If the Gods of post scheduling cooperate, this should publish on October 3rd. That means you’ve got a little more than a month to buy tickets and book travel to PASS.
Searching the internet for every problem isn’t cutting it.
You need to be more proactive and efficient when it comes to finding and solving database performance fires. I work with consulting customers around the world to put out SQL Server performance fires.
In this day of learning, I will teach you how to find and fix your worst SQL Server problems using the same modern tools and techniques which I use every week.
You’ll learn tons of new and effective approaches to common performance problems, how to figure out what’s going on in your query plans, and how indexes really work to make your queries faster.
Together, we’ll tackle query rewrites, batch mode, how to design indexes, and how to gather all the information you need to analyze performance.
This day of learning will teach you cutting edge techniques which you can’t find in training by folks who don’t spend time in the real world tuning performance.
Performance tuning mysteries can easily leave you stumbling through your work week, unsure if you’re focusing on the right things.
You’ll walk out of this class confident in your abilities to fix performance issues once and for all.
If you want to put out SQL Server performance fires, this is the precon you need to attend. Anyone can have a plan, it takes a professional to have a blueprint.
In-person attendees will also get a cool t-shirt. Arguably the coolest t-shirt ever made for a SQL Server conference.
big eight
Dates And Times
The PASS Data Community Summit is taking place in Seattle November 15-18, 2022 and online.
You can register here, to attend online or in-person. I’ll be there in all my fleshy goodness, and I hope to see you there too!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Defining things scares people. Pause for a moment to think about how many scripts have been written where some roustabout has a mental breakdown when someone refers to them as a boyfriend or girlfriend.
Table definitions have a similar effect on developers. In today’s post, I’m going to use temp tables as an example, but the same thing can happen with regular tables, too.
The issue isn’t with NULL values themselves, of course. The table definition we’re going to use will allow NULLs, but no NULLs will be present in the data.
The issue is with how you query NULLable columns, even when no NULLs are present.
Let’s take a look!
Insecure
Let’s create a temporary table that allows for NULLs, and fill it with all non-NULL values.
CREATE TABLE
#comment_sil_vous_plait
(
UserId int NULL
);
INSERT
#comment_sil_vous_plait WITH(TABLOCK)
(
UserId
)
SELECT
c.UserId
FROM dbo.Comments AS c
WHERE c.UserId IS NOT NULL;
Unfortunately, this is insufficient for SQL Server’s optimizer down the line when we query the table.
But we need one more table to round things out.
Brilliant
This temporary table will give SQL Server’s optimizer all the confidence, temerity, and tenacity that it needs.
CREATE TABLE
#post_sil_vous_plait
(
OwnerUserId int NOT NULL
);
INSERT
#post_sil_vous_plait WITH(TABLOCK)
(
OwnerUserId
)
SELECT
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL;
Just three tiny letters. N-O-T.
That’s all it takes.
The Queries
If you’ve been hanging around SQL Server for long enough, you’re probably aware of what happens when you use NOT IN and encounter NULL values in your tables.
It says “nope” and gives you an empty result (or a NULL result!) because you can’t match values to NULLs that way.
SELECT
c = COUNT_BIG(*)
FROM #post_sil_vous_plait AS psvp
WHERE psvp.OwnerUserId NOT IN
(
SELECT
csvp.UserId
FROM #comment_sil_vous_plait AS csvp
);
SELECT
c = COUNT_BIG(*)
FROM #post_sil_vous_plait AS psvp
WHERE NOT EXISTS
(
SELECT
1/0
FROM #comment_sil_vous_plait AS csvp
WHERE csvp.UserId = psvp.OwnerUserId
);
But since we have no NULLs, well, we don’t have to worry about that.
But we do have to worry about all the stuff SQL Server has to do to see if any NULLs come up.
