This post contains all of the possible causes for delta store creation that I’ve found. I cannot say with certainty that it’s a complete list, but some of them may be new or unexpected to the reader.
Why Care about Delta Stores?
Microsoft and many others will be quick to tell you that loading data into CCIs is much faster when you can bypass the delta store. In SQL Server 2016 and beyond, delta stores are uncompressed rowstore mini-tables that serve as a temporary holding data until the data can be compressed into columnar format. They’re good when you have a trickle of data to load into a CCI, but bad in all possible ways for a data warehouse workload.
Reviewing the Documentation
I briefly reviewed the documentation written by Microsoft concerning the appearance of delta stores. Here’s a quote:
Rows go to the deltastore when they are:
Inserted with the INSERT INTO VALUES statement.
At the end of a bulk load and they number less than 102,400.
Updated. Each update is implemented as a delete and an insert.
There are also a few mentions of how partitioning can lead to the creation of multiple delta stores from a single insert. It seems as if the document is incomplete or a little misleading, but I admit that I didn’t exhaustively review everything. After all, Microsoft hides columnstore documentation all over the place.
Test Data
The source data for the CCI inserts is fairly uninteresting. I put four rowgroups worth of rows into a rowstore table with a BIGINT column and a randomly generated VARCHAR(16) value.
DROP TABLE IF EXISTS dbo.STAGING_TABLE; CREATE TABLE dbo.STAGING_TABLE ( ID BIGINT NOT NULL, STR1 VARCHAR(16) NOT NULL, PRIMARY KEY (ID) ); INSERT INTO dbo.STAGING_TABLE WITH (TABLOCK) SELECT TOP (4 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) , LEFT(CAST(NEWID() AS VARCHAR(36)), 16) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1);
The columns for the table definition for the CCI were chosen to cover all of the demos except for the partitioning one. Your fact table definitions probably don’t look like this.
DROP TABLE IF EXISTS dbo.DELTA_STORE_DUMPING_GROUND; CREATE TABLE dbo.DELTA_STORE_DUMPING_GROUND ( ID BIGINT NULL, STR1 VARCHAR(100) NULL, STR2 VARCHAR(100) NULL, STR3 VARCHAR(100) NULL, STR1_MAX VARCHAR(MAX) NULL, INDEX CCI CLUSTERED COLUMNSTORE );
Not Enough Rows For Bulk Load
The first reason for delta creation is well known and understood on SQL Server 2016. If you insert fewer than 102400 rows then SQL Server will not attempt to skip the delta store. This behavior is by design. The following query does not do a bulk load:
INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (102399) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
We can see the delta store that was just created with the following query:
SELECT
row_group_id
, state_desc
, total_rows
--, trim_reason_desc
--, deleted_rows
--, partition_number
FROM sys.dm_db_column_store_row_group_physical_stats rg
INNER JOIN sys.tables t ON rg.OBJECT_ID = t.OBJECT_ID
WHERE t.name = 'DELTA_STORE_DUMPING_GROUND';
The results:
![]()
The other examples in this post use similar queries to get information about the newly added rowgroups to the table. They will be omitted for brevity. Simply inserting one row results in the delta store getting skipped:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (102400) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
Now the rowgroup is compressed:
![]()
The rules change slightly in SQL Server 2017 with support of VARCHAR(MAX) and other LOB columns in columnstore. The delta store can be skipped with an insert of as few as 251 rows. Whether or not you write to the delta store depends on the amount of data being written. Below is one query that still writes to the delta store:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (STR1_MAX) SELECT TOP (251) REPLICATE(STR1, 40) FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
Once again you can see the delta store:
![]()
Things are different if we increase the length of the inserted data. The query below writes to a compressed rowgroup and bypasses the delta store:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (STR1_MAX) SELECT TOP (251) REPLICATE(STR1, 500) FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
The resulting rowgroup is compressed:
![]()
Removing just a single row from the insert brings us back to the delta store.
Inserting to Multiple Partitions
If a MAXDOP 1 INSERT query writes to multiple partitions then it could possibly write to multiple delta stores. The number of rows written to each partition is important as opposed to the total number of rows written to the table. Below I define a simple table with 2 partitions:
CREATE PARTITION FUNCTION CLUNKY_SYNTAX_1 (BIGINT) AS RANGE LEFT FOR VALUES ( 0 , 2000000 ); CREATE PARTITION SCHEME CLUNKY_SYNTAX_2 AS PARTITION CLUNKY_SYNTAX_1 ALL TO ( [PRIMARY] ); DROP TABLE IF EXISTS dbo.PARTITIONED_DELTA_STORE; CREATE TABLE dbo.PARTITIONED_DELTA_STORE ( ID BIGINT NULL, INDEX CCI CLUSTERED COLUMNSTORE ) ON CLUNKY_SYNTAX_2 (ID);
The insert writes 200k rows to the CCI which you might expect to bypass the delta store, but since the rows are evenly spread over two partitions we end up with two delta stores:
INSERT INTO dbo.PARTITIONED_DELTA_STORE (ID) SELECT ID FROM dbo.STAGING_TABLE WHERE ID BETWEEN 1900001 AND 2100000 OPTION (MAXDOP 1);

