Expresso
Let’s say you wanna get the highest thing. That’s easy enough as a concept.
Now let’s say you need to get the highest thing per user. That’s also easy enough to visualize.
There are a bunch of different ways to choose from to write it.
In this post, we’re going to use four ways I could think of pretty quickly, and look at how they run.
The catch for this post is that we don’t have any very helpful indexes. In other posts, we’ll look at different index strategies.
Query #1
To make things equal, I’m using CROSS APPLY in all of them.
The optimizer is free to choose how to interpret this, so WHATEVER.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT MAX(Score) AS Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
) AS ca
WHERE u.Reputation >= 100000
ORDER BY u.Id;
The query plan is simple enough, and it runs for ~17 seconds.

Query #2
This uses TOP 1.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1) p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
ORDER BY p.Score DESC
) AS ca
WHERE u.Reputation >= 100000
ORDER BY u.Id;
The plan for this is also simple, but runs for 1:42, and has one of those index spool things in it.
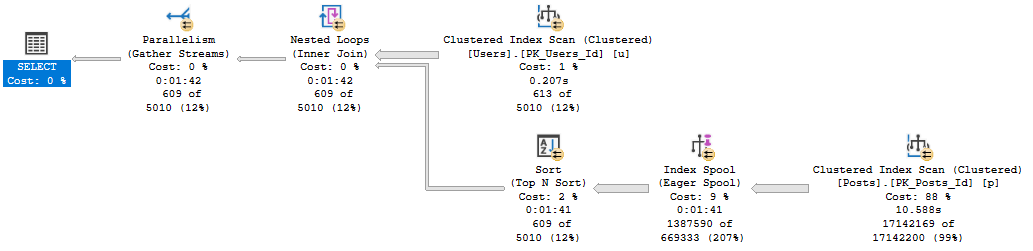
Query #3
This query uses row number rather than top 1, but has almost the same plan and time as above.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT p.Score,
ROW_NUMBER() OVER (ORDER BY p.Score DESC) AS n
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
) AS ca
WHERE u.Reputation >= 100000
AND ca.n = 1
ORDER BY u.Id;

Query #4
Also uses row number, but the syntax is a bit more complicated.
The row number happens in a derived table inside the cross apply, with the correlation and filtering done outside.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT *
FROM
(
SELECT p.OwnerUserId,
p.Score,
ROW_NUMBER() OVER (PARTITION BY p.OwnerUserId
ORDER BY p.Score DESC) AS n
FROM dbo.Posts AS p
) AS p
WHERE p.OwnerUserId = u.Id
AND p.n = 1
) AS ca
WHERE u.Reputation >= 100000
ORDER BY u.Id;
This is as close to competitive with Query #1 as we get, at only 36 seconds.

Wrap Up
If you don’t have helpful indexes, the MAX pattern looks to be the best.
Granted, there may be differences depending on how selective data in the table you’re aggregating is.
But the bottom line is that in that plan, SQL Server doesn’t have to Sort any data, and is able to take advantage of a couple aggregations (partial and full).
It also doesn’t spend any time building an index to help that one.
In the next couple posts, we’ll look at different ways to index for queries like this.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2017 CU 30: The Real Story With SelOnSeqPrj Fixes
- Getting The Top Value Per Group With Multiple Conditions In SQL Server: Row Number vs. Cross Apply With MAX
- Getting The Top Value Per Group In SQL Server: Row Number vs. Cross Apply Performance
- Multiple Distinct Aggregates: Still Harm Performance Without Batch Mode In SQL Server
One thought on “The Fastest Way To Get The Highest Value In SQL Server Part 1”
Comments are closed.