The Plans
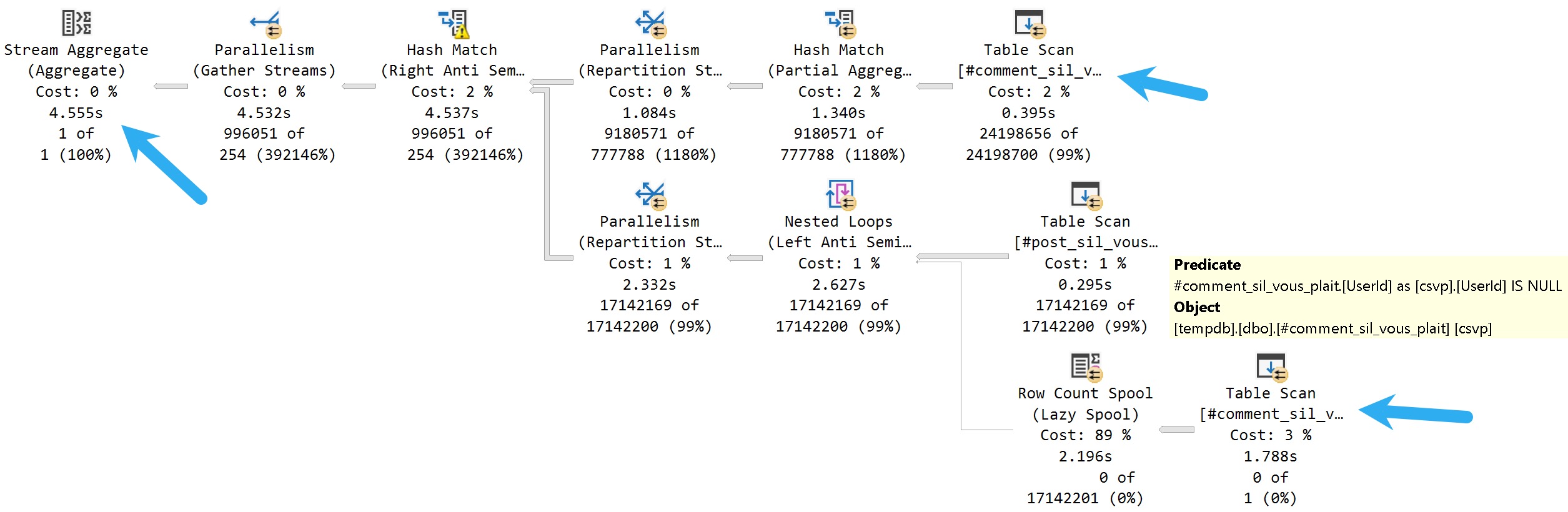
For the NOT IN query, which runs about 4.5 seconds, there are two separate scans of the #comments table.
yuck
Most of this query plan is expected. There’s a scan of #comments, a scan of #posts, and a hash join to bring them together.
But down below, there’s an additional branch with a row count spool, and a predicate applied to the scan looking for NULL values. The spool doesn’t return data, it’s just there to look for a NULL value and bail the query out if it finds one.
