Orderly
Ordered data is good for all sorts kinds of things in databases. The first thing that may come to mind is searching for data, because it’s a whole lot easier to get what you need when you know where it is.
Think of a playlist. Sometimes you want to find a song or artist by name, and that’s the easiest way to find what you want.
Without things sorted the way you’re looking for them, it’s a lot like hitting shuffle until you get to the song you want. Who knows when you’ll find it, or how many clicks it will take to get there.
The longer your playlist is, well, you get the idea. And people get all excited about Skip Scans. Sheesh.
Anyway, let’s look at poor optimizer choices, and save the poor playlist choices for another day.
A Normal Query
This is a query that I know and love.
SELECT
p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
AND v.VoteTypeId = 2
ORDER BY
p.Id;
I love it because it gets a terribly offensive query plan.
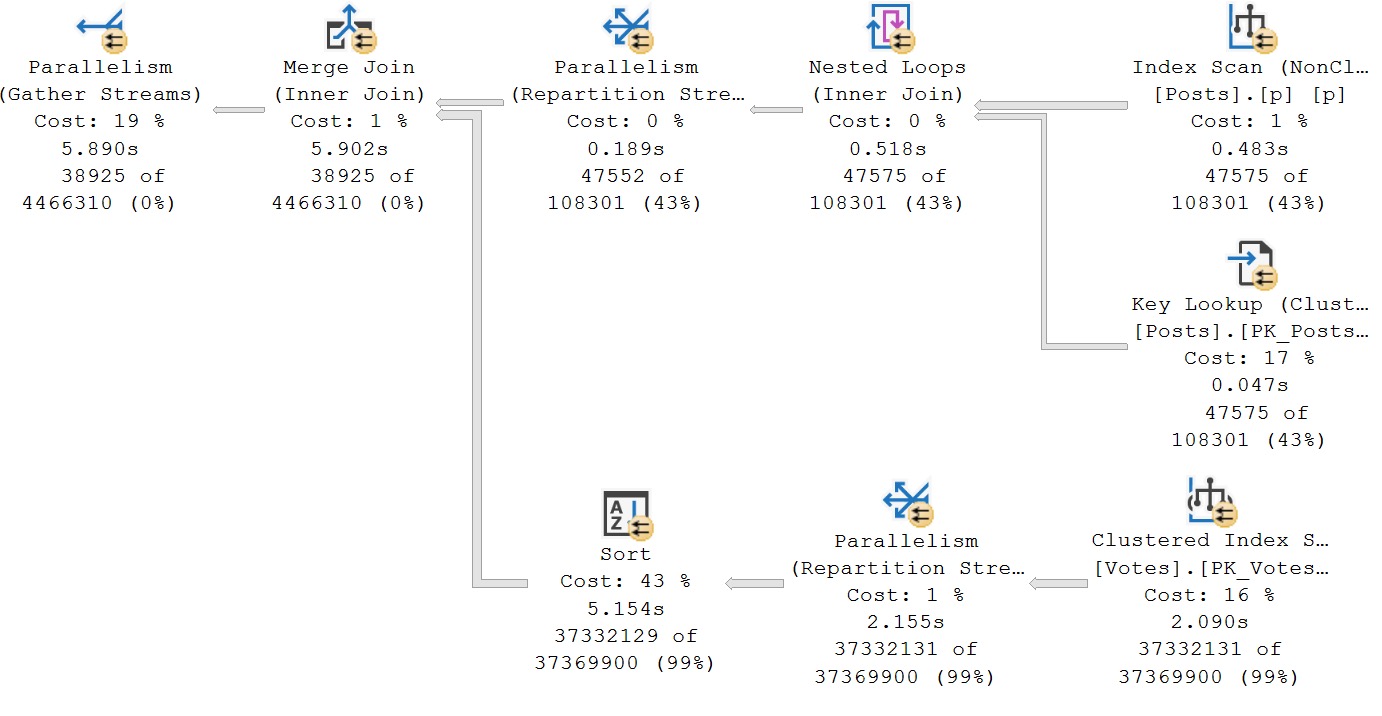
Look at this monstrosity. A parallel merge join that requires a sort to enable its presence. Who would contrive such a thing?
A Sidebar
This is, of course, a matter of costing. For some reason the optimizer considered many other alternatives, and thought this one was the cheapest possible way to retrieve data.
For reference, the above query plan has an estimated cost of 2020.95 query bucks. Let’s add a couple hints to this thing.
