dbo.Posts
(OwnerUserId, PostTypeId)
INCLUDE
(Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
This gets rid of the Eager Index Spool, and also the requirement for a FORCESEEK hint.
satisfaction
At this point, we may need to contend with the Lazy Table Spool in order to get across the finish line, but we may also consider getting a query from ~30 seconds down to ~4 seconds adequate.
Of course, you may just have one query suffering this malady, so let’s look at a query rewrite that also solves the issue.
Optimizer Inflexibility
SQL Server’s query optimizer, for all its decades of doctors and other geniuses working on it, heavily laden with intelligent query processing features, still lacks some basic capabilities.
With a value constraint on the table telling the optimizer that all data in the column falls between the number 1 and 8, it still can’t make quite a reasonable deduction: Less than 3 is the same thing as 1 and 2.
Why does it lack this sort of simple knowledge that could have saved us so much trouble? I don’t know. I don’t even know who to ask anymore.
But we can do it! Can’t we? Yes! We’re basically optimizer doctors, too.
With everything set back to the original two indexes and check constraint, we can rewrite the where clause from PostTypeId < 3 to PostTypeId IN(1, 2).
If we needed to take extraordinary measures, we could even use UNION ALL two query against the Posts table, with a single equality predicate for 1 and 2.
Doing this brings query performance to just about equivalent with the index change:
good and able
The main upside here is the ability for the optimizer to provide us a query plan where there are two individual seeks into the Posts table, one for PostTypeId 1, with an additional seek to match OwnerUserId, and then one additional seek for PostTypeId 2, with an additional seek to match OwnerUserId.
coveted
This isn’t always ideal, of course, but in this case it gets the job fairly well done.
Plan Examiner
Understanding execution plans is sometimes quite a difficult task, but learning what patterns to look for can save you a lot of standing about gawping at irrelevancies.
The more difficult challenge is often taking what you see in an execution plan, and knowing what options you have available to adjust them for better performance.
In some cases, it’s all about establishing better communication with the optimizer. In this post, I used a small range (less than 3) as an example. Many dear and constant readers might find the idea that someone would write that over a two value IN clause ridiculous, but I’ve seen it. I’ve also seen it in more reasonable cases for much larger ranges.
It’s good to understand that the optimizer doesn’t have infinite tricks available to interpret your query logic into the perfect plan. Today we saw that it was unable to change < 3 to = 1 OR = 2, and you can bet there are many more such reasonable simplifications that it can’t apply, either.
Anyway, good luck out there. If you need help with these things, the links in the below section can help you get it from me.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Why Read Committed Queries Can Still Return Bad Results In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Kendra and I both taught solo precons, and got to talking about how much easier it is to manage large crowds when you have a little helper with you, and decided to submit two precons this year that we’d co-present.
Amazingly, they both got accepted. Cheers and applause. So this year, we’ll be double-teaming Monday and Tuesday with a couple pretty cool precons.
You can register for PASS Summit here, taking place live and in-person November 4-8 in Seattle.
Here are the details!
Day One: A Practical Guide to Performance Tuning Internals
Whether you’re aiming to be the next great query tuning wizard or you simply need to tackle tough business problems at work, you need to understand what makes a workload run fast– and especially what makes it run slowly.
Erik Darling and Kendra Little will show you the practical way forward, and will introduce you to the internal subsystems of SQL Server with a practical guide to their capabilities, weaknesses, and most importantly what you need to know to troubleshoot them as a developer or DBA.
They’ll teach you how to use your understanding of the database engine, the storage engine, and the query optimizer to analyze problems and identify what is a nothingburger best practice and what changes will pay off with measurable improvements.
With a blend of bad jokes, expertise, and proven strategies, Erik and Kendra will set you up with practical skills and a clear understanding of how to apply these lessons to see immediate improvements in your own environments.
Day Two: Query Quest: Conquer SQL Server Performance Monsters
Picture this: a day crammed with fun, fascinating demonstrations for SQL Server and Azure SQL.
This isn’t your typical training day; this session follows the mantra of “learning by doing,” with a good dose of the unexpected. Think of this as a SQL Server video game, where Erik Darling and Kendra Little guide you through levels of weird query monsters and performance tuning obstacles.
By the time we reach the final boss, you’ll have developed an appetite for exploring the unknown and leveled up your confidence to tackle even the most daunting of database dilemmas.
It’s SQL Server, but not as you know it—more fun, more fascinating, and more scalable than you thought possible.
Going Further
We’re both really excited to deliver these, and have BIG PLANS to have these sessions build on each other so folks who attend both days have a real sense of continuity.
Of course, you’re welcome to pick and choose, but who’d wanna miss out on either of these with accolades like this?
pretty, pretty, pretty, pretty good
You can register for PASS Summit here, taking place live and in-person November 4-8 in Seattle.
See you there!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Here’s a breakdown of changes you can find in the most recent releases!
sp_QuickieStore
Here’s what got fixed and added in this round of changes:
Fixed a big where execution count and other metrics were being underreported
Fixed a bug when checking for AG databases would throw an error in Azure SQLDB and Managed Instance (Thanks to AbhinavTiwariDBA for reporting)
Added the IGNORE_DUP_KEY option to a couple temp table primary keys that could potentially see duplicate values when certain parameter combinations are used (Thanks to ReeceGoding for reporting)
Added support for displaying plan XML when plans have > 128 nested nodes of XML in them (you can’t open them directly, but you can save and reopen them as graphical plans)
Added underscores to the “quotable” search characters, so they can be properly escaped
So now we don’t have to worry about any of that stuff. How nice. How nice for us.
sp_PressureDetector
Here’s what got fixed and added in this round of changes:
Fixed an issue in the disk metrics diffing where some data types weren’t explicit
Fixed a bunch of math issues in the disk diff, too (it turns out I was missing a useful column, doh!)
Fixed a bug in the “low memory” XML where I had left a test value in the final query
Added information about memory grant caps from Resource Governor (with a small hack for Standard Edition)
Turns out I’m not great at math, and sometimes I need to think a wee bit harder. Not at 4am, though.
sp_HumanEventsBlockViewer
Here’s what got fixed and added in this round of changes:
Added a check for COMPILE locks to the analysis output
Added a check for APPLICATION locks to the analysis output
Improved the help section to give blocked process report and extended event commands
Improved indexing for the blocking tree code recursive CTE
Moved contentious object name resolution to an update after the initial insert
The final one was done because when there’s a lot of data in the blocked process report, this query could end up being pretty slow. Why, you might ask? Because calling OBJECT_ID() in the query forces a serial plan.
Fun stuff.
Issues and Contributions
If you’d like to report an issue, request or contribute a feature, or ask a question about any of these procedures, please use my GitHub repo. Specifically, check out the contributing guide.
As happy as I am to get emails about things, it makes support difficult for the one-man party that I am. Personal support costs money. Public support is free. Take your pick, there!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.