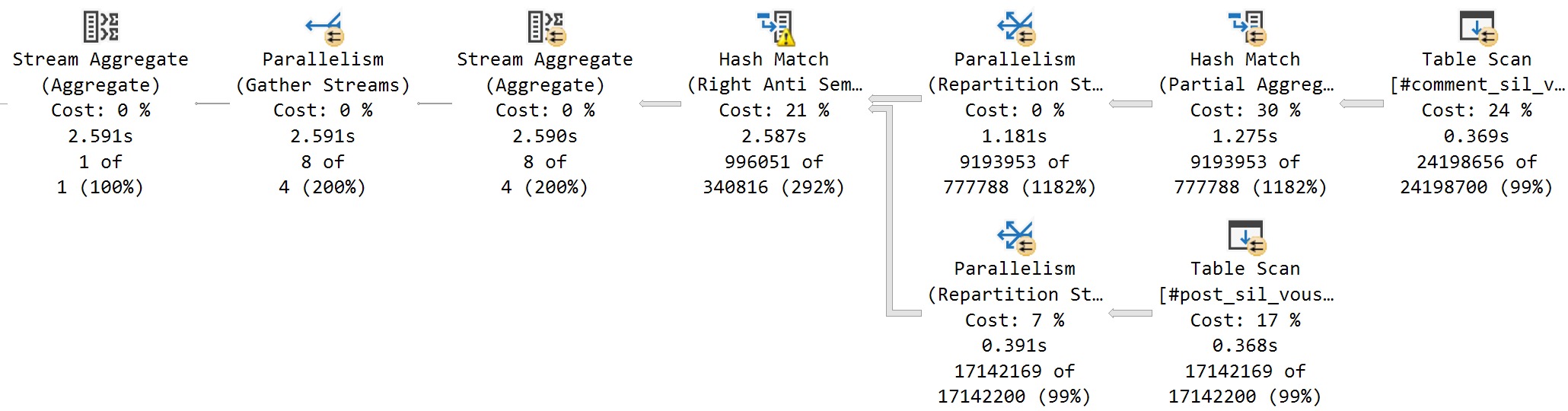
For the NOT EXISTS query, which finishes in 2.5 seconds, we have all the expected parts of the above query plan, but without the spool.
flawless
You could partially solve performance issues in both queries by sticking a clustered index on both tables.
If you’re into that sort of thing (I am).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
In yesterday’s post, I showed you a function rewrite from Scalar to Inline Table Valued, and gave you a couple example calls.
Now, if this is all you’re doing with a function, there’s absolutely no need to rewrite them.
SELECT
cl.*
FROM dbo.CountLetters('1A1A1A1A1A') AS cl;
SELECT
CountLetters =
dbo.CountLetters_Bad('1A1A1A1A1A');
If you’re doing something like this, and maybe assigning it to a variable or using it to guide some branching logic, don’t you sweat it for one single solitary second.
You may want to make sure whatever code inside the function runs well, but changing the type of function here isn’t going to improve things.
More realistically, though, you’re going to be calling functions as part of a larger query.
Second To None
Let’s say you’re doing something a bit like this:
SELECT
u.DisplayName,
TotalScore =
SUM(p.Score * 1.),
Thing =
dbo.CountLetters_Bad(u.DisplayName)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE p.Id = v.PostId
)
AND u.Reputation >= 100000
GROUP BY
u.DisplayName
ORDER BY
TotalScore DESC;
It’s a far different scenario than just assigning the output of a Scalar UDF to a variable or using it to guide some branching logic.
Brooklyn Zoo
A few minor syntax changes to the function and to how the query calls it can make a big difference.
SELECT
u.DisplayName,
TotalScore =
SUM(p.Score * 1.),
Thing =
(SELECT * FROM dbo.CountLetters(u.DisplayName))
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE p.Id = v.PostId
)
AND u.Reputation >= 100000
GROUP BY
u.DisplayName
ORDER BY
TotalScore DESC;
Since this is a table valued function, you have to ask for results from it like you’d ask for results from a table.
As long as someone wins who you’re rooting for. But here, no one’s rooting for scalar functions. They’re just unlovable.
I’m going to show you the very end of these plans to see the timing differences.
1945
The Scalar UDF plan takes ~23 seconds, and the inline TVF plan takes 7.5 seconds.
And this is why testing certain linguistic elements in SQL needs to be done realistically. Just testing a single value would never reveal performance issues.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Hopefully those requirements are met. There may be a more romantic way of following the rules, but I’m not very good at either one.
No one has ever accused me of sending flowers.
Waste Management
If you write the good kind of dynamic SQL, that is:
Parameterized
Executed with sp_executesql
You’ll probably have run into some silly-ish errors in the practice. Namely, that sp_executesql expects your SQL string and your Parameter string to be NVARCHAR(…).
