Footnote
I have two queries. They return the same number of rows.
The only difference is one column in the select list.
This query has the Id column, which is the primary key and clustered index of the Posts table.
SELECT DISTINCT
p.Id, p.AcceptedAnswerId, p.AnswerCount, p.Body, p.ClosedDate,
p.CommentCount, p.CommunityOwnedDate, p.CreationDate,
p.FavoriteCount, p.LastActivityDate, p.LastEditDate,
p.LastEditorDisplayName, p.LastEditorUserId, p.OwnerUserId,
p.ParentId, p.PostTypeId, p.Score, p.Tags, p.Title, p.ViewCount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
The query plan for it looks like this:
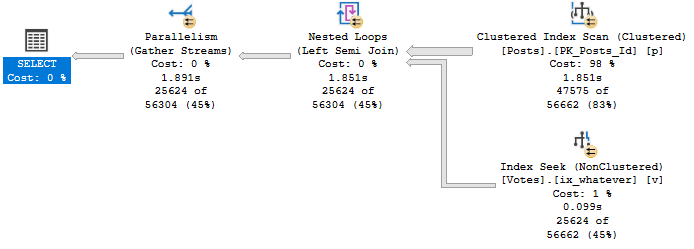
Notice that no operator in this plan performs any kind of aggregation.
There’s no Hash Match Aggregate, no Stream Aggregate, no Distinct Sort, NADA!
It runs for ~1.9 seconds to return about 25k rows.
Lessen
Watch how much changes when we remove that Id column from the select list.
SELECT DISTINCT
p.AcceptedAnswerId, p.AnswerCount, p.Body, p.ClosedDate,
p.CommentCount, p.CommunityOwnedDate, p.CreationDate,
p.FavoriteCount, p.LastActivityDate, p.LastEditDate,
p.LastEditorDisplayName, p.LastEditorUserId, p.OwnerUserId,
p.ParentId, p.PostTypeId, p.Score, p.Tags, p.Title, p.ViewCount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225';
This is what the query plan now looks like:

Zooming in a bit…

After we Scan the Posts table, we sort about 47k rows.
After the join to Votes, we aggregate data twice. There are two Stream Aggregate operators.
What do we sort?
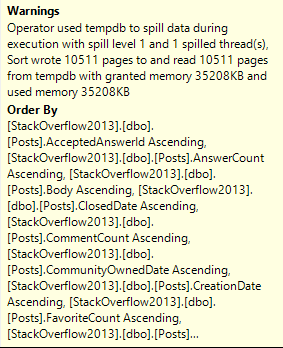
We Sort every column in the table by every column in the table.
In other words, we order by every column we’ve selected.
What do we aggregate?
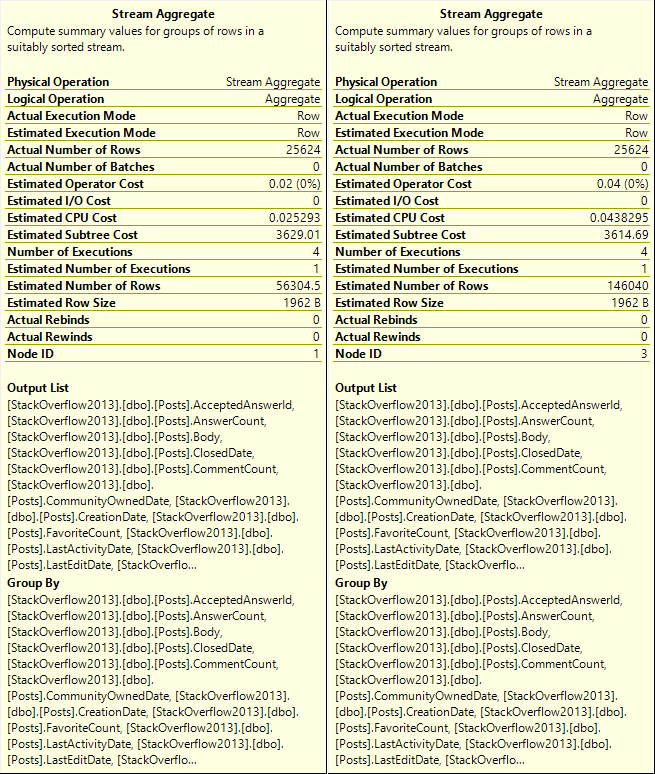
Everything. Twice.
What Does It All Mean?
When selecting distinct rows, it can be beneficial to include a column that the optimizer can guarantee is unique in the set of selected columns. Think of a primary key, or another column with a uniqueness constraint on it.
Without that, you can end up doing a lot of extra work to create a distinct result set.
Of course, there are times when that changes the logic of the query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.