Unavoidable
Having some key lookups in your query plans is generally unavoidable.
You’ll wanna select more columns than you wanna put in a nonclustered index, or ones with large data types that you don’t wanna bloat them with.
Enter the key lookup.
They’re one of those things — I’d say even the most common thing — that makes parameterized code sensitive to the bad kind of parameter sniffing, so they get a lot of attention.
The thing is, most of the attention that they get is just for columns you’re selecting, and most of the advice you get is to “create covering indexes”.
That’s not always possible, and that’s why I did this session a while back on a different way to rewrite queries to sometimes make them more efficient. Especially since key lookups may cause blocking issues.
Milk and Cookies
At some point, everyone will come across a key lookup in a query plan, and they’ll wonder if tuning it will fix performance.
There are three things to pay attention to when you look at a key lookup:
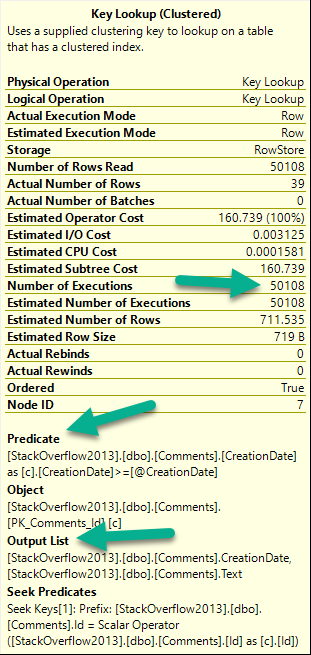
- Number of executions: This is usually more helpful in an actual plan
- If there are any Predicates involved: That means there are parts of your where clause not in your nonclustered index
- If there’s an Output List involved: That means you’re selecting columns not in your nonclustered index
For number of executions, generally higher numbers are worse. This can be misleading if you’re looking at a cached plan because… You’re going to see the cached number, not the runtime number. They can be way different.
Notice I’m not worried about the Seek Predicates here — that just tells us how the clustered index got joined to the nonclustered index. In other words, it’s the clustered index key column(s).
Figure It Out
Here’s our situation: we’re working on a new stored procedure.
CREATE PROCEDURE dbo.predicate_felon (@Score INT, @CreationDate DATETIME)
AS
BEGIN
SELECT *
FROM dbo.Comments AS c
WHERE c.Score = @Score
AND c.CreationDate >= @CreationDate
ORDER BY c.CreationDate DESC;
END;
Right now, aside from the clustered index, we only have this nonclustered index. It’s great for some other query, or something.
CREATE INDEX ix_whatever ON dbo.Comments (Score, UserId, PostId) GO
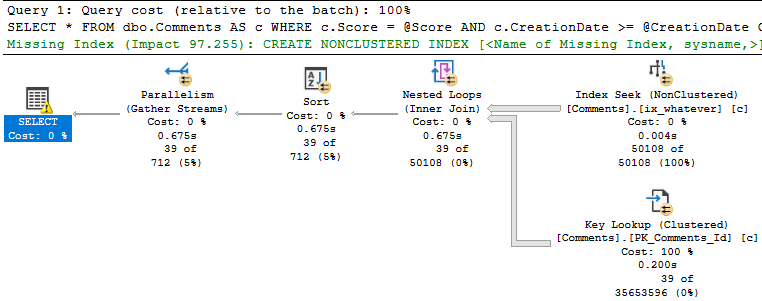
When we run the stored procedure like this, it’s fast.
EXEC dbo.predicate_felon @Score = 6, --Sixer
@CreationDate = '2013-12-31';
SQL Server wants an index — a fully covering index — but if we create it, we end up a 7.8GB index that has every column in the Comments table in it. That includes the Text column, which is an NVARCHAR(700). Sure, it fixes the key lookup, but golly and gosh, that’s a crappy index to have hanging around.
Bad Problems On The Rise
The issue turns up when we run the procedure like this:
EXEC dbo.predicate_felon @Score = 0, --El Zero
@CreationDate = '2013-12-31';
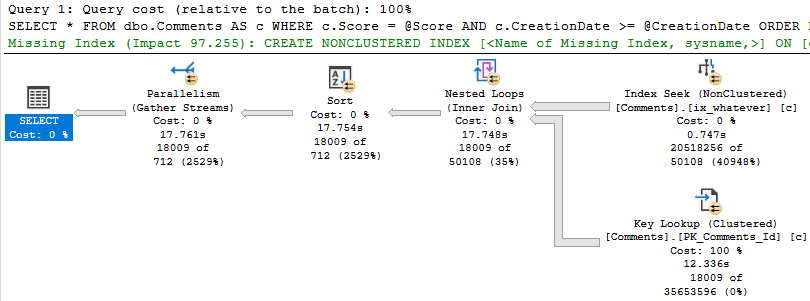
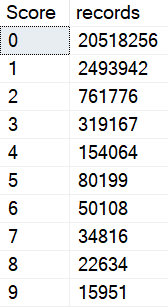
This happens because there are a lot more 0 scores than 6 scores.