Msg 214, Level 16, State 2, Procedure sys.sp_executesql, Line 1 [Batch Start Line 0]
Procedure expects parameter ‘@statement’ of type ‘ntext/nchar/nvarchar’.
The thing is, if you write complex enough branching dynamic SQL with many paths, you have to:
Declare the initial variable as nvarchar(probably max)
Prefix every new string concatenation with N to retain unicodeness
IF @1 = 1 BEGIN SET @sql += N'...' END;
IF @2 = 2 BEGIN SET @sql += N'...' END;
IF @3 = 3 BEGIN SET @sql += N'...' END;
IF @4 = 4 BEGIN SET @sql += N'...' END;
IF @5 = 5 BEGIN SET @sql += N'...' END;
And that’s just… tough. If you miss one, your string could go all to the shape of pears. Curiously, the last time I wrote for a T-SQL Tuesday, it was also about dynamic SQL.
So what’s up this time?
Spanning
If you know that no part of your string is going to contain unicode characters that need to be preserved, it is easier to do something like this:
DECLARE
@nsql nvarchar(MAX) = N'',
@vsql varchar(MAX) = 'SELECT x = 1;';
IF @1 = 1 BEGIN SET @sql += '...' END;
IF @2 = 2 BEGIN SET @sql += '...' END;
IF @3 = 3 BEGIN SET @sql += '...' END;
IF @4 = 4 BEGIN SET @sql += '...' END;
IF @5 = 5 BEGIN SET @sql += '...' END;
SET @nsql = @vsql;
EXEC sys.sp_executesql
@nsql;
GO
No worrying about missing an N string prefix, and then set the nvarchar parameter to the value of the varchar string at the end, before executing it.
This can save a lot of time, typing, and debugging.
Concerns
Where you have to be careful is when you may have Unicode characters in identifiers:
DECLARE
@nsql nvarchar(MAX) = N'',
@vsql varchar(MAX) = 'SELECT p = ''アルコール'';'
SET @nsql = @vsql;
EXEC sys.sp_executesql
@nsql;
GO
This will select five question marks. That’s not good. We lost our Unicodeness.
But you are safe when you have them in parameters, as long as you declare them correctly as nvarchar:
This will select アルコール and we’ll all drink happily ever after.
Trunk Nation
One side piece of advice that I would happily give Young Erik, and all of you, is not to rely on data type inheritance to preserve MAX-ness.
As you concatenate strings together, it’s usually a smart idea to keep those strings pumped up:
DECLARE
@nsql nvarchar(MAX) = N'',
@vsql varchar(MAX) = 'SELECT x = 1;';
IF @1 = 1 BEGIN SET @sql += CONVERT(varchar(max), '...') END;
IF @2 = 2 BEGIN SET @sql += CONVERT(varchar(max), '...') END;
IF @3 = 3 BEGIN SET @sql += CONVERT(varchar(max), '...') END;
IF @4 = 4 BEGIN SET @sql += CONVERT(varchar(max), '...') END;
IF @5 = 5 BEGIN SET @sql += CONVERT(varchar(max), '...') END;
SET @nsql = @vsql;
EXEC sys.sp_executesql
@nsql;
GO
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
In this case, more efficient doesn’t necessarily mean faster. You still have this complete unit of work to get through.
The whole point is to go a little bit easier on your server:
Smaller transactions sent to the log file
Shorter locking durations
Less build up of the version store (optimistic isolation levels, triggers, etc.)
But there are thing that make batching impossible, or downright tricky.
Atom Bomb
Let’s say you need to update 10 million rows, and you’re using batches of 5000 rows.
What happens when one batch throws an error?
If you were running the whole thing as a single query, the whole thing would roll back. Depending on how far along you’ve gotten, that could be pretty painful (especially for you suckers that don’t have Accelerated Database Recovery enabled).
That also kind of sucks… depending on the error, too. Not all of them mean the update violated some database rule you’ve set up via constraints.
