Starter Pistol
I started writing this post to answer a different question about if the Parameter Sensitive Plan (PSP) optimization worked with computed columns.
Of course it does! Even non-persisted computed columns have statistics generated on them. The only gatekeeping activity from there is whether or not your statistics qualify for the PSP optimization to kick in.
My excitement for the PSP optimization reminds me of the first time I drank Johnnie Walker Blue. I was all riled up on the hype around a $200 bottle of scotch.
Then it tasted like dessert syrup.
That’s a lot like what seeing this pop up in related Extended Events feels like, even for columns with massive amounts of skew in them.

Microsoft really need to introduce a hint that tells the optimizer to treat a parameter as being sensitive, and/or a way to tweak the threshold for Skewness not being met.
The heuristics are really falling short, here.
Hash And Rehash
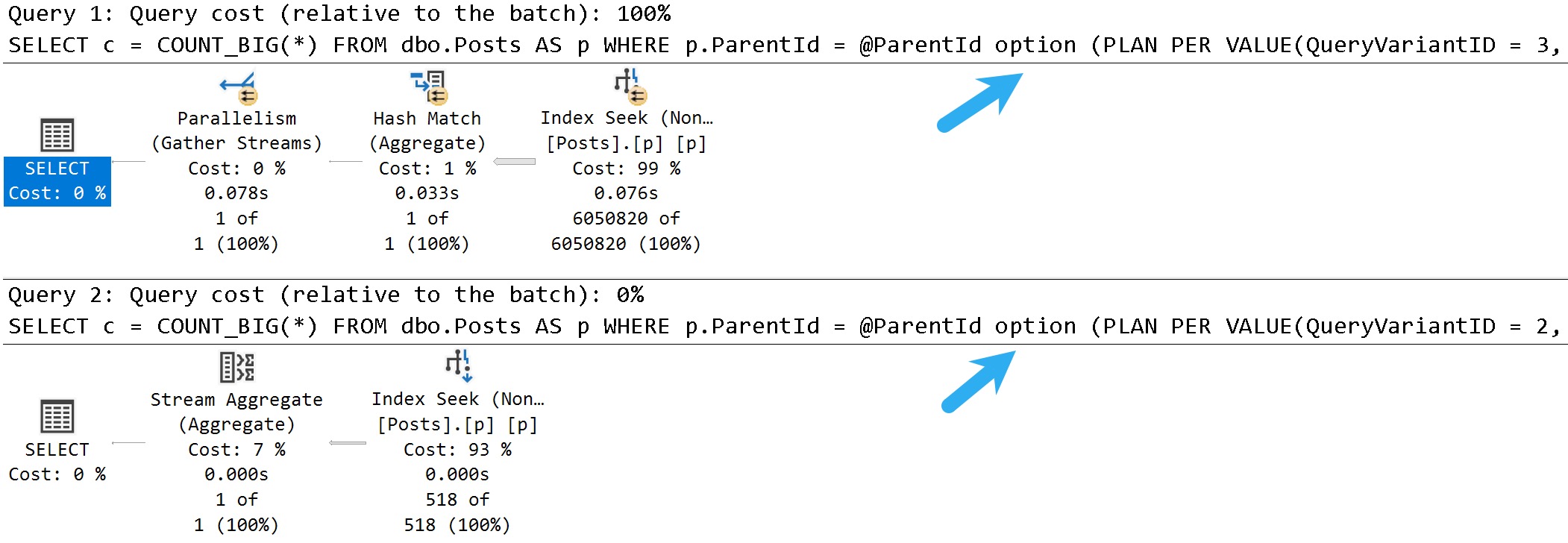
Anyway, let’s use the example that I had started with here, to illustrate that the PSP optimization does work with a computed column, but… like any other column, indexes make all the difference.
I’m using the same example query over and over again, because a lot of the other great examples of parameter sensitivity that I have demo queries written for don’t seem to trigger it.