With MAXDOP 8 INSERT queries and the maximum number of partitions defined on a table, it is possible to get 120000 delta stores. I don’t recommend doing this.
Bulk Insert Leftovers
Often applications will not insert an exact multiple of 1048576 rows. That means that rows can be left over after a few rowgroups worth of inserted rows are compressed. Those leftover rows can go into a delta store. Consider the following insert query that inserts 100000 rows more than 1048576:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (1048576 + 100000) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
As expected, the final result is one compressed rowgroup of 1048576 rows and one delta store of 100k rows.
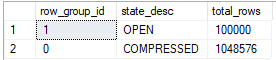
If we inserted just a few thousand more rows than we’d end up with two compressed rowgroups.
Updates
UPDATE queries always write to the delta store. There are many other reasons to avoid UPDATES to CCIs if the application makes it possible to do so.
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (1048576) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
At first there’s just a single compressed rowgroup:
![]()
Now run the UPDATE query and go make coffee:
UPDATE DELTA_STORE_DUMPING_GROUND SET ID = ID;
Our table doesn’t look so hot:

In SQL Server 2016 the Tuple Mover will not clean up this table. Another row needs to be inserted into the table before the rowgroup is marked as CLOSED.
Parallel Insert
Many parallel queries have an element of randomess around how rows are distributed to parallel threads. Rows are not moved between threads after they flow to the part of the plan that performs the insert into the CCI. It’s possible to end up with a number of new delta stores equal to the number of parallel threads for the query. Let’s start with a parallel insert that moves 4 * 1048576 rows into the CCI:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND WITH (TABLOCK) (ID) SELECT ID FROM dbo.STAGING_TABLE OPTION (MAXDOP 4);
It’s possible to end up without any delta stores and the results of the query against sys.dm_db_column_store_row_group_physical_stats will vary, but generally you’ll get at least one:
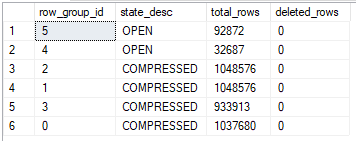
If we have unnaturally high beauty standards for our rowgroups we can rewrite the query to effectively force rows to be evenly distributed on all threads. The query below does this with a join to a derived table:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND WITH (TABLOCK) (ID) SELECT stg.ID FROM ( VALUES (0 * 1048576 + 1, 1 * 1048576), (1 * 1048576 + 1, 2 * 1048576), (2 * 1048576 + 1, 3 * 1048576), (3 * 1048576 + 1, 4 * 1048576) ) v (start_id, end_id) INNER JOIN dbo.STAGING_TABLE stg ON stg.ID BETWEEN v.start_id and v.end_id OPTION (MAXDOP 4);
Perfection:
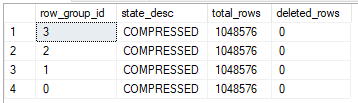
I know that you were looking forward to another image of a tiny table, but here’s the important part of the query plan for those who like that sort of thing:
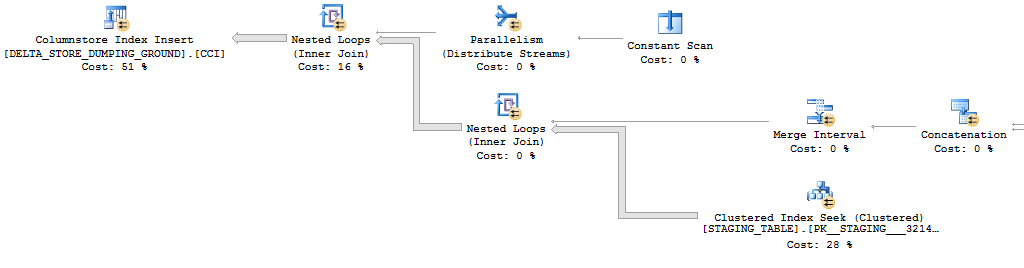
Getting perfect rowgroups can also be accomplished by adding the TOP operator to the original query, but that adds a serial zone to the plan:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND WITH (TABLOCK) (ID) SELECT TOP (9999999999999999) stg.ID FROM dbo.STAGING_TABLE stg OPTION (MAXDOP 4);
The key here is the parallelism operator in the plan uses a round robin method for distributing rows:

Dictionary Pressure
In SQL Server 2016 the maximum size for a column dictionary is 16 MB. This limit is raised in SQL Server 2017 for VARCHAR(MAX) and similar columns. I’m not going to get into the details of dictionaries here but it suffices to say that columns with too many unique string columns can experience dictionary pressure. Dictionary pressure leads to compressed rows that are less than the perfect size of 1048576 rows. Let’s insert the STR1 column into the CCI this time:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (STR1) SELECT TOP (1048576) stg.STR1 FROM dbo.STAGING_TABLE stg ORDER BY ID OPTION (MAXDOP 1);
Due to dictionary pressure there’s now a delta store with about 73000 rows:

We can see that the dictionary size for the column is close to the limit with the query below:
SELECT csd.entry_count, csd.on_disk_size
FROM sys.column_store_dictionaries csd
INNER JOIN sys.partitions p
ON csd.partition_id = p.partition_id
INNER JOIN sys.tables t
ON p.OBJECT_ID = t.OBJECT_ID
WHERE t.name = 'DELTA_STORE_DUMPING_GROUND'
AND csd.column_id = 2;
Here are the results:
![]()
Rowgroup Memory Pressure
The memory grant for CCI compression for an INSERT is calculated based on DOP and column definitions of target columns in the target table. The memory grant can be insufficient to get a full 1048576 rows into a compressed rowgroup depending on the table definition and the characteristics of the data getting loaded into the table. Consider an example in which data is loaded into three columns of the CCI:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (STR1, STR2, STR3) SELECT TOP (1048576) LEFT(STR1, 10) , LEFT(STR1, 5) , LEFT(STR1, 6) FROM dbo.STAGING_TABLE stg ORDER BY ID OPTION (MAXDOP 1);
With the above syntax the memory grant is calculated from just the STR1, STR2, and STR3 columns. The memory grant of 171152 KB isn’t enough to avoid a delta store:

Note that you may not see the same results on your machine due to the randomness of the source data. For my table and source data set, adding a single column and inserting NULL into it bumps the memory grant up enough to avoid memory pressure:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; ALTER TABLE dbo.DELTA_STORE_DUMPING_GROUND ADD MORE_MEMORY_PLZ VARCHAR(1) NULL; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (STR1, STR2, STR3, MORE_MEMORY_PLZ) SELECT TOP (1048576) LEFT(STR1, 10) , LEFT(STR1, 5) , LEFT(STR1, 6) , NULL FROM dbo.STAGING_TABLE stg ORDER BY ID OPTION (MAXDOP 1);
The compressed rowgroup contains 1048576 rows now that memory pressure has been addressed.
![]()
Cardinality Estimate Less Than 251 Rows
SQL Server won’t even ask for a memory grant if the cardinality estimate is less than 251 rows. Perhaps this is because the memory grant would be wasted unless at least 102400 rows were inserted into the table. There’s no second chance at a memory grant here, so it’s possible to insert millions of rows to delta stores. A TOP expression with a variable will default to a cardinality estimate of 100 rows, so this works nicely to show the behavior:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; DECLARE @top_rows BIGINT = 1048576; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (@top_rows) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1);
Despite inserting 1048576 rows we aren’t able to bypass the delta store:
![]()
The same behavior can be observed with a cardinality estimate of 250 rows. The OPTIMIZE FOR query hint is used to control the estimate.
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; DECLARE @top_rows BIGINT = 1048576; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (@top_rows) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1, OPTIMIZE FOR (@top_rows = 250));
However, if I bump up the estimate by one more row a memory grant is given to the query and the delta store is bypassed:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; DECLARE @top_rows BIGINT = 1048576; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (@top_rows) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1, OPTIMIZE FOR (@top_rows = 251));
![]()
Under this scenario we’ve observed deadlocks when multiple sessions insert into delta stores from the same target table.
Extreme Server Memory Pressure
Memory grants for queries that insert into CCIs have a hardcoded timeout of 25 seconds. After 25 seconds they execute with required serial memory and always write to the delta store. In the query below I simulate memory pressure with a MAX_GRANT_PERCENT hint of 0:
TRUNCATE TABLE dbo.DELTA_STORE_DUMPING_GROUND; INSERT INTO dbo.DELTA_STORE_DUMPING_GROUND (ID) SELECT TOP (1048576) ID FROM dbo.STAGING_TABLE ORDER BY ID OPTION (MAXDOP 1, MAX_GRANT_PERCENT = 0);
The query always writes to the delta store. It cannot compress data without a memory grant.
![]()
Under this scenario we’ve observed deadlocks when multiple sessions insert into delta stores from the same target table.
Final Thoughts
It took forever to do the formatting for this one, so I hope that someone finds it useful.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.