But all that aside, there are some circumstances where maybe the entire thing should fail and roll back.
In those cases, you’ll need something that keeps track of the “before” rows. There are ways to do this within SQL Server that don’t require you to program anything:
Change Data Capture
Change Tracking
Temporal Tables
If you can afford to use those, it might be a pretty “easy” way of tracking changes to your data so that you can roll it back.
But it’s up to you to write code that uses any of those things to find the old values and do the ol’ natty switcheroo.
Batchy Bomb
It is possible to save off all the rows you’ve change to another table, and then reverse the changes.
/*Batch update with output*/
-- From https://michaeljswart.com/2014/09/take-care-when-scripting-batches/
DECLARE
@LargestKeyProcessed int = -1,
@NextBatchMax int,
@RC int = 1;
WHILE (@RC > 0)
BEGIN
/*Starting place*/
SELECT
@NextBatchMax =
MAX(x.id)
FROM
(
SELECT TOP (1000)
aia.id
FROM dbo.as_i_am AS aia
WHERE aia.id >= @LargestKeyProcessed
ORDER BY
aia.id ASC
) AS x;
/*Updateroo*/
UPDATE
aia
SET aia.some_date =
DATEADD(YEAR, 1, aia.some_date),
aia.some_string =
aia.some_string + LEFT(aia.some_string, 1)
OUTPUT
Deleted.id, Deleted.some_date, Deleted.some_string
INTO
dbo.as_i_was (id, some_date, some_string)
FROM dbo.as_i_am AS aia
WHERE aia.id >= @LargestKeyProcessed
AND aia.id <= @NextBatchMax;
/*Enhance*/
SET @RC = @@ROWCOUNT;
SET @LargestKeyProcessed = @NextBatchMax;
END;
The only thing I’m doing different here, aside from my own tables, is using OUTPUT to dump the prior row versions into a new table.
That way, if a batch fails, I can roll things back.
Witch Errors
One thing that you should figure out is which errors you want to guard against. Lock and deadlock errors are common ones.
You can do something like this:
DECLARE
@do_over tinyint = 0,
@game_over tinyint = 5;
WHILE
@do_over <= @game_over
BEGIN
BEGIN TRY
SET NOCOUNT, XACT_ABORT ON;
UPDATE dbo.as_i_am SET some_string = REPLICATE('ack', 1) WHERE id = 138; /*do a thing*/
BREAK; /*exit loop if thing is successful*/
END TRY
BEGIN CATCH
IF ERROR_NUMBER() IN (1204, 1205, 1222) /*lock and deadlock errors*/
BEGIN
SELECT
@do_over += 1;
WAITFOR DELAY '00:00:10';
END;
ELSE
BEGIN;
/*log some details to a table here*/
THROW;
END;
END CATCH;
END;
This is somewhat incomplete pseudo code, but it looks good enough to blog. Don’t judge me too harshly, just use it to get where you need to go.
Other errors, like primary key, foreign key, constraint, string truncation, and others that indicate data quality issues shouldn’t be retried.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If the Gods of post scheduling cooperate, this should publish on October 3rd. That means you’ve got a little more than a month to buy tickets and book travel to PASS.
Searching the internet for every problem isn’t cutting it.
You need to be more proactive and efficient when it comes to finding and solving database performance fires. I work with consulting customers around the world to put out SQL Server performance fires.
In this day of learning, I will teach you how to find and fix your worst SQL Server problems using the same modern tools and techniques which I use every week.
You’ll learn tons of new and effective approaches to common performance problems, how to figure out what’s going on in your query plans, and how indexes really work to make your queries faster.
Together, we’ll tackle query rewrites, batch mode, how to design indexes, and how to gather all the information you need to analyze performance.
This day of learning will teach you cutting edge techniques which you can’t find in training by folks who don’t spend time in the real world tuning performance.
Performance tuning mysteries can easily leave you stumbling through your work week, unsure if you’re focusing on the right things.