Here’s the computed column I started with:
ALTER TABLE
dbo.Posts
ADD
WhatIsIt
AS ISNULL
(
ParentId,
0
);
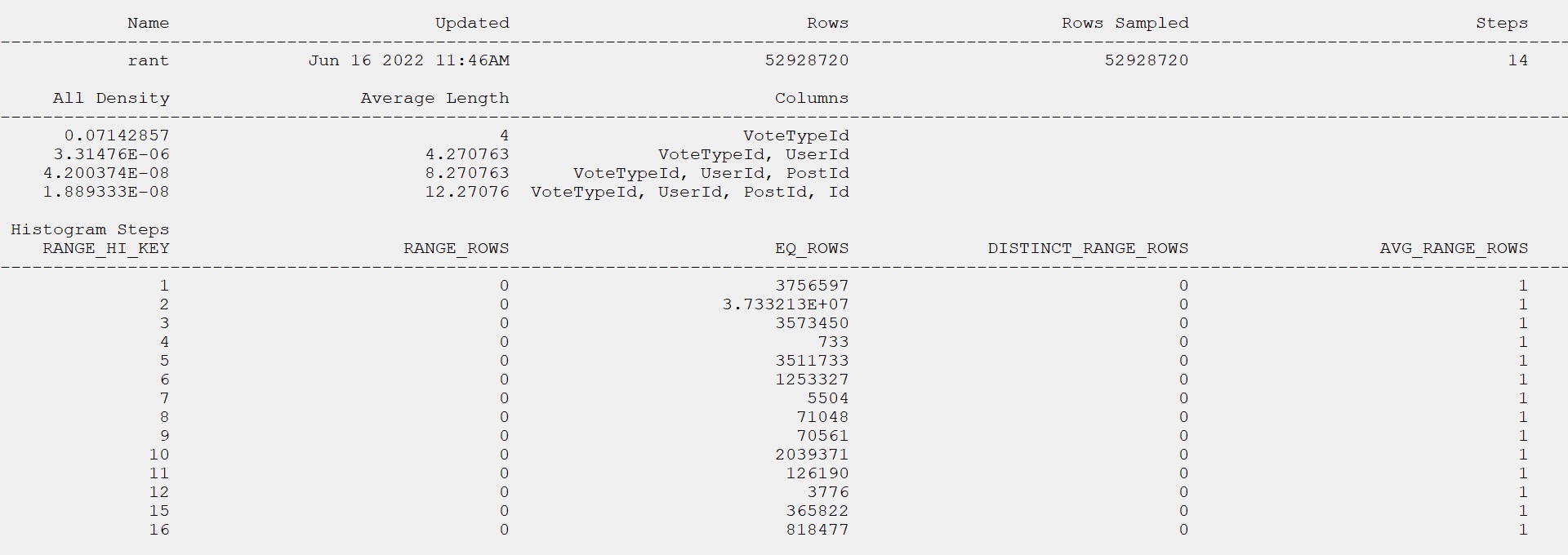
I’m not actually sure that there are NULL values in there, but the column is marked as NULLable so the ISNULL function doesn’t short-circuit.
Here’s the stored procedure we’ll be using:
CREATE OR ALTER PROCEDURE
dbo.FindMeSomePostsPlease
(
@ParentId int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ISNULL(p.ParentId, 0) = @ParentId
END;
Bruise the lard that our optimizer can match expressions on its own.
No Index, No Cry
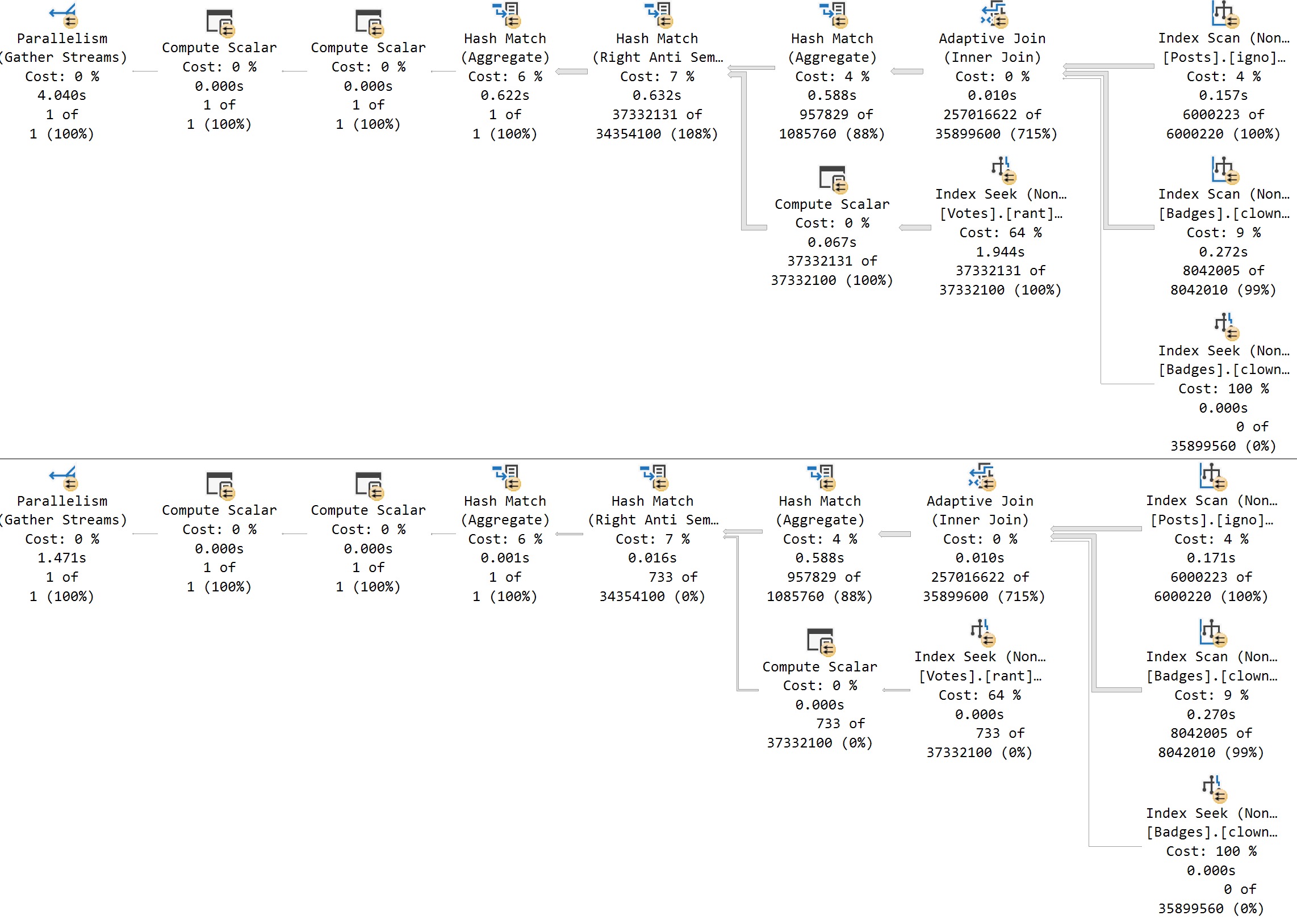
