It’s My Blog And I’ll Blog What I Want to
When I sit down to write any blog post as a series, I do these things first:
- List out topics – it’s cool if it’s stuff I’ve covered before, but I want to do it differently
- Look at old posts – I don’t want to fully repeat myself, but I write these things down so I don’t forget them
- Write demos – some are easier than others, so I’ll jump around the list a little bit
Having said all that, I also give myself some grace in the matter. Sometimes I’ll want to talk about something else that breaks up the flow of the series. Sometimes I’ll want to record a video to keep the editors at Beergut Magazine happy.
And then, like with this post, I change my mind about the original topic. This one was going to be “Fixing Predicate Selectivity”, but the more I looked at it, the more the demo was going to look like the one in my post in this series about SARGability.
That felt kind of lame, like a copout. And while there are plenty of good reasons for copouts when you’re writing stuff for free, even I felt bad about that one. I almost ended the series early, but a lot of the work I’ve been doing has been on particularly complicated messes.
So now we’re going to talk about one of my favorite things I help clients with: big, unpredictable search queries.
First, What You’re (Probably) Not Going To Do
There’s one thing that you should absolutely not do, and one thing that I’ll sometimes be okay with for these kinds of queries.
First, what you should not do: A universal search string:
WHERE (p.OwnerUserId LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL) OR (p.Title LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL) OR (p.CreationDate LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL) OR (p.LastActivityDate LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL) OR (p.Body LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL);
The problem here is somewhat obvious if you’ve been hanging around SQL Server long enough. Double wildcard searches, searching with a string type against numbers and dates, strung-together OR predicates that the optimizer will hate you for.
These aren’t problems that other things will solve either. For example, using CHARINDEX or PATINDEX isn’t a better pattern for double wildcard LIKE searching, and different takes on how you handle parameters being NULL don’t buy you much.
So like, ISNULL(@Parameter, Column) will still suck in most cases.
Your other option is something like this, which is only not-sucky with a statement-level OPTION(RECOMPILE) hint at the end of your query.
WHERE (p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL) AND (p.CreationDate >= @CreationDate OR @CreationDate IS NULL) AND (p.LastActivityDate < @LastActivityDate OR @LastActivityDate IS NULL) AND (p.Score >= @Score OR @Score IS NULL) AND (p.Body LIKE N'%' + @Body + N'%' OR @Body IS NULL)
This departs from the universal search string method, and replaces the one string-typed parameter with parameters specific to each column’s data type.
Sure, it doesn’t allow developers to be lazy sons of so-and-so’s in the front end, but you don’t pay $7000 per core for them, and you won’t need to keep adding expensive cores if they spend a couple hours doing things in a manner that resembles a sane protocol.
The recompile advice is good enough, but when you use it, you really need to pay attention to compile times for your queries. It may not be a good idea past a certain threshold of complexity to come up with a “new” execution plan every single time, minding that that “new” plan might be the same plan over and over again.
Second, What You’re Eventually Going To End Up With
SQL Server doesn’t offer any great programmability or optimizer support for the types of queries we’re talking about. It’s easy to fall into the convenience-hole of one of the above methods.
Writing good queries means extra typing and thinking, and who has time for all that? Not you. You’re busy thinking you need to use some in-memory partitioning, or build your own ORM from scratch, no, migrate to a different relational database, that will surely solve all your problems, no, better, migrate to a NoSQL solution, that’ll do it, just give you 18-24 months to build a working proof of concept, learn seven new systems, and hire some consultants to help you with the migration, yeah, that’s the ticket.
You can’t just spend an hour typing a little extra. Someone on HackerNews says developers who type are the most likely to be replaced by AI.
Might as well buy a pick and a stick to DIY a grave for your career. It’ll be the last useful thing you do.
Rather than put 300 lines of code and comments in a blog post, I’m storing it in a GitHub gist here.
What I am going to post in here is the current list of variables, and what each does:
- @Top: How many rows you want to see (optional, but has a default value)
- @DisplayName: Search for a user’s display name (optional, can be equality or wildcard)
- @Reputation: Search for users over a specific reputation (optional, greater than or equal to)
- @OwnerUserId: Search for a specific user id (optional, equality)
- @CreationDate: Search for posts created on or after a date (optional, greater than or equal to)
- @LastActivityDate: Search for posts created before a date (optional, less than)
- @PostTypeId: Search for posts by question, answer, etc. (optional, equality)
- @Score: Search for posts over a particular score (optional, greater than or equal to)
- @Title: Search for posts with key words in the title (optional, can be equality or wildcard)
- @Body: Search for posts with key words in the body (optional, can be equality or wildcard)
- @HasBadges: If set to true, get a count of badges for any users returned in the results (optional, true/false)
- @HasComments: If set to true, get a count of comments for any users returned in the results (optional, true/false)
- @HasVotes: If set to true, get a count of votes for any posts returned in the results (optional, true/false)
- @OrderBy: Which column you want the results ordered by (optional, but has a default value)
- @OrderDir: Which direction you want the results sorted in, ascending or descending (optional, but has a default value)
To round things up:
- There are 9 parameters in there which will drive optional searches
- Seven of the nine optional searches are on the Posts table, two are on the Users table
- There are 3 parameters that drive how many rows we want, and how we want them sorted
- There are 3 parameters that optionally hit other tables for additional information
Indexing for the Users side of this is relatively easy, as it’s only two columns. Likewise, indexing for the “Has” parameters is easy, since we just need to correlate to one additional column in Badges, Comments, or Votes.