You’ll walk out of this class confident in your abilities to fix performance issues once and for all.
If you want to put out SQL Server performance fires, this is the precon you need to attend. Anyone can have a plan, it takes a professional to have a blueprint.
In-person attendees will also get a cool t-shirt. Arguably the coolest t-shirt ever made for a SQL Server conference.
big eight
Dates And Times
The PASS Data Community Summit is taking place in Seattle November 15-18, 2022 and online.
You can register here, to attend online or in-person. I’ll be there in all my fleshy goodness, and I hope to see you there too!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thing that comes up pretty often when you ask for an actual execution plan, is that the query “never finishes” and one can’t be captured.
Good news! There are ways for you to get execution plans in progress with some of the actual query plan elements inside.
You don’t have to let the query run to completion, but generally if you give it a few minutes you can capture where things are going wrong.
Longer is usually better, but I understand that some queries are real crushers, and cause big server problems.
Option None: Live Query Plans
The problem with Live Query Plans is that they’re really unreliable. Many times I’ve tried to use them and the Live Plan never shows up, and worse I’ll be unable to close the SSMS tab without killing the process in Task Manager.
When it does work, it can be sort of confusing. Here’s a completed query with Live Plans enabled:
nope.
It took about 49 seconds, but… What took 49 seconds? Repartition Streams? Clustered Index Scan? Something else?
Here’s another really confusing one:
means of deduction
Apparently everything took three minutes and thirty six seconds.
Good to know.
Screw these things.
Option One: Get Plans + sp_WhoIsActive
Good ol’ sp_WhoIsActive will check to see if you have the right bits and views in your SQL Server, and return in-progress actual plans to you.
To do that, it looks at dm_exec_query_statistics_xml. That’s SQL Server 2016 and up, for those of you playing along at home. Hopefully you have it installed at home, because you sure don’t at work.
But anyway, if you enable either Actual Execution plans, OR Live Query Plans, and then run sp_WhoIsActive in another window, you’ll get much more sensible plans back. Usually.
udderly
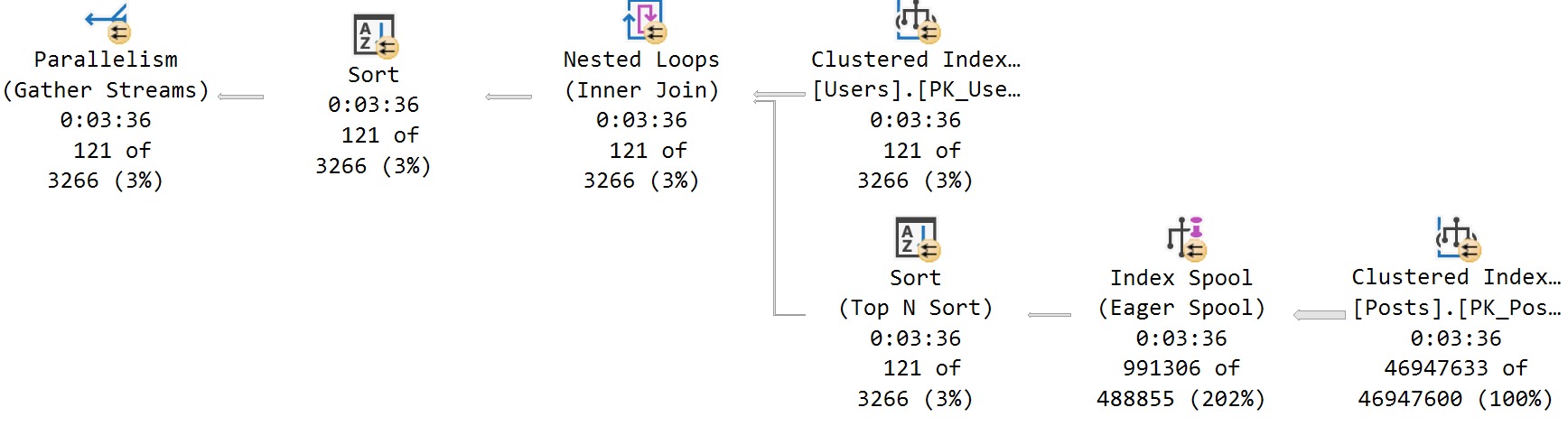
This accurately shows where time is spent in the query, which is largely in the scan of the Posts table.