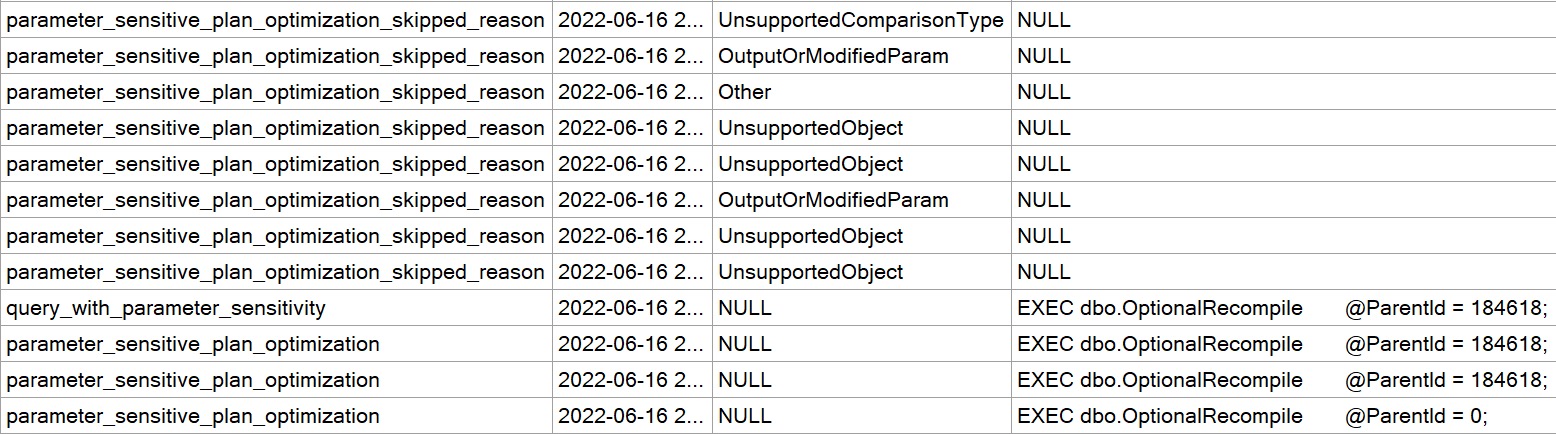
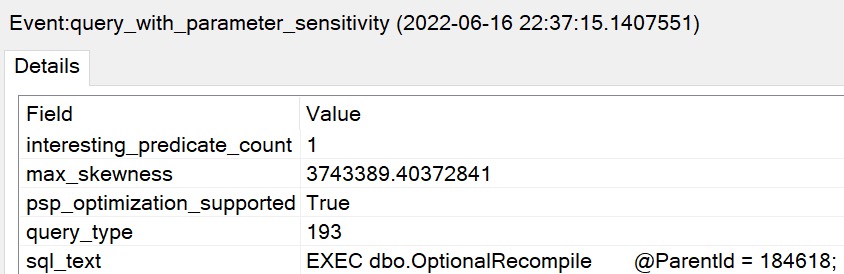
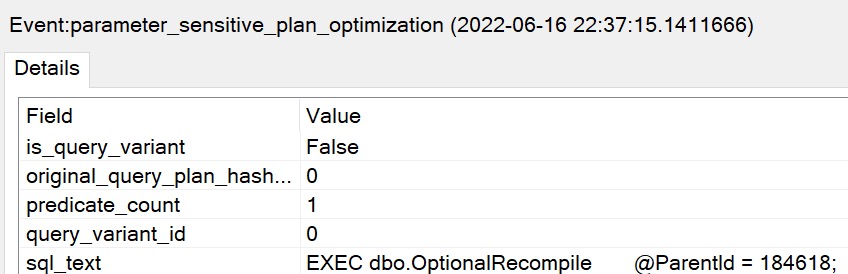
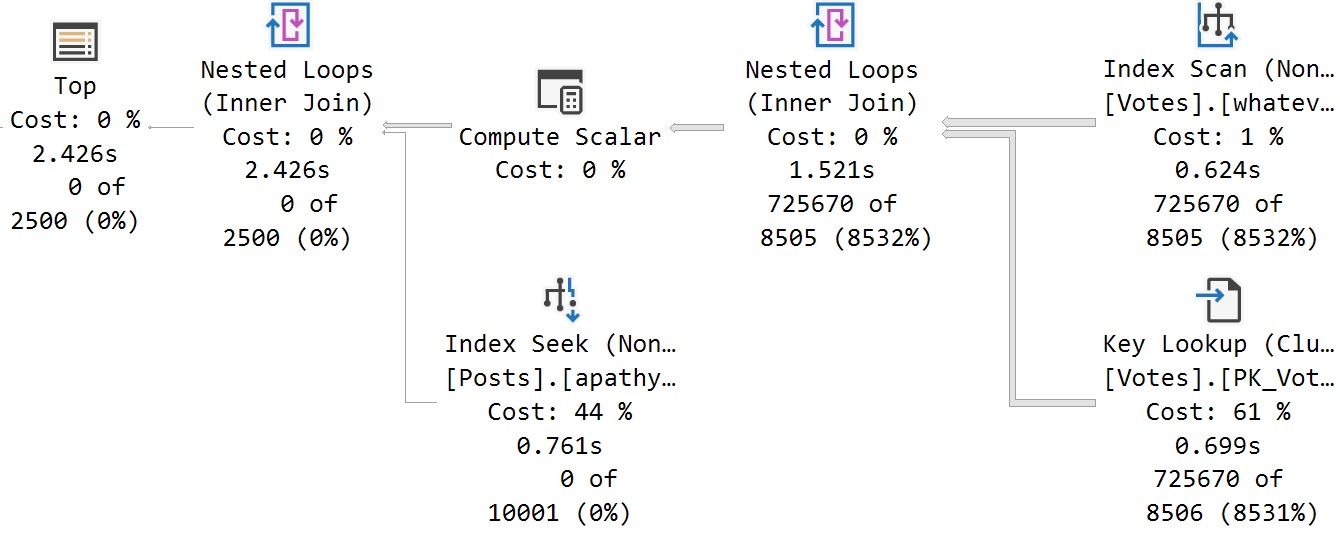
Using the calls that have worked to trigger the PSP optimization in the past, we do not get two important things:
- Different cardinality estimates between executions
- The
