An Attempt
One tricky thing about working with dynamic SQL is that it’s rather unaccountable. You have a stored procedure, you build up a string, you execute it, and no one wants to claim responsibility.
Like a secret agent, or an ugly baby.
It would be nice if sp_executesql had an additional parameter to assign an object id to the code block so that when you’re looking at the plan cache or Query Store, you know immediately where the query came from.
Here’s an example.
A Contempt
Let’s use this as an example:
CREATE OR ALTER PROCEDURE dbo.dynamo
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
DECLARE
@sql nvarchar(MAX) = N'';
SELECT TOP (1)
b.*
FROM dbo.Badges AS b
WHERE b.UserId = 22656
ORDER BY b.Date DESC
SELECT
@sql = N'
/*dbo.dynamo*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
';
EXEC sys.sp_executesql
@sql;
END;
GO
This is, by all accounts, Properly Written Dynamic SQL™
I know, this doesn’t need to be dynamic SQL, but I don’t need a great example of that to show what I mean. The first query is there to get the proc to show up anywhere, and the dynamic SQL is there to show you that… dynamic SQL doesn’t show up as associated with the proc that called it.
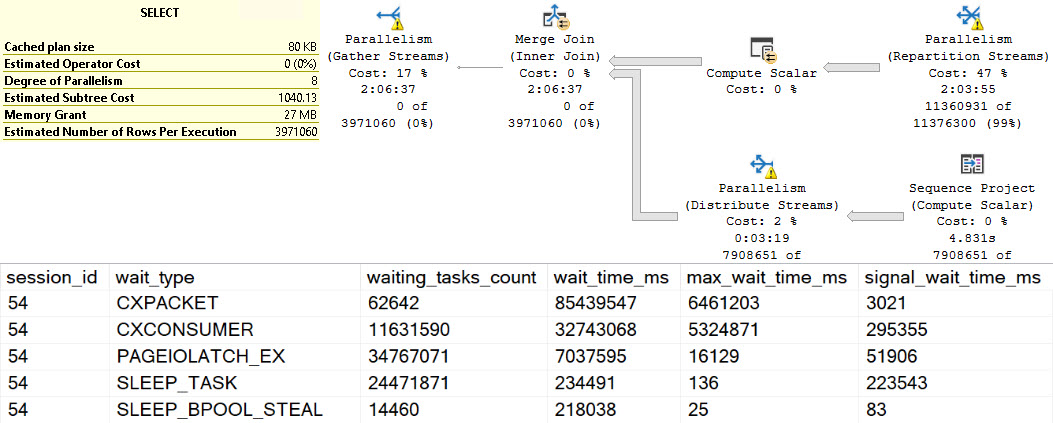
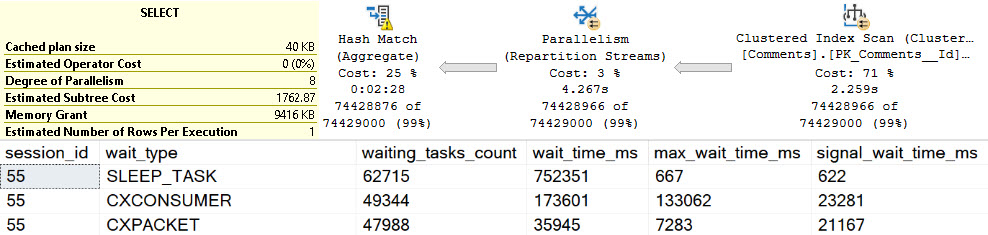
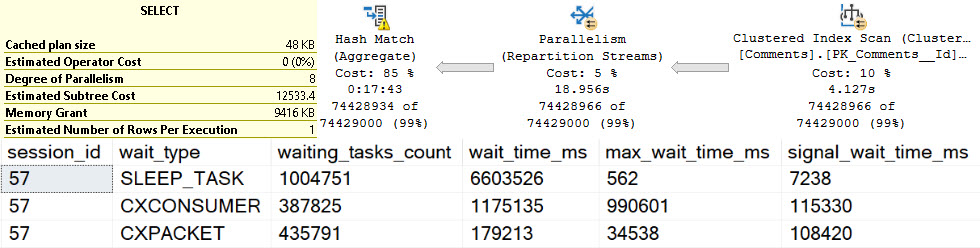
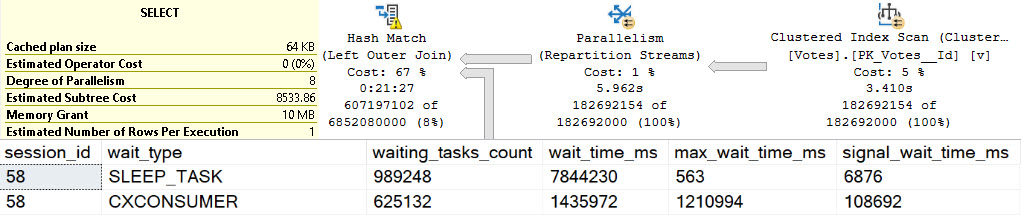
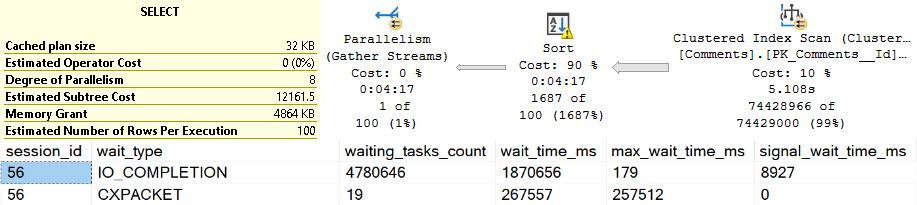
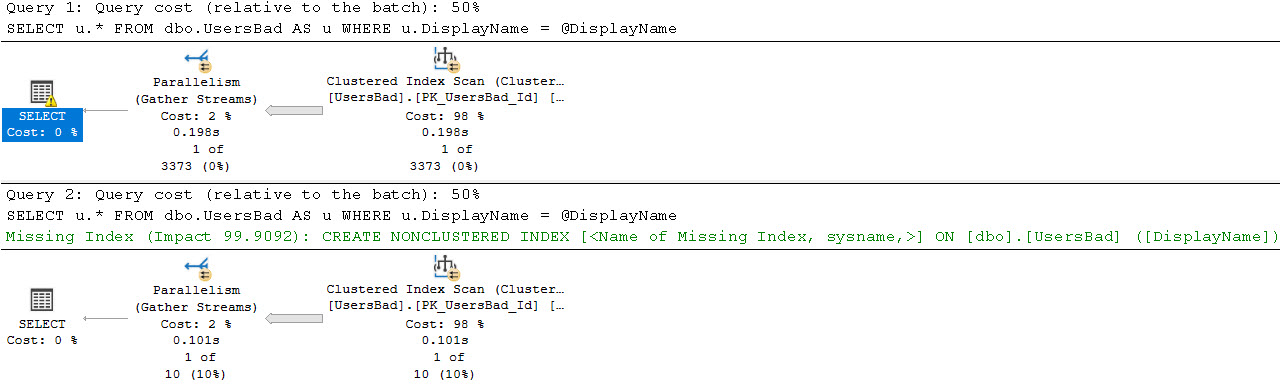
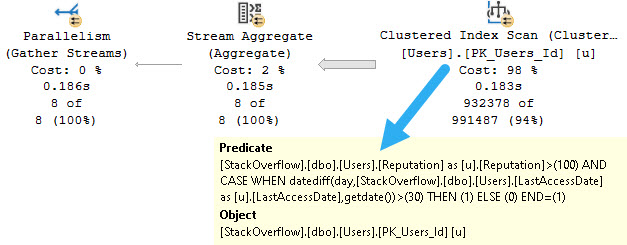
If we execute the proc, and then look for the details of it in Query Store, all we get back it the first query.
EXEC dbo.dynamo;
GO
EXEC sp_QuickieStore
@database_name = 'StackOverflow2013',
@procedure_schema = 'dbo',
@procedure_name = 'dynamo';
GO

It sure would be nice to know that this proc executed a whole other query.
A Temp
There’s no great workaround for this, but you can at least get a hint that something else happened if you dump the dynamic SQL results into a temp table.