Where There’s Still A Prioblem
Where things fall apart is still when a spool is built. If you can follow along a bit…
not even almost
The top query plan shows time accurately distributed amongst operators, from the Actual Plan run to completion
The bottom query plan shows time quite inaccurately, getting the plan from dm_exec_query_statistics_xml after the query had been running for three minutes
I guess the bottom line is if you see an Eager Index Spool in your query plan, you should fix that before asking any questions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
The thing is… It should be a lot easier than that. Unfortunately, when you tell SSMS that you want to get actual execution plans, it gives you absolutely everything.
For code that loops or has a lot of tiny queries that run leading up to more painful queries. All that is a slog, and can result in SSMS becoming unresponsive or crashing.
It’s be really cool if hitting the Actual Execution Plan button filter out some stuff so you’re not collecting everything.
It could even use the same GUI style as Extended Events.
in england
Granted, not all the ones pictured here would make sense, but metrics like CPU and duration would be helpful to keep noisy query plans out of the picture.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I spend a lot of time talking about this with clients, because so many of them face dire blocking and deadlocking issues across a variety of queries under the Read Committed isolation level, that can be easily solved by switching to Read Committed Snapshot Isolation.
There seems to be quite a bit of misconception about isolation levels, particularly optimistic ones in SQL Server. In the most unfortunate of circumstances, optimistic isolation levels are bundled in with Read Uncommitted/NOLOCK as being able to read dirty data.
To make the differences clear, here’s how things shake out across a few of SQL Server’s isolation levels I see most commonly.
Note that I’m not including Repeatable Read, Serializable, or Snapshot Isolation. I’ll talk about why as we go through things a bit here.
While it is tempting to use the Read Uncommitted isolation level to avoid some common blocking and deadlocking scenarios, that isolation level comes with a steep price: your queries are subject to every kind of dirty read imaginable.
By the time you realize that your queries have produced bad data, it’s far too late.
read dirty to me
That brings us to Read Committed, which is the default isolation level in SQL Server, except in Azure SQL DB. In that cloud version of SQL Server, Read Committed Snapshot Isolation is the default isolation level.
Read Committed seems like a decent compromise between not returning awful, incorrect data, until you realize that your read queries can block, be blocked by, and deadlock with modification queries. This will typically happen in queries that take object level shared locks, which queries using Read Uncommitted/NOLOCK will not do. Nor will queries operating under an optimistic isolation level, like Read Committed Snapshot Isolation, or Snapshot Isolation.
Read Committed Snapshot Isolation is typically the better of the three options, especially if you prefer correct data being returned to clients.
The final point I’ll make in this section is that writer on writer blocking and deadlocking can occur in every isolation level, even many cases under Snapshot Isolation.
You May Notice
Since I’ve hopefully scared you out of using Read Uncommitted/NOLOCK for your queries, let’s talk about the remaining competitors.
Read Committed and Read Committed Snapshot Isolation have similar traits as to what level of data integrity they guarantee.
The tradeoff comes with a change to the behavior of read queries in the face of data modifications. While readers won’t block or deadlock with modification queries under Read Committed Snapshot Isolation, it’s important to understand how they avoid that while still returning data with some guarantees of correctness.
Since I promised to talk about why I’m not talking about certain isolation levels in this post, let’s do that before we look at Read Committed and Read Committed Snapshot isolation level differences.
Snapshot Isolation: Even though this is my favorite isolation level, it’s usually too hard to apply. Queries have to ask for it specifically. Most of the time, you want every query to benefit with minimal changes.