option(plan per value...text added to the end of the plan
EXEC dbo.FindMeSomePostsPlease
@ParentId = 0;
EXEC dbo.FindMeSomePostsPlease
@ParentId = 184618;
The plans are expectedly disappointing:

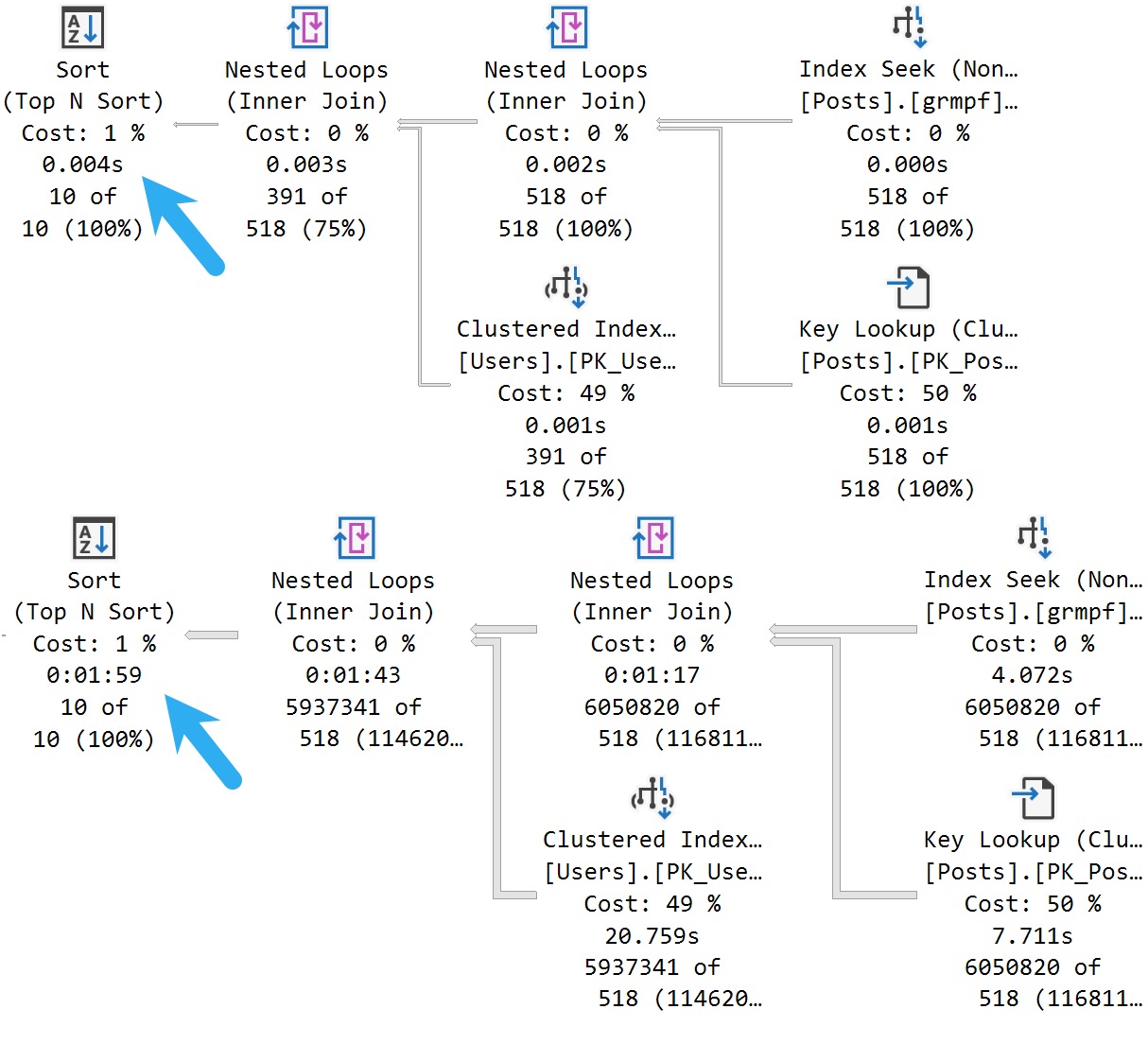
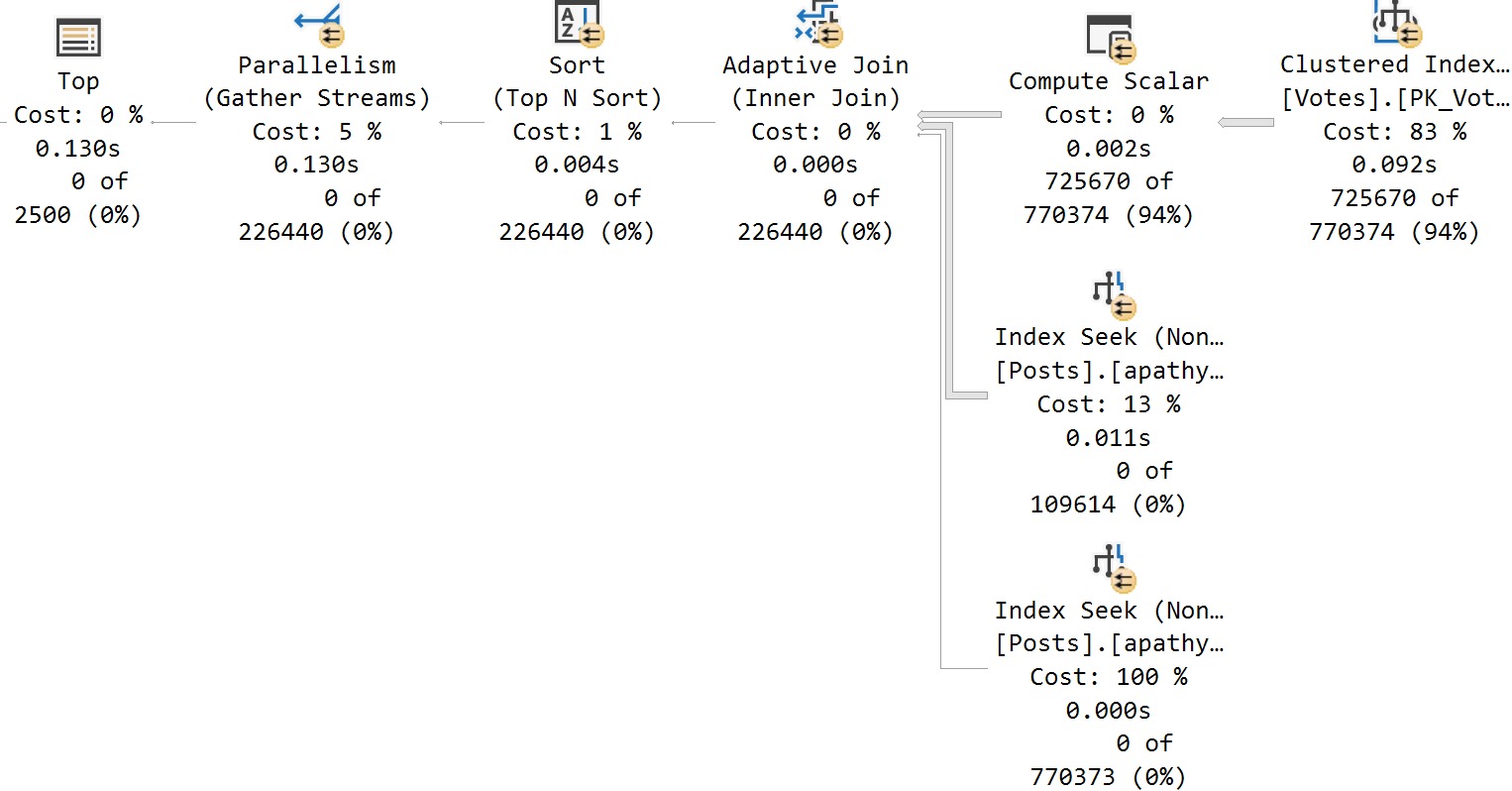
Indexable