SELECT
p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
AND v.VoteTypeId = 2
ORDER BY
p.Id
OPTION
(
HASH JOIN,
USE HINT('DISALLOW_BATCH_MODE')
);
Using this query, I’m telling SQL Server to use a hash join instead of a merge join. I’m also restricting batch mode to keep things a bit more fair, since the initial query doesn’t use it.
Here’s the execution plan:

SQL Server’s cost-based optimizer looks at this plan, and thinks it will cost 13844 query bucks to execute, or nearly 6x the cost of the merge join plan.
Of course, it finishes about 5 seconds faster.
Like I end up having to tell people quite a bit: query cost has nothing to do with query speed. You can have high cost queries that are very fast, and low cost queries that are very slow.
What’s particularly interesting is that on the second run, memory grant feedback kicks in to reduce the memory grant to ~225MB, down from the initial granted memory of nearly 10GB.
The first query retains a 2.5GB memory grant across many executions, because sorting the entire Votes table requires a bit of memory for the effort.
But This Is About Indexes, Not Hints
With that out of the way, let’s think about an index that would help the Votes table not need sorting.
You might be saying to yourself:
SELECT
p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId /*We have to sort by this column for the merge join, let's put it first in the index*/
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
AND v.VoteTypeId = 2 /*We can put this second in the index so we don't need to do any lookups for it*/
ORDER BY
p.Id; /*It's the clustered primary key, so we can just let the nonclustered index inherit it*/
Which would result in this index:
CREATE INDEX
v
ON dbo.Votes
(PostId, VoteTypeId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
And you’d be right this time, but you wouldn’t be right every time. With that index, this is the plan we get:
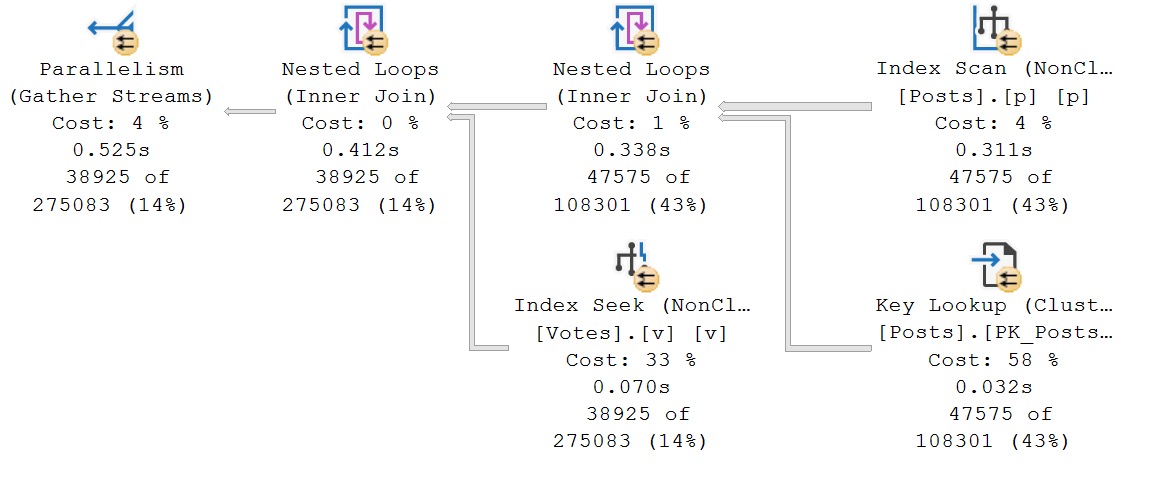
The optimizer chooses apply nested loops, and seeks both to the PostIds and VoteTypeIds that we care about.
That Won’t Always Happen
Sometimes, you’ll need to reverse the columns, and use an index like this:
CREATE INDEX
v2
ON dbo.Votes
(VoteTypeId, PostId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
This can be useful when the where clause predicate is really selective, and the join predicate is less so. We can still get a plan without a sort, and I’ll talk about why in a minute.