Repeatable Read: Is sort of like a weaker version of Serializable. I often struggle to explain why it even exists. It’s like all of the blocking with fewer of the guarantees.
Serializable: I very rarely run into scenarios where this is the ideal isolation level. Many times, I find developers using it without knowing via their ORM of choice.
There you. have it. I’m not saying you should never use any of these. They exist for good academic reasons, but practical applications are slim, particularly for Repeatable Read and Serializable.
Let’s create a simple table to muck about with:
CREATE TABLE
dbo.isolation_level
(
id int NOT NULL PRIMARY KEY IDENTITY,
isolation_level varchar(40)
);
INSERT
dbo.isolation_level
(
isolation_level
)
VALUES
('Read Committed'),
('Read Committed Snapshot Isolation');
I’m also going to set my database to use Read Committed Snapshot Isolation, but request Read Committed when the select query runs.
ALTER DATABASE
Crap
SET
READ_COMMITTED_SNAPSHOT ON
WITH
ROLLBACK IMMEDIATE;
Read Committed
Very few people use this isolation level fully in practice. I know you. I see you in the naked light of day.
Your database is set to use this isolation level, but your queries all ask for Read Uncommitted/NOLOCK. Which means… You made bad choices.
Not as bad as the choice Microsoft made in picking Read Committed as the default isolation level, but there we have it. Time to own it.
We’re going to use an equally simple couple queries to demonstrate the differences.
--window one
BEGIN TRAN;
UPDATE il
SET il.isolation_level = 'Read Committed'
FROM dbo.isolation_level AS il
WHERE il.id = 2;
ROLLBACK;
And then:
--window two
SELECT
c = COUNT_BIG(*)
FROM dbo.isolation_level AS il WITH(READCOMMITTEDLOCK)
WHERE il.isolation_level = 'Read Committed';
While the update is running, our select will get blocked.
read committed blah
There go those shared locks, causing problems.
But when the update is finally committed, our query will count 2 rows matching our search on the isolation level column.
If that’s what you absolutely need, then you should use Read Committed, or another more strict isolation level, like Repeatable Read or Serializable.
For most people, if you’re okay with NOLOCK, you’re better off with Read Committed Snapshot Isolation.
Read Committed Snapshot Isolation
If we remove the READCOMMITTEDLOCK hint from the select query and allow it to use versioned rows via Read Committed Snapshot Isolation set at the database level, something different happens.
There’s no blocking to show you. The select finishes instantly. There’s not really a good screenshot of that.
SQL Server takes the version of the row that it knew was good when the update started — the one with Read Committed Snapshot Isolation as the value — and sends that version of the row to the version store.
Again, it is a known, good, committed value for that row. No dirty read nonsense here.
But that means the query returns a result of 1, since only one row qualifies for the where clause filter when we go looking for stuff in the version store.
If you have queries that should rely on reading only committed data from completed modification queries, you can hint them with READCOMMITTEDLOCK to maintain such behavior.
In the same sense, you could use the SNAPSHOT isolation level and only hint certain queries to use it, either by using SET TRANSACTION ISOLATION LEVEL, or adjusting your query’s connection strings to request it.
But that’s a lot harder! You have to go around potentially changing a lot of code to ask for it, or separating queries that you want to use a different isolation level into a different connection string group. I realize that at this point, some of you may be confused here by Microsoft’s awkward naming choices. Snapshot Isolation, and Read Committed Snapshot Isolation, are indeed two different optimistic options for isolation levels.
They are not entirely interchangeable, though either one is generally a better choice than the default isolation level, Read Committed.
Even with the overhead of generating row versions, I’ll take correct results quickly.
Thanks for reading (optimistically)!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Over the past month (plus or minus a couple days), I’ve shown you in a series of quick posts how I use different SQL Server Community Tools that are free and open source to troubleshoot SQL Server issues.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.