With the help of our trusty steed index, we get the PSP optimization:
CREATE INDEX
p
ON dbo.Posts
(
WhatIsIt
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
Granted, this is a toy example, but…
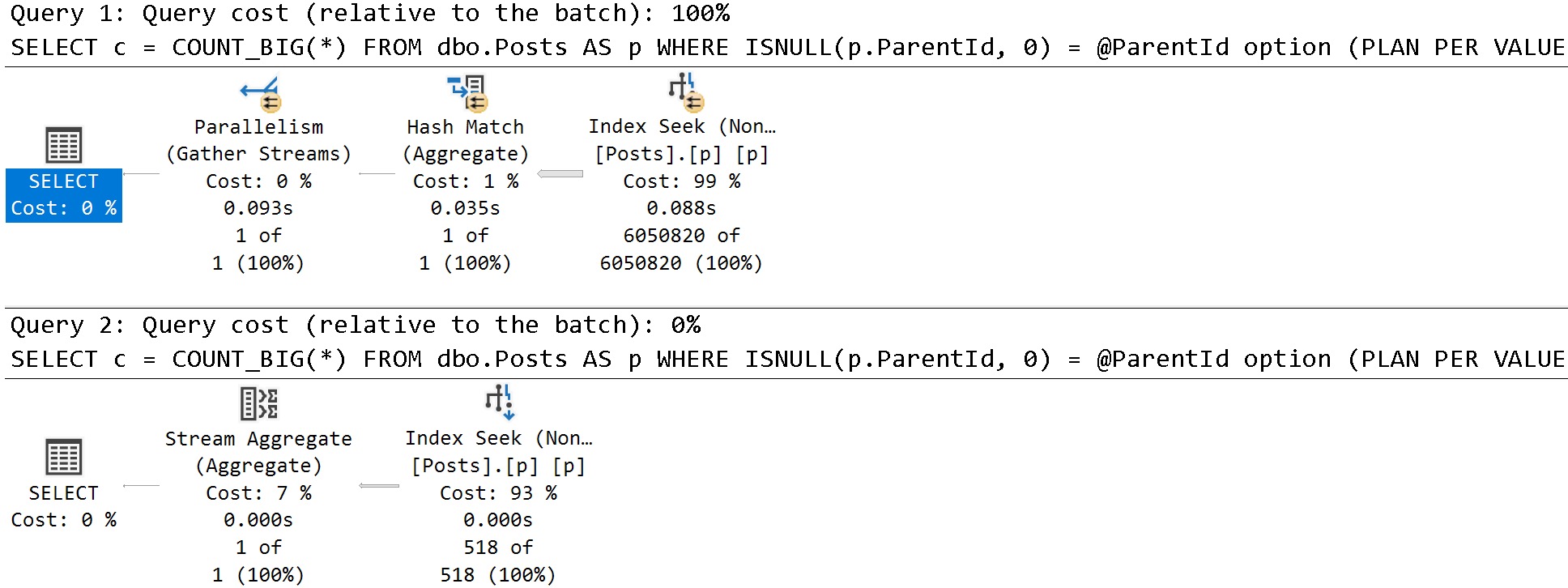
Bottom line: If you want cool new features to (sometimes) work, you’re gonna need to pay attention to indexes.
