Round Up
Execution plans have come a long way over the years, gradually adding more and more details as computing power becomes less of a hurdle to collecting metrics.
The thing is, it’s not always obvious where to look or dig deeper into a query plan to figure out where problems are.
Right now, there are some warnings:
- At the root operator for a few different things
- For memory consuming operators when they spill
But there are some other things in query plans that should be loud and clear, because they’re not going to be obvious to folks just getting started out reading query plans.
Non-SARGable Predicates:
These can cause a lot of issues:
- Unnecessary scans
- Poor cardinality estimates
It’s primarily caused by:
- function(column) = something
- column + column = something
- column + value = something
- value + column = something
- column = @something or @something IS NULL
- column like ‘%something’
- column = case when …
- value = case when column…
- Mismatching data types (implicit conversion)
The thing is, it’s hard to see where this stuff happens in a plan, unless the plan is very small, or you’re looking directly at the query text, which is often truncated when pulled from a query plan. It would be nice if we got a warning of some sort on operators where this happened.
Predicates That Result In Scans
If you write a where clause, but don’t have an index with a key that matches that where clause, sometimes you’ll get a missing index request and sometimes you won’t. It’s a bit of a gamble of course.
For large tables, this can be painful, burn a lot of CPU, and result in a parallel plan where you could get by without one if you had a better index in place.
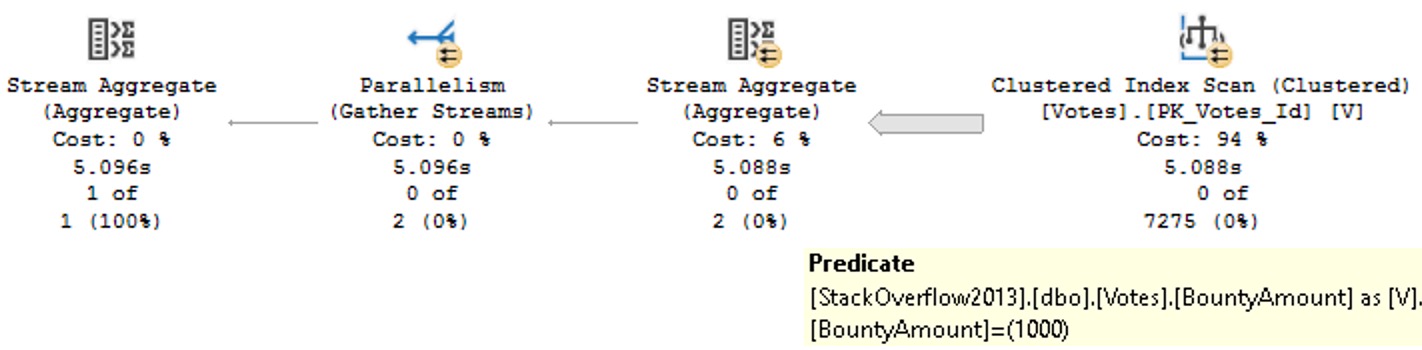
Of course, not every scan has a predicate: think joins without a where clause, or where only one table has a predicate against it. You don’t have much choice but to scan an index.
Eager Index Spools
Sometimes SQL Server wants an index so badly that it creates one on its own for you. When this happens on a large enough table, you can spend an awful lot of time waiting for it.
You know like when you put something in the microwave and you’re standing there staring at the timer and even though you set it for two minutes it seems to hang out at 1:30 forever? That’s what an Eager Index Spool is like. A Hungry Man Dinner that you microwave for an hour but still comes out with ice around the edges of your Salisbury Steak.
