But What Happens When…
People may tell you to always put the most selective column first in a query, but selectivity depends on more than just what values are in a column.
It also depends on how columns are searched, doesn’t it? If people are using inequalities, like >, >=, < , <= then having a totally unique value on every row becomes a bit less helpful.
Likewise, if people can search IN() or NOT IN, NULL or NOT NULL, or even if perhaps the data in a column is only selective for some values, then selectivity can be a whole lot less selective.
Beyond that, it ignores a whole world of considerations around how you’re grouping or ordering data, if your query is a top (n) with an order by, and more.
Before we go jumping off on such wild adventures, let’s talk a little bit about multi-key indexes. It’s easy enough to visualize a single column index putting data in order, but multi-key indexes present a slightly different picture.
Janitorial
Single-column clustered indexes make a lot of sense. Single column nonclustered indexes often make less sense.
It’s sort of like the difference between a chef knife and a Swiss Army knife. You want one to be really good at one specific task, and another to be pretty useful to a bunch of tasks.
Will a Swiss Army knife be the best wine opener you’ve ever owned? No, but it’s a whole lot easier than trying to get a cork out with a cleaver, and it can also be a screwdriver, a pair of scissors, and open a beer bottle for your less industrious friends who can’t quite muster the strength to cope with a twist-off cap.
That multi-tool ability comes at a bit of a cost, too. There’s no such thing as a free index column (unless the table is read only).

All those columns have to be maintained when you modify table data, of course.
And there’s another thing: every key column in the index is dependent on the column that comes before it. Rather than try to word-problem this for you, let’s just look at some demos.
Withdrawals
Let’s say we’ve got this index which, albeit simple, is at least more than a single column. Congratulations, you’ve graduated.
CREATE INDEX joan_jett
ON dbo.Posts
(
PostTypeId, Score
);
If we write queries like this, we’ll be able to use it pretty efficiently.
SELECT p.Id, p.PostTypeId, p.Score FROM dbo.Posts AS p WHERE p.PostTypeId = 7 AND p.Score = 1;
I’m skipping over a little bit now, because data is mightily skewed in the PostTypeId column towards a couple of quite-common values. I’ll get to it, though.
For now, marvel at the simplicity and Seekiness of this plan.

Now let’s try to find data in the Score column without also searching on the PostTypeId column.
SELECT p.Id, p.PostTypeId, p.Score FROM dbo.Posts AS p WHERE p.Score = 999;
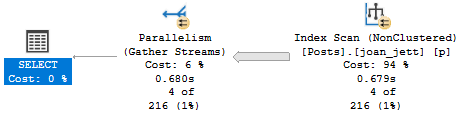
A couple things changed, here. We had to scan through the index to find Scores we’re interested in, and the optimizer thought that this would be a process-intensive enough task to use multiple CPU cores to do it.
Okay then.
Age Of Reason
If you’ve been kicking around databases for a little bit, you may have read about this before, or even seen it in action when writing queries and creating indexes.
What I’d like to do is try to offer an explanation of why that happens the way it does: Columns within an index are not ordered independently.
In other words, you don’t have all of the PostTypeIds in ascending order, and then all of the Scores in ascending order. You do have all the PostTypeIds in ascending order, because it’s the leading column, but Scores are only in ascending order after PostTypeId.
A simple query gets illustrative enough results.
SELECT p.PostTypeId, p.Score FROM dbo.Posts AS p WHERE p.PostTypeId IN (1, 2) AND p.Score BETWEEN 1950 AND 2000 ORDER BY p.PostTypeId, p.Score;
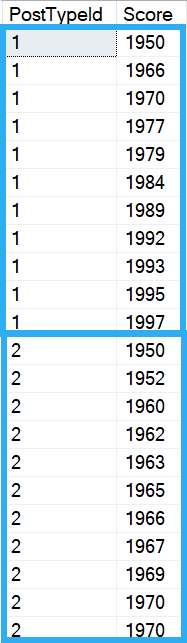
Note how the ordering of Score resets when you cross a value boundary in PostTypeId?
We can see that in action with other queries, too.
Then People Stare
Here are three queries, and three plans.
SELECT TOP (1000) p.Id, p.PostTypeId, p.Score
FROM dbo.Posts AS p
ORDER BY p.Score; --Score isn't stored in order independently
SELECT TOP (1000) p.Id, p.PostTypeId, p.Score
FROM dbo.Posts AS p
ORDER BY p.PostTypeId; --PostTypeId is the leading column, though
SELECT TOP (1000) p.Id, p.PostTypeId, p.Score
FROM dbo.Posts AS p
ORDER BY p.PostTypeId,
p.Score; --Score is in order within repeated PostTypeId values
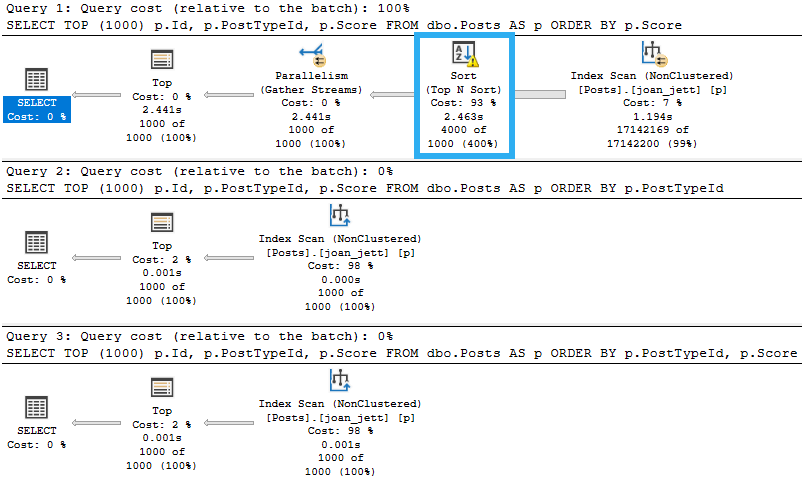
Only that first query, where we try to order by Score independently needs to physically sort data. They all use the same index, but that index doesn’t store Score in perfect ascending order, unless we first order by PostType Id.
In tomorrow’s post, we’ll mix things up a little bit and design an index for a tricky query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Starting SQL: SARGability, Or Why Some SQL Server Queries Will Never Seek
- Starting SQL: Fixing Parameter Sensitivity Problems With SQL Server Queries
- Starting SQL: How Parameters Can Change Which Indexes SQL Server Chooses
- Starting SQL: Why Is My SQL Server Query Suddenly Slower Than It Was Yesterday?
Awesome!