What Else About Indexes?
Well, two things. In the example above, PSP didn’t kick in until we had one, I think owing to the computed column not being materialized, but…
Sometimes you’ll get PSP without an index, but the plans won’t be much different aside from cardinality estimates
Here’s a quick example.
DECLARE
@sql nvarchar(MAX) = N'',
@po int = 2,
@pa int = 184618
--184618
SELECT
@sql += N'
SELECT TOP (5000)
p.Id,
p.OwnerUserId,
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = @po
AND p.ParentId = @pa
ORDER BY
p.Score DESC;
';
EXEC sys.sp_executesql
@sql,
N'@po int,
@pa int',
@po,
@pa;
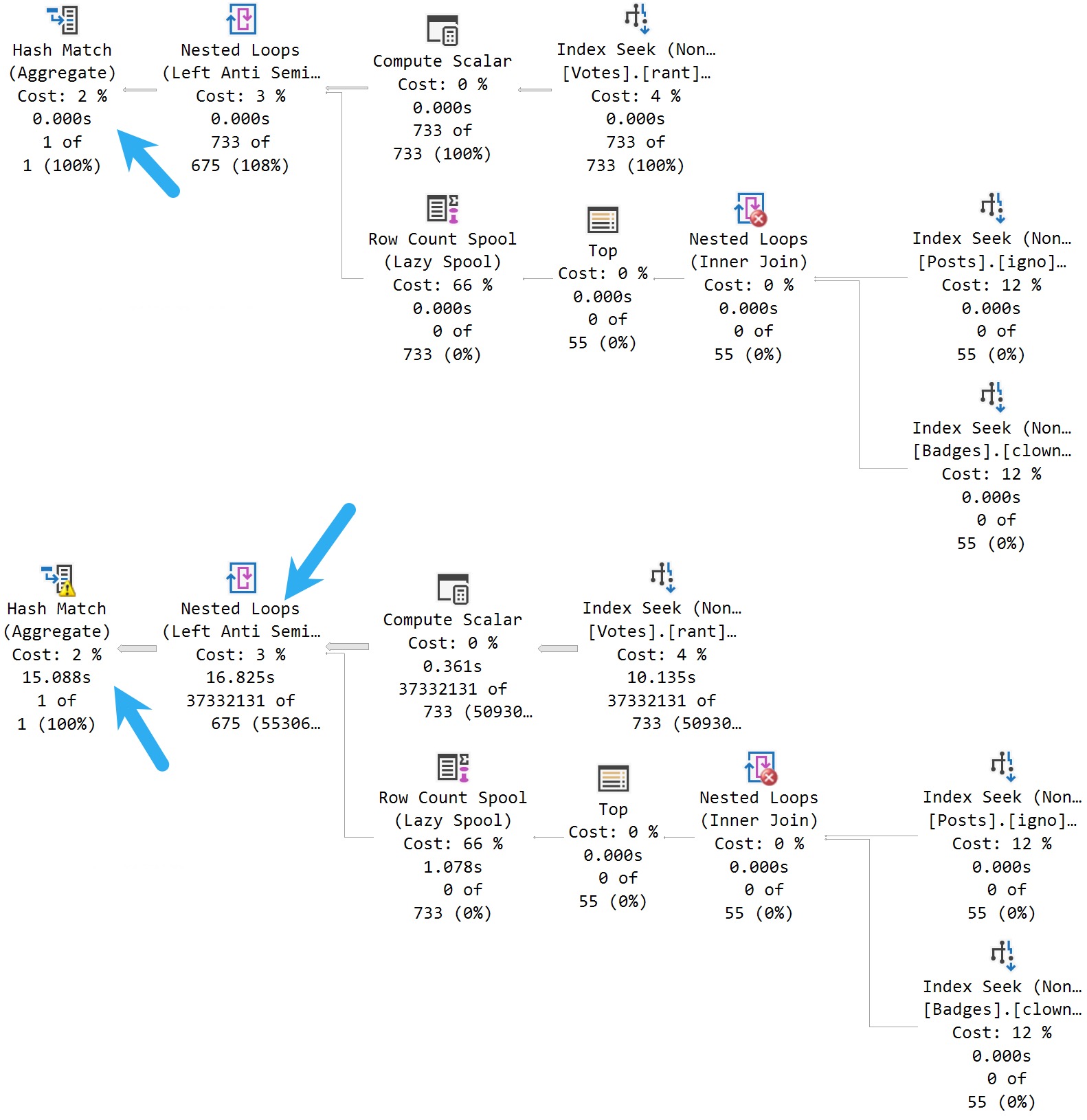