For now, let’s marvel at the god awful query plan SQL Server’s optimizer chooses for this index:
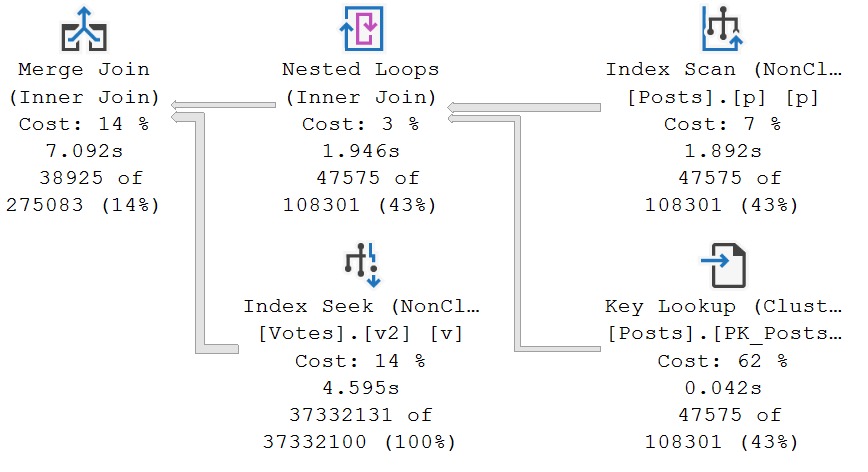
I think if I ever got my hands on the SQL Server source code, I’d cost merge joins out of existence.
But anyway, note that there’s no sort operator needed here.
Before I explain, let’s look at what the query plan would look like if SQL Server’s optimizer didn’t drink the hooch and screw the pooch so badly.
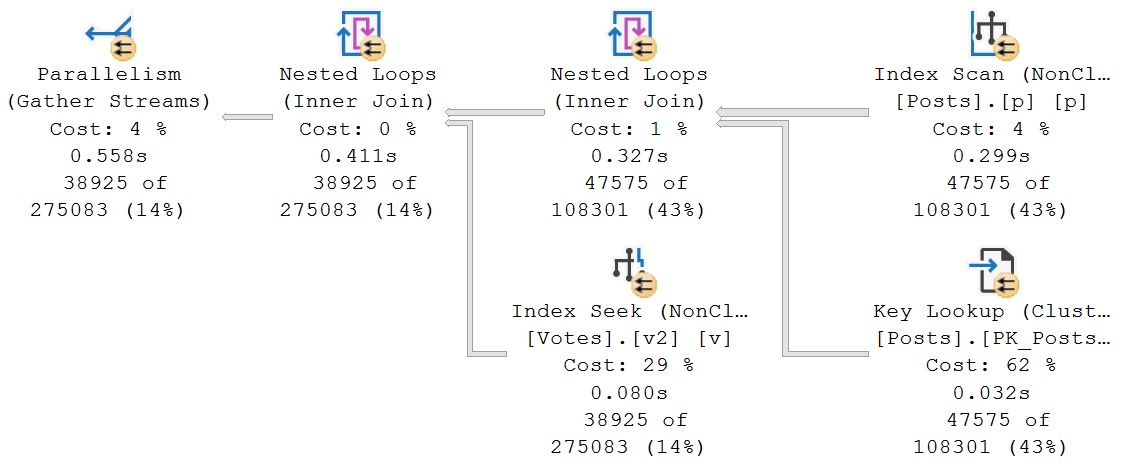
It’s equally as efficient, and also requires no additional sorting.
Okay, time to go to index school.
Index 101
Let’s say we have an index that looks like this:
CREATE INDEX
whatever_multi_pass
ON dbo.Users
(
Reputation,
UpVotes,
DownVotes,
CreationDate DESC
)
INCLUDE
(
DisplayName
);
In row store indexes, the key columns are in stored in sorted order to make it easy to navigate the tree to efficiently locate rows, but they are not stored or sorted “individually”, like in column store indexes.
Let’s think about playlists again. Let’s say you have one sorted by artist, release year, album title, and track number. Who knows, maybe someone (like DMX) released two great albums in a single year.
You would have:
- The artist name, which would have a bunch of duplicates for each year (if it’s DMX), duplicates for album title, and then unique track ids
- The release year, which may have duplicates (if it’s DMX) for each album, and then unique track ids
- The album title which would have duplicates for unique track id
But for each of those sets of duplicates, things would be stored in order.