But that Posts table.
That Posts table.
Index Keys Open Doors
The struggle you’ll often run into with these kinds of queries is that there’s a “typically expected” thing someone will always search for.
In your case, it may be a customer id, or an order id, or a company id… You get the point. Someone will nearly always need some piece of information for normal search operations.
Where things go off the rails is when someone doesn’t do that. For the stored procedure linked above, the role of the “typically expected” parameter will be OwnerUserId.
The data in that column doesn’t have a very spiky distribution. At the high end, you have about 28k rows, and at the low end, well, 1 row. As long as you can seek in that column, evaluating additional predicates isn’t so tough.
In that case, an index like this would get you going a long way:
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, Score DESC, CreationDate, LastActivityDate)
INCLUDE
(PostTypeId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
Since our stored procedure “typically expects” users to supply OwnerUserId, has a default sorting of Score, optional Creation and LastActivity Dates can act as residual predicates without a performance tantrum being thrown.
And since PostTypeId is one of the least selective columns in the whole database, it can go live in the basement as an included column.
Using dynamic SQL, we don’t have to worry about SQL Server trying to re-use a query execution plan for when OwnerUserId is passed in. We would have to worry about that using some other implementations.
Here, the problem is that some searches will be slow without supporting indexes, and not every slow query generates a missing index request.
/*NOPE THIS IS FINE NO INDEX COULD HELP*/
EXEC dbo.ReasonableRates
@CreationDate = '20130101',
@LastActivityDate = '20140101',
@HasBadges = 1,
@HasComments = 1,
@HasVotes = 1,
@Debug = 1;
GO
As an example, this takes ~10 seconds, results in a perfectly acceptable where clause for an index to help with, but no direct request is made for an index.
Of course, there’s an indirect request in the form of a scan of the Posts table.
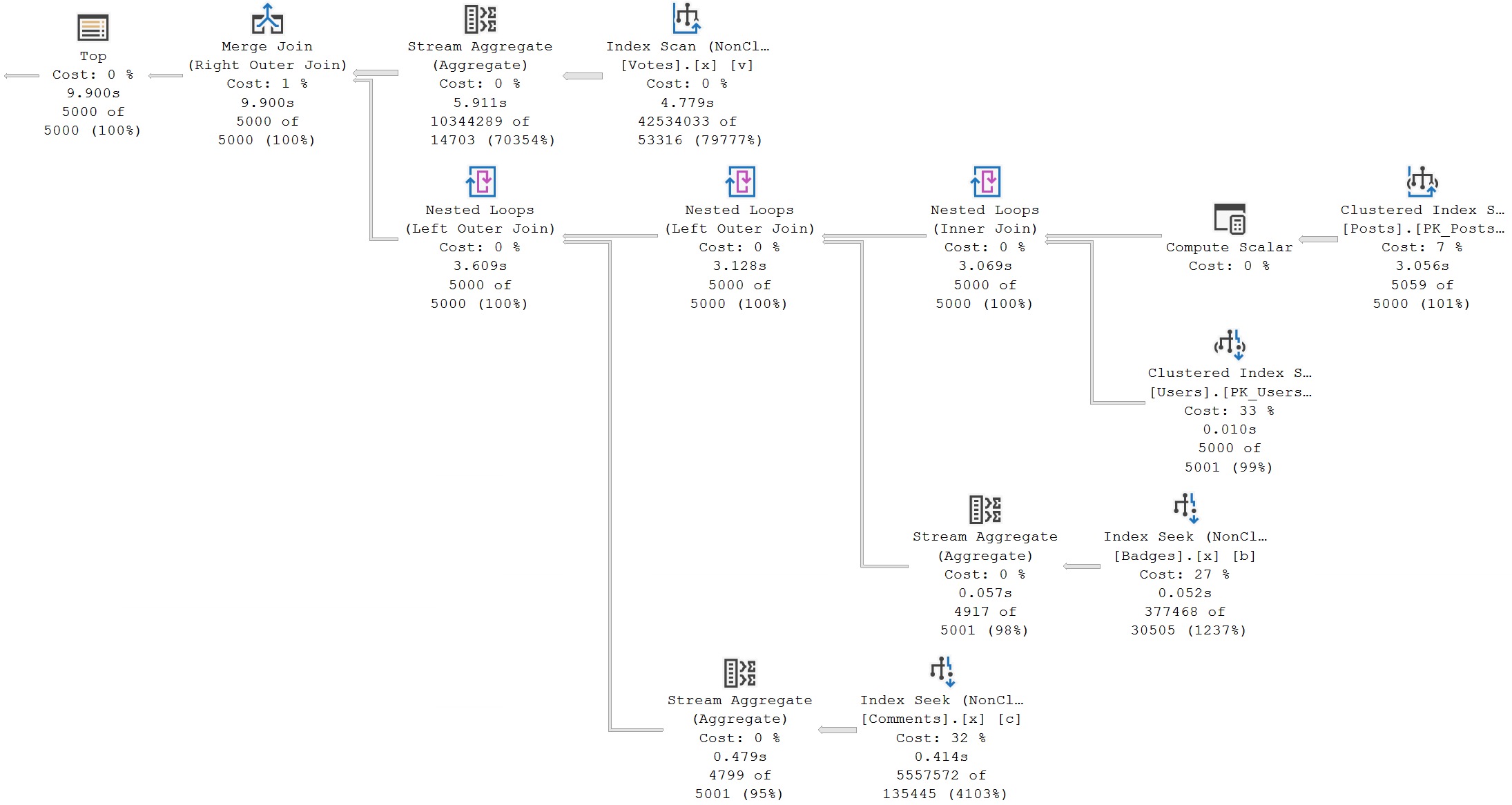
So, back to the struggle, here:
- How do you know how often this iteration of the dynamic SQL runs?
- Is it important? Did someone important run it?
- Is it important enough to add an index to help?
And then… how many other iterations of the dynamic SQL need indexes to help them, along with all the other questions above.
You may quickly find yourself thinking you need to add dozens of indexes to support various search and order schemes.
Data Access Patterns
This is the big failing of Row Store indexes for handling these types of queries.
CREATE INDEX
codependent
ON dbo.Posts
(
OwnerUserId,
/*^Depends On^*/
Score,
/*^Depends On^*/
CreationDate,
/*^Depends On^*/
LastActivityDate,
/*^Depends On^*/
PostTypeId,
/*^Depends On^*/
Id
)
INCLUDE
(Title)
/*^Doesn't depend on anything. It's an Include.^*/
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