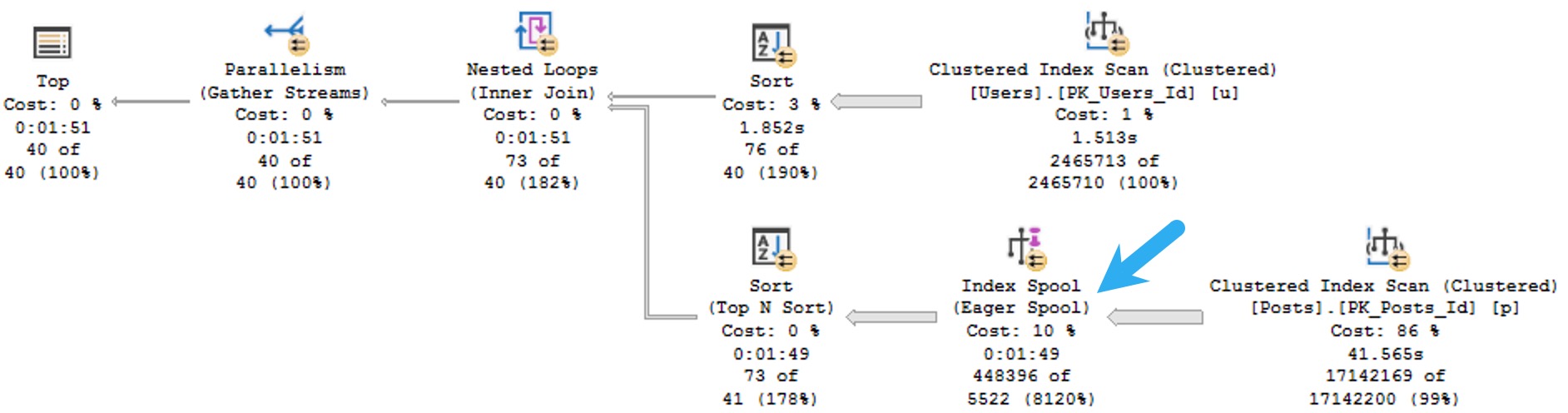
Okay, I stretched that one a bit. But here’s the thing: If SQL Server is gonna spend all that time creating a temporary index for you, it should tell you. Maybe a missing index request, maybe a warning on the spool itself. Just… anything that would help alert more casual execution plan observers to the fact that an index might not be the worst idea, here.
Why Indexes Weren’t Used
I know you. You create indexes all the time, then for some strange reason your queries don’t use them, or stop using them.
When SQL Server optimizes a query, part of the flow chart is a pit stop called index matching. At this point, SQL Server looks at available indexes and then chooses to use or not use them based on various pieces of feedback.
Sometimes it’s obvious why an index wasn’t used, like if it only covers a portion of the query, or if the key columns weren’t in the best order. Other times, it’s really unclear.
It would be nice if we had reasons for that available, even if it’s only in actual plans.
Louder Warnings For Deeper Problems
Right now, SQL Server buries some information that can be really important to why a query didn’t perform well:
- When estimated and actual rows or executions are way off
- When something forces a query to run serially
- When operators execute more than once (including rebinds and rewinds)
- When rows are badly skewed across parallel threads
The thing is, like a lot of these other items on this list, it takes real digging to figure out if any of them apply to you, and if they’re why your query slowed down. They just need some basic visual indicators to draw attention to them at the right times.
Different Per-Operator Details
When you look at each individual operator in an actual execution plan, you get sort of a confusing story:
- Estimated cost
- Wall clock time
- Actual rows
- Estimated rows
- Percent of actual to estimated rows
I’d throw out some of that, and show:
- CPU time
- Wall clock time
- Actual Rows
- Actual Executions
- Percent of actual to estimated
It would also be nice to have per-operator wait stats at this juncture, since we’d need to know why there’s a discrepancy between CPU and wall clock time, e.g. because of blocking or waiting on some other resource.
While we’re talking about all this, it might be helpful to consider the direction plans show their work. Right to left for data and left to right for logic are… fine. I guess. But up and down might make more sense. A lot of folks I know have a tough time understanding when things happen in horizontal execution plans, where vertical plans would be far more clear.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
It’s not at all frustrating that we keep thinking the engine has to be smarter and able to fix common problems, let alone they don’t highlight them for you. A simple hint in the messages pane would do wonders.
A thought that kept me up last night – why the heck even with the OPTIMIZE FOR, when what you’re trying to do is change query plan estimates… why isn’t there just a join hint that says for every row I expect 200 rows from this join, or 5, or 0.01. Why is there an OPTIMIZE FOR a parameter value that could change if a customer closes down, or is a start date and end date where the number of results could dramatically change over the course of a year?
I’m kind of glad for PSP but why not annotate the parameters you want to activate it on? (Because so many people would have to go and alter things to opt in vs plan cache yadda yadda).
Anyway, many minor gripes, but I would love some language bugs to be fixed and while they’re there, some logging of basic fixes to consider to query problems would be lovely.
Yeah, I had similar thoughts about PSP when I wrote speculatively about it a while back.
Comparing wall clock time to CPU time is a good one, if there’s a large difference I always want to know why that is, what is that operator waiting on or was it blocked. It would be great to see wait types and durations for slow operators.
Yep, same! It’d really help to have that be visible.
“Why Indexes Weren’t Used”
That would be huge. I posted a request for that on UserVoice a few years ago: https://web.archive.org/web/20201023000457/https://feedback.azure.com/forums/908035-sql-server/suggestions/34629823-explain-why-indexes-were-skipped
*Minor rant*: It was “migrated” to the new platform without my name or blog links or mockup: https://feedback.azure.com/d365community/idea/f1093f36-5025-ec11-b6e6-000d3a4f0da0
Wow, how did you memorize that URL?