So, going back to our index, conceptually the data would be stored looking like this, if we ran this query:
SELECT TOP (1000)
u.Reputation,
u.UpVotes,
u.DownVotes,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Reputation IN (124, 125)
AND u.UpVotes < 11
AND u.DownVotes > 0
ORDER BY
u.Reputation,
u.UpVotes,
u.DownVotes,
u.CreationDate DESC;
I’ve cut out some rows to make the image a bit more manageable, but here you go:
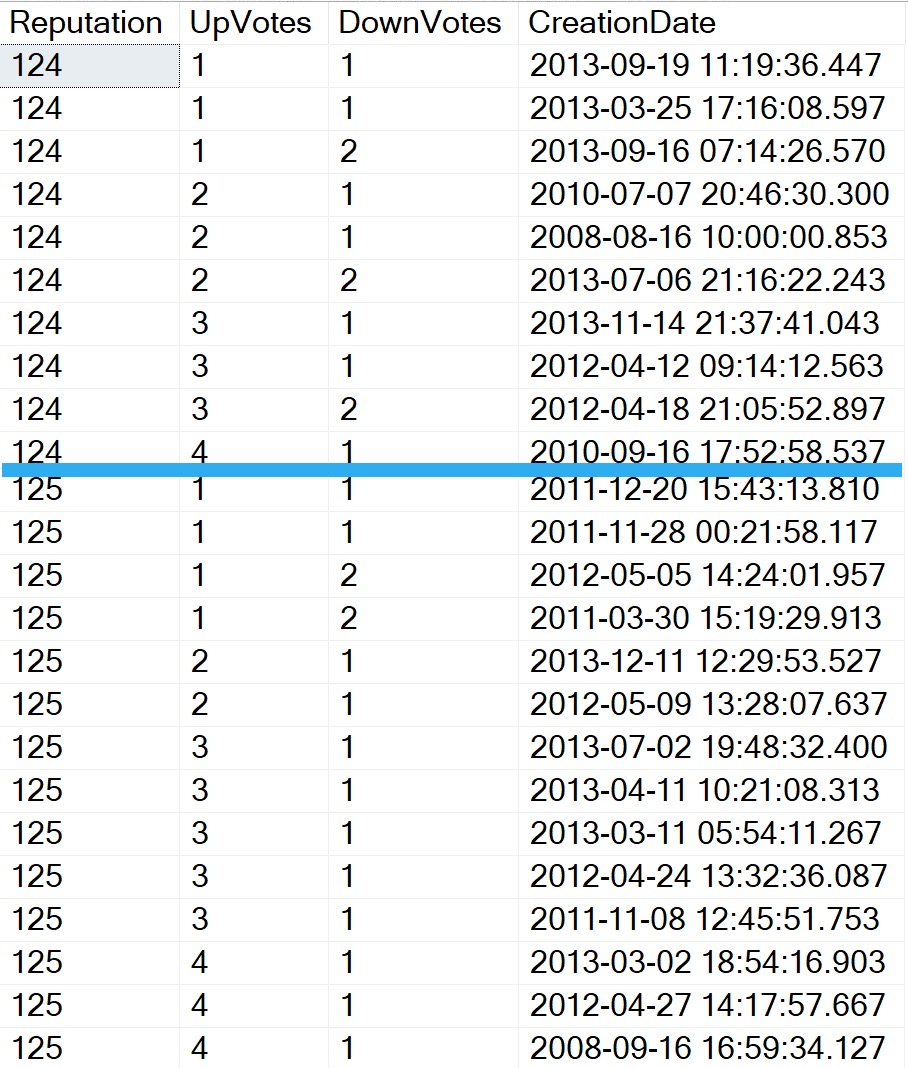
For every row where reputation is 124, upvotes are sorted in ascending order, and then for any duplicates in upvotes, downvotes are stored in ascending order, and for any duplicate downvotes, creation dates are stored in descending order.
Then we hit 125, and each of those “reset”. Upvotes starts over again at 1, which means we have new duplicate rows to sort downvotes for, and then new duplicate rows in downvotes to sort creation dates in.
Going back to our query, the reason why we didn’t need to sort data even when PostId was the second column is because we used an equality predicate to find VoteTypeIds with a value of 2. Within that entire range, PostId were stored in ascending order.
Understanding concepts like this is really important when you’re designing indexes, because you probably have a lot of complicated queries, with a lot of complicated needs:
- Multiple where clause predicates
- Multiple join columns to different tables
- Maybe with grouping and ordering
- Maybe with a windowing function
Getting indexes right for a single query can be a monumental feat. Getting indexes right for an entire workload can seem quite impossible.
The good news, though, is that not every query can or should have perfect indexes. It’s okay for some queries to be slow; not every one is mission critical.
Making that separation is crucial to your mental health, and the indexing health of your databases.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thought on “Indexing SQL Server Queries For Performance: Fixing A Sort”
Comments are closed.