Smarty Pants
Eagle eyed readers will notice that the second query only returns ~18k rows, but it takes ~18 seconds to do it.
The problem is how much time we spend locating those rows. Sure, we can Seek into the nonclustered index to find all the 0s, but there are 20.5 million of them.
Looking at the actual plan, we can spot a few things.
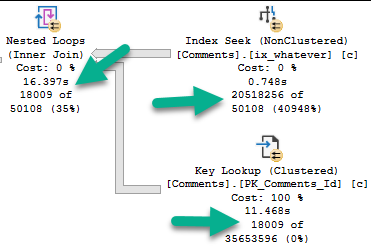
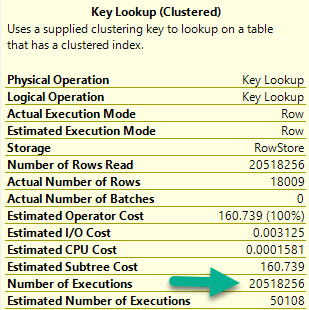
The 18k rows we end up with are only filtered to with they key lookup, but it has to execute 20.5 million times to evaluate that extra predicate.
If we just index the key columns, the key lookup to get the other columns (PostId, Text, UserId) will only execute ~18k times. That’s not a big deal at all.
CREATE NONCLUSTERED INDEX keys_only
ON dbo.Comments ( Score, CreationDate );
This index is only ~500MB, which is a heck of a lot better than nearly 8GB covering the entire thing.
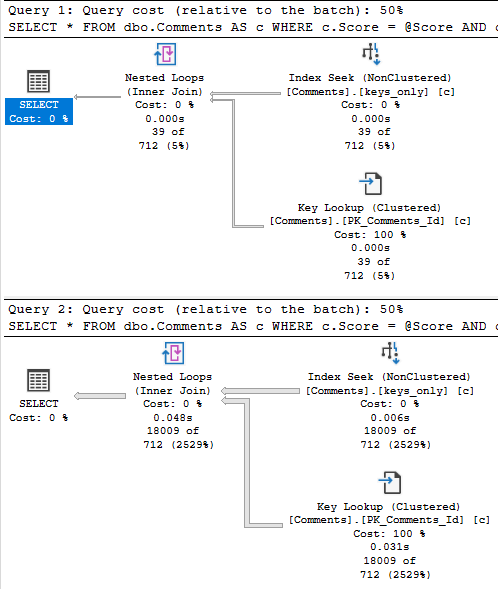
With that in place, both the score 6 and score 0 plans are fast.
Why This Is Effective, and When It Might Not Be
This works here because the date filter is restrictive.
When we can eliminate more rows via the index seek, the key lookup is less of a big deal.
If the date predicate were much less restrictive, say going back to 2011, boy oh boy, things get ugly for the 0 query again.
EXEC dbo.predicate_felon @Score = 6,
@CreationDate = '2011-12-31';
EXEC dbo.predicate_felon @Score = 0,
@CreationDate = '2011-12-31';
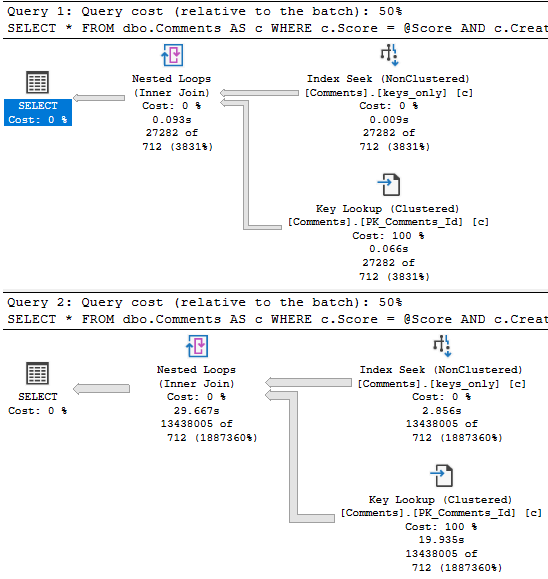
Of course, returning that many rows will suck no matter what, so this is where other techniques come in like Paging, or charging users by the row come into play.
What? Why are you looking at me like that?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This was a really helpful post, Erik. You do a great job explaining stuff. I seem to be able to understand concepts better after reading your posts than anybody else. I must be on the same level of crazy as you, I guess, lol!
Thanks again!
-Donny K
Thanks, Don! Appreciate the kind words.