Put Out
I see people using OUTPUT to audit modifications from time to time, often because “triggers are bad” or “triggers are slow”.
Well, sometimes, sure. But using OUTPUT can be a downer, too.
Let’s look at how.
A Process Emerges
Say we’ve got a table that we’re using to track user high scores for their questions.
CREATE TABLE dbo.HighQuestionScores
(
Id INT PRIMARY KEY CLUSTERED,
DisplayName NVARCHAR(40) NOT NULL,
Score BIGINT NOT NULL
);
To test the process, let’s put a single user in the table:
INSERT dbo.HighQuestionScores WITH (TABLOCK)
(Id, DisplayName, Score)
SELECT u.Id, u.DisplayName, p.Score
FROM dbo.Users AS u
JOIN
(
SELECT p.OwnerUserId,
MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
GROUP BY p.OwnerUserId
) AS p ON p.OwnerUserId = u.Id
WHERE u.Id = 22656;
To exacerbate the problem, I’m not going to create any helpful indexes here. This is a good virtual reality simulator, because I’ve seen your indexes.
Yes you. Down in front.
The relevant part of the query plan is the scan of the Posts table:

It’s parallel, and takes 1.8 seconds.
Aw, dit
Now let’s add in an OUTPUT clause.
I’m going to skip over inserting the output into any structure, because I want you to understand that the target doesn’t matter.
INSERT dbo.HighQuestionScores WITH (TABLOCK)
(Id, DisplayName, Score)
OUTPUT Inserted.Id,
Inserted.DisplayName,
Inserted.Score
SELECT u.Id, u.DisplayName, p.Score
FROM dbo.Users AS u
JOIN
(
SELECT p.OwnerUserId, MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
GROUP BY p.OwnerUserId
) AS p ON p.OwnerUserId = u.Id
WHERE u.Id = 22656;
The relevant part of the plan now looks like this:
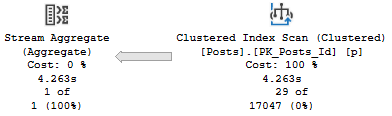
We’ve lost parallelism, and inspecting the properties of the Insert operator tells us why:
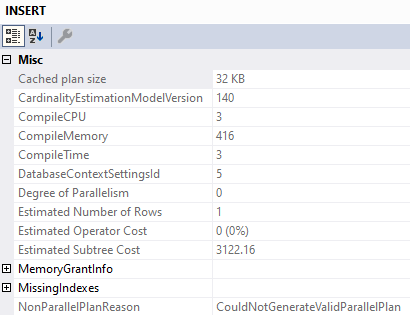
We’ve got a Non Parallel Plan Reason. Why aren’t there any spaces? I don’t know.
Why can’t that go parallel? I also don’t know.
What About Triggers?
If we create a minimal trigger on the table, we can see if it has the same overhead.
CREATE OR ALTER TRIGGER dbo.hqs_insert ON dbo.HighQuestionScores
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
SELECT Inserted.Id,
Inserted.DisplayName,
Inserted.Score
FROM Inserted;
END
Let’s go back to the original insert, without the output! We care about two things:
- Is the parallel portion of the insert plan still there?
- Is there any limitation on parallelism with the Inserted (and by extension, Deleted) virtual tables?
The answers are mostly positive, too. The insert plan can still use parallelism.
I’m not gonna post the same picture here, you can scroll back fondly.
Though the select from the Inserted table within the trigger doesn’t go parallel, it doesn’t appear to limit parallelism for the entire plan. It does appear that reads from the Inserted table can’t use parallelism (sort of like the table variable in a MSTVF).
Let’s modify the trigger slightly:
CREATE OR ALTER TRIGGER dbo.hqs_insert ON dbo.HighQuestionScores
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Id INT
DECLARE @DisplayName NVARCHAR(40)
DECLARE @Score BIGINT
SELECT @Id = Inserted.Id,
@DisplayName = Inserted.DisplayName,
@Score = Inserted.Score
FROM Inserted
JOIN dbo.Comments AS c
ON c.UserId = Inserted.Id;
END
And for variety, let’s insert a lot more data into our table:
TRUNCATE TABLE dbo.HighQuestionScores;
INSERT dbo.HighQuestionScores WITH (TABLOCK)
(Id, DisplayName, Score)
SELECT u.Id, u.DisplayName, p.Score
FROM dbo.Users AS u
JOIN
(
SELECT p.OwnerUserId, MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
GROUP BY p.OwnerUserId
) AS p ON p.OwnerUserId = u.Id
WHERE u.Id < 500000;
Here’s the query plan:
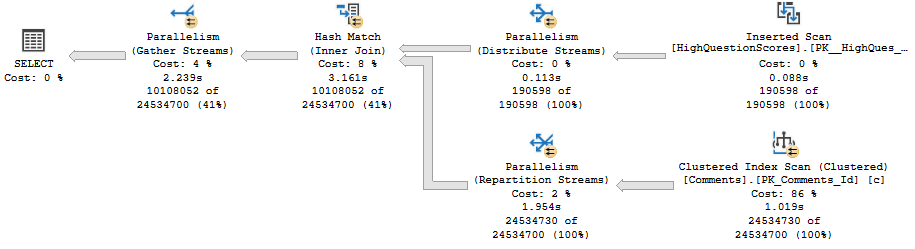
The read from Inserted is serial, but the remainder of the plan fully embraces parallelism like a long lost donut.
Togetherness
Given a well-tuned workload, you may not notice any particular overhead from using OUTPUT to audit certain actions.
Of course, if you’re using them alongside large inserts, and those large inserts happen to run for longer than you’d like, it might be time to see how long they take sans the OUTPUT clause. It’s entirely possible that using a trigger instead would cause fewer performance issues.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Common Table Expressions Are Useful For Rewriting Scalar Functions In SQL Server
- Multiple Distinct Aggregates: Still Harm Performance Without Batch Mode In SQL Server
- What’s Really Different About In-Memory Table Variables In SQL Server?
- When Index Sort Direction Matters For Query Performance In SQL Server