In general, if you’re not accessing index key columns starting with the leading-most key column, your queries won’t be as fast (or may not choose to use your index, like in the plan up there), because they’d have to scan the whole thing.
For queries like this, nonclustered column store indexes are a way hotter ticket. Columns can be accessed independently. They may get abused by modification queries, and they may actually need maintenance to keep them compressed and tombstone-free, but quite often these tradeoffs are worth it for improving search queries across the board. Even for Standard Edition users, whom Microsoft goes out of their way to show great disdain for, it can be a better strategy.
Here’s an example:
CREATE NONCLUSTERED COLUMNSTORE INDEX
nodependent
ON dbo.Posts
(OwnerUserId, Score, CreationDate, LastActivityDate, PostTypeId, Id, Title)
WITH(MAXDOP = 1);
With this index in place, we can help lots of search queries all in one shot, rather than having to create a swath of sometimes-helpful, sometimes-not indexes.
Even better, we get a less wooly guarantee that the optimizer will heuristically choose Batch Mode.
Two Things
I hope you take two things away from this post:
- How to write robust, readable, repeatable search queries
- Nonclustered columnstore indexes can go a lot further for performance with unpredictable predicates
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If you have a denormalized table and need to do distinct across columns the columnstore index you described is also very fast.
At a previous job we used another approach
All SQL statements used by this app were stored in a file (fits better for source control than a SQL table) and had a human readable name.
Each statement had all possible filters in the where condition, so when we liked to select the user table and had on the GUI filters for e.g. user_number, last_name and first_name the WHERE would look like:
WHERE 1=1
AND u.user_number = @user_number
AND u.last_name = @last_name
AND u.first_name = @first_name
The application would then check the filters that the user really set on ther form and simply comment out the lines with an unused filter before sending the statement to the SQL server. So when the user just searched for last_name the app would have changed the WHERE to
WHERE 1=1
–AND u.user_number = @user_number
AND u.last_name = @last_name
–AND u.first_name = @first_name
This way the SQL server could build and save the “perfect” plan for every possible combination of used filters (yes, I know, parameter sniffing…) without recompiling it thousands of time (with many active users). And to be honest: 98% of all queries are using maybe three or four common filter attributes and all the others (as last_logon_time or last_order_date or crated_at) are just used for some very special cases every few days or even weeks.
Of course this is some sort of dynamic SQL, but I don’t use the app to manually try to combine the WHERE condition but could let the DB guys fine tune the query and still have full flexibility for filtering.
Well, yeah, that’s dynamic SQL, but the problem is still with indexing for all the variations.