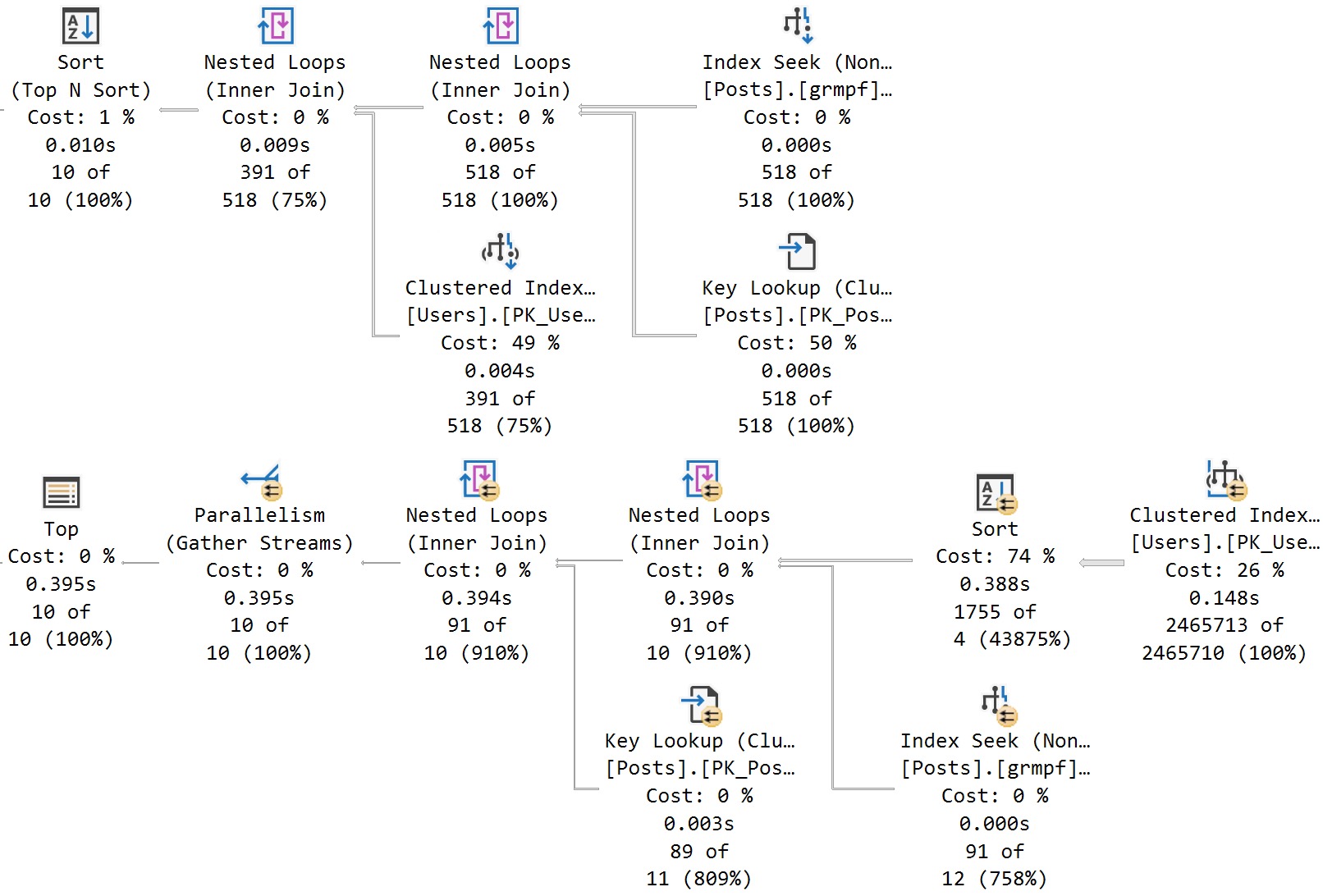
First, with no indexes:

Even though both queries have no choice but to scan the clustered index, we get slightly different plans for vastly different estimates. Sort of (ha ha ha) interestingly, if the Sort hadn’t spilled in the top plan, they would have around the same execution time.
Anyway, I’ve been experimenting with other things, but the results have been surprising. For instance, I thought key column order would push the optimizer towards marking one parameter or the other as sensitive, but that doesn’t happen.
Wild stuff.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.