PAUL WHITE IS WRONG
Ha ha. Just kidding. He’s never wrong about anything.
But he did write about Eager Index Spools recently, and the post ended with the following statement:
Eager index spools are often a sign that a useful permanent index is missing from the database schema.
I’d like to show you a case where you may see an Eager Index Spool even when you have the index being spooled.
Funboy & Funboy & Funboy
Let’s say we’ve got a query that, for better or worse, was written like so:
SELECT SUM(records)
FROM dbo.Posts AS p
CROSS APPLY
(
SELECT COUNT(p2.Id)
FROM dbo.Posts AS p2
WHERE p2.LastEditDate >= '20121231'
AND p.Id = p2.Id
UNION ALL
SELECT COUNT(p2.Id)
FROM dbo.Posts AS p2
WHERE p2.LastEditDate IS NULL
AND p.Id = p2.Id
) x (records);
Right now, we’ve got this index:
CREATE INDEX to_null_or_not_to_null ON dbo.Posts(LastEditDate);
Which means we’ve effectively got an index on (LastEditDate, Id), because of how clustered index key columns are inherited by nonclustered indexes.
The APPLY section of the query plan looks like so:
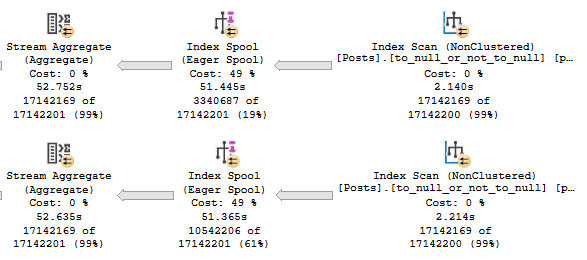
Each spool runs for nearly 53 seconds. The entire plan runs for 1:52.
There have been times when I’ve seen index spools created to effectively re-order existing indexes.
Perhaps that’s the case here? Let’s add this index.
CREATE /*UNIQUE*/ INDEX that_is_a_question ON dbo.Posts(Id, LastEditDate);
I’ve got UNIQUE in there in case you’re playing along at home. It makes no difference to the outcome.
I’d expect you to ask about that. I have high expectations of you, dear reader. I love you.
PLEASE DON’T LEAVE ME.
Get Out
The new execution plan looks uh.
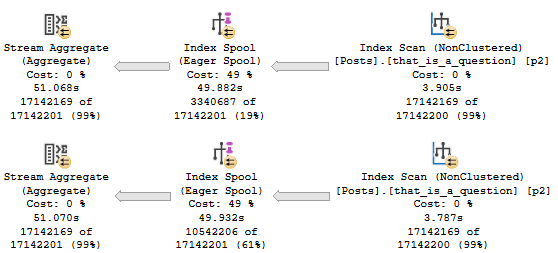
That’s frustrating, isn’t it? Why would you do that?
When I asked Paul why the optimizer was wrong (I understand that many of you confuse Paul with the optimizer. To wit, they’ve never been seen together.), he said something along the lines of:
The issue is that you have a unique clustered index that prevents the index matching logic from finding the better nonclustered index.
Well okay yeah lemme just go drop that clustered index or something.
Workarounds
There are several workarounds, like using FORCESEEK inside the APPLY logic.
Of course, the better method is just to write the query so there’s no need for the optimizer to join a table to itself a couple times.
SELECT SUM(x.records)
FROM (
SELECT COUNT(p.records)
FROM
(
SELECT 1 AS records
FROM dbo.Posts AS p2
WHERE p2.LastEditDate >= '20121231'
) AS p
UNION ALL
SELECT COUNT(p.records)
FROM
(
SELECT 1 AS records
FROM dbo.Posts AS p2
WHERE p2.LastEditDate IS NULL
) AS p
) AS x (records);
Which’ll finish in about 1.5 seconds.
But hey, nifty demo.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- How Select List Column Sizes Change How Big Spool Operators Are In SQL Server Query Plans
- Why You’re Testing SQL Server Code For Performance The Wrong Way
- SQL Server 2022 CTP 2.1 Improvements To Parameter Sensitive Plan Optimization
- SQL Server 2022: Introduces the DATETRUNC Function, So You Can Truncate Your Dates And Stuff
One thought on “SQL Server Index Spools When You Have An Index”
Comments are closed.