CREATE OR ALTER PROCEDURE dbo.dynamo_insert
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
DECLARE
@sql nvarchar(MAX) = N'';
CREATE TABLE
#results
(
c bigint
);
SELECT TOP (1)
b.*
FROM dbo.Badges AS b
WHERE b.UserId = 22656
ORDER BY b.Date DESC
SELECT
@sql = N'
/*dbo.dynamo*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
';
INSERT
#results WITH(TABLOCK)
(
c
)
EXEC sys.sp_executesql
@sql;
SELECT
r.*
FROM #results AS r
END;
GO
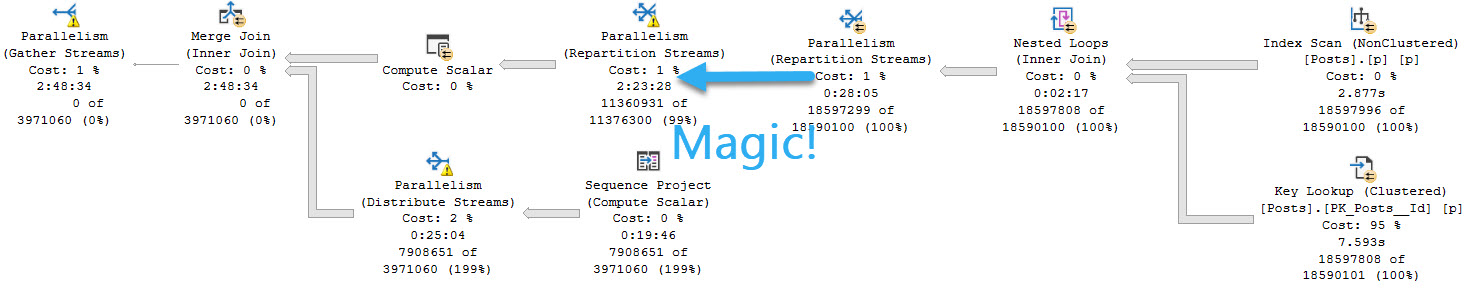
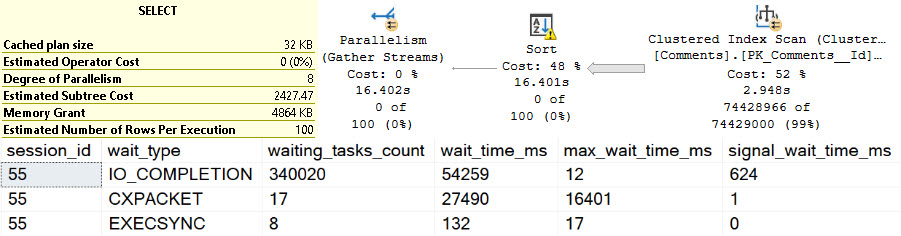
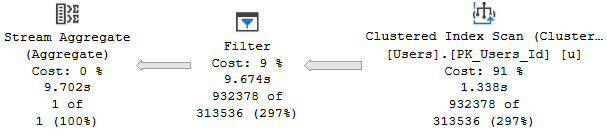
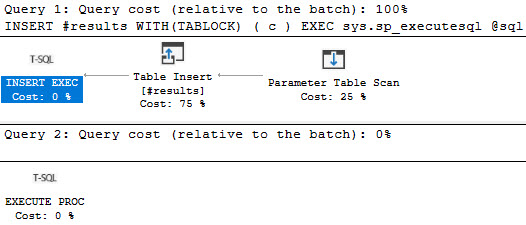
This still sucks though, because we don’t know what the dynamic portion of the query did.

The query plan looks like this, with no real details or metrics:
A Fix
It would be super if sp_executesql took an additional parameter in the context of a stored procedure that could be assigned to a @@PROCID.
EXEC sys.sp_executesql
@sql,
@object_id = @@PROCID;
This would avoid all the headless dynamic SQL horsemen running around, and make it easier to locate procedure statements by searching for the procedure that executes them, rather than having to search a bunch of SQL text for a commented proc name.
Sure, it’s fine if you stumble across dynamic SQL with a comment pointing to the procedure that runs it, but I hardly see anyone doing that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.