Big, Bold Flavor
Since I first started reading about indexes, general wisdom has been to design the key of your indexes to support the most restrictive search predicates first.
I do think that it’s a good starting place, especially for beginners, to get acceptable query performance. The problem is that many databases end up designed with some very non-selective columns that are required for just about every query:
- Soft deletes, where most rows are not deleted
- Status columns, with only a handful of potential entries
Leaving the filtered index question out for the moment, I see many tables indexed with the “required” columns as the first key column, and then other (usually) more selective columns further along in the key. While this by itself isn’t necessarily a bad arrangement, I’ve seen many local factors lead to it contributing to bad performance across the board, with no one being quite sure how to fix it.
In this post, we’ll look at both an index change and a query change that can help you out in these situations.
Schema Stability
We’re going to start with two indexes, and one constraint.
CREATE INDEX
not_posts
ON dbo.Badges
(Name, UserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
not_badges
ON dbo.Posts
(PostTypeId, OwnerUserId)
INCLUDE
(Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
ALTER TABLE
dbo.Posts
ADD CONSTRAINT
c_PostTypeId
CHECK
(
PostTypeId > 0
AND PostTypeId < 9
);
GO
The index and constraint on the Posts table are the most important. In this case, the PostTypeId column is going to play the role of our non-selective leading column that all queries “require” be filtered to some values.
You can think of it mentally like an account status, or payment status column. All queries need to find a particular type of “thing”, but what else the search is for is up to the whims and fancies of the developers.
A Reasonable Query?
Let’s say this is our starting query:
SELECT
DisplayName =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE u.Id = b.UserId
),
ScoreSum =
SUM(p.Score)
FROM dbo.Badges AS b
CROSS APPLY
(
SELECT
p.Score,
n =
ROW_NUMBER() OVER
(
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = b.UserId
AND p.PostTypeId < 3
) AS p
WHERE p.n = 0
AND b.Name IN (N'Popular Question')
GROUP BY
b.UserId;
Focusing in on the CROSS APPLY section where the Posts table is queried, our developer has chosen to look for PostTypeIds 1 and 2 with an inequality predicate. Doing so yields the following plan, featuring an Eager Index Spool as the villain.
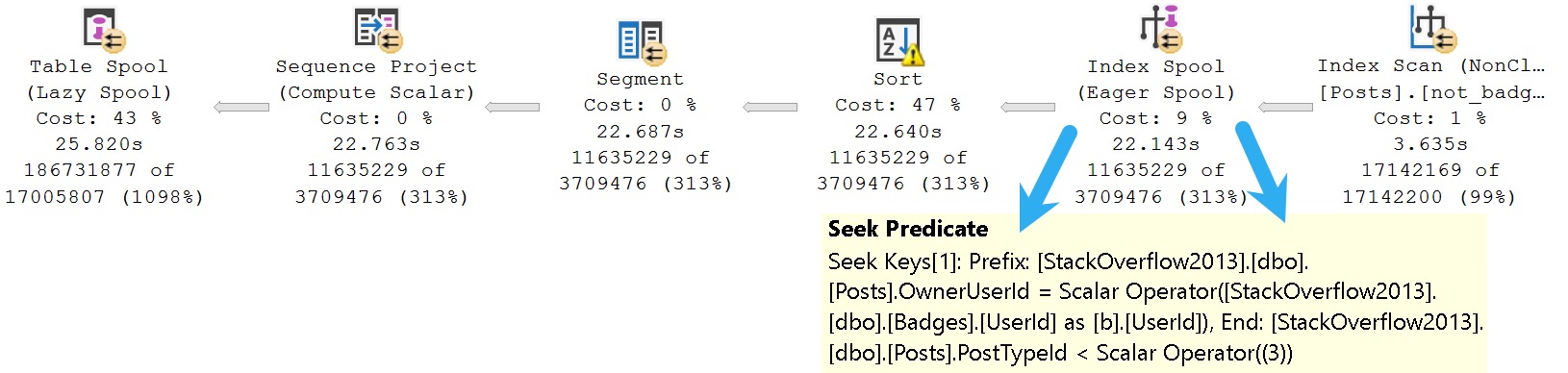
SQL Server decided to scan our initial index and create a new one on the fly, putting the OwnerUserId column first, and the Score column second in the key of the index. That’s the reverse of what we did.
Leaving aside all the icky internals of Eager Index Spools, one can visually account for about 20 full seconds of duration spent on the effort.
Query Hints To The Rescue?
I’ve often found that SQL Server’s query optimizer is just out to lunch when it chooses to build an Eager Index Spool, but in this case it was the right choice.
If we change the query slightly to use a hint (FROM dbo.Posts AS p WITH(FORCESEEK)) we can see what happens when we use our index the way Codd intended.
It is unpleasant. I allowed the query to execute for an hour before killing it, not wanting to run afoul of my laptop’s extended warranty.
The big problem of course is that for each “seek” into the index, we have to read the majority of the rows across two boundaries (PostTypeId 1 and PostTypeId 2). We can see that using the estimated plan:

Because our seek crosses range boundaries, the predicate on OwnerUserId can’t be applied as an additional Seek predicate. We’re left applying it as a residual predicate, once for PostTypeId 2, and once for PostTypeId 1.
The main problem is, of course, that those two ranges encompass quite a bit of data.
+------------+------------+ | PostTypeId | count | +------------+------------+ | 2 | 11,091,349 | | 1 | 6,000,223 | | 4 | 25,129 | | 5 | 25,129 | | 3 | 167 | | 6 | 166 | | 7 | 4 | | 8 | 2 | +------------+------------+
11 million rows for 2, and 6 million rows for 1.
Changing The Index
If you have many ill-performing queries, you may want to consider changing the order of key columns in your index to match what would have been spooled:
CREATE INDEX
not_badges_x
ON dbo.Posts
(OwnerUserId, PostTypeId)
INCLUDE
(Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
This gets rid of the Eager Index Spool, and also the requirement for a FORCESEEK hint.

At this point, we may need to contend with the Lazy Table Spool in order to get across the finish line, but we may also consider getting a query from ~30 seconds down to ~4 seconds adequate.
Of course, you may just have one query suffering this malady, so let’s look at a query rewrite that also solves the issue.
Optimizer Inflexibility
SQL Server’s query optimizer, for all its decades of doctors and other geniuses working on it, heavily laden with intelligent query processing features, still lacks some basic capabilities.
With a value constraint on the table telling the optimizer that all data in the column falls between the number 1 and 8, it still can’t make quite a reasonable deduction: Less than 3 is the same thing as 1 and 2.
Why does it lack this sort of simple knowledge that could have saved us so much trouble? I don’t know. I don’t even know who to ask anymore.
But we can do it! Can’t we? Yes! We’re basically optimizer doctors, too.
With everything set back to the original two indexes and check constraint, we can rewrite the where clause from PostTypeId < 3 to PostTypeId IN (1, 2).
If we needed to take extraordinary measures, we could even use UNION ALL two query against the Posts table, with a single equality predicate for 1 and 2.
Doing this brings query performance to just about equivalent with the index change:

The main upside here is the ability for the optimizer to provide us a query plan where there are two individual seeks into the Posts table, one for PostTypeId 1, with an additional seek to match OwnerUserId, and then one additional seek for PostTypeId 2, with an additional seek to match OwnerUserId.

This isn’t always ideal, of course, but in this case it gets the job fairly well done.
Plan Examiner
Understanding execution plans is sometimes quite a difficult task, but learning what patterns to look for can save you a lot of standing about gawping at irrelevancies.
The more difficult challenge is often taking what you see in an execution plan, and knowing what options you have available to adjust them for better performance.
In some cases, it’s all about establishing better communication with the optimizer. In this post, I used a small range (less than 3) as an example. Many dear and constant readers might find the idea that someone would write that over a two value IN clause ridiculous, but I’ve seen it. I’ve also seen it in more reasonable cases for much larger ranges.
It’s good to understand that the optimizer doesn’t have infinite tricks available to interpret your query logic into the perfect plan. Today we saw that it was unable to change < 3 to = 1 OR = 2, and you can bet there are many more such reasonable simplifications that it can’t apply, either.
Anyway, good luck out there. If you need help with these things, the links in the below section can help you get it from me.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Based on Oracle 7.x and the behaviors of their B-Trees, I was told by a very wise man (who worked there and authored books that are still amazing advice) to order the index columns by selectivity. The reasoning had to do with index leaf block splits and it made perfect sense to me. Of course, those were much simpler times and certain vendors always ignored that and basically put the least distinct column first. (I’m looking at you, SAP.)
I also have nightmares about ISAM on mainframes but therapy won’t help.
I realize times have changed and there are many different databases and index types. But your advice about matching the index with the eager spool and/or hints makes a lot of sense.
I apologize in advance for ignoring most of your comment, but the SAP thing gave me flashbacks to all of their clustered indexes on like a site id where there’s only ever going to be one site and they’re all 1s. It’s a level 9000 DBA joke I guess.
Clustered tables? Child’s play. Their concept of a pooled table is where the party has to start.
SAP customers are still using table pools in the older versions which were originally conceived because they had so many tables that Oracle 7.x couldn’t handle so many. Or so I’m told. 30 years later they’;ve gotten rid of most, if not all of those. The clusters remain.
A table pool is basically a 10(?) character field for the “table” name and a 50 character field for what passed for an index key. There was some under the covers manipulation via a proprietary database interface so that it wasn’t immediately obvious. Combine it with variable length data and a counter for the number of fields, you basically couldn’t query it from native SQL. A table pool could literally have thousands of entries that represented different “tables” but all belonged to a single table.
Here’s “ATAB” which might be a tad out of date as they allow table names of around 30 characters.
https://sap.erpref.com/?schema=ERP6EHP7&module_id=&table=ATAB
More horror:
https://help.sap.com/doc/saphelp_snc70/7.0/en-US/cf/21f083446011d189700000e8322d00/content.htm?no_cache=true
That’s only the beginning of how hilarious these funloving Germans would go to get revenge for WW1 and WW2.
Drink heavily.
😬😬😬