Fast Car
Some waits relate, but nearly all waits can be compensated for.
It’s all pulling levers, really. The Great And Powerful Oz has nothing on SQL Server.
More to the point, you can end up in quite a tangle with wait stats. I see people get bogged down in one or two metrics that they read are they worst thing you can ever see on a SQL Server, only to have them be totally unrelated to the problem at hand.
Go figure, the internet misled someone. At some point, this post will probably be misleading too. It might even be misleading right now.
Let’s talk about how to compensate for the common waits we talked about yesterday.
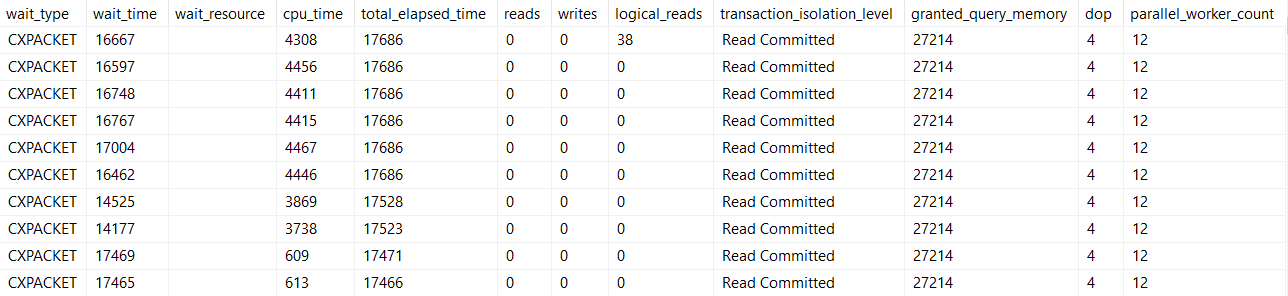
CXPACKET and CXCONSUMER
The fastest answer here is to check your settings. If these are at the defaults, you’re messing up. There’s a lot of competing points of view about how to set parallelism settings in SQL Server. The thing is, any of it can be wrong.
I don’t want to write this and have you think what I say is set in concrete. I want you to understand that I’m giving you a starting point, and it’s going to be up to you to figure out where to go from here.
MAXDOP (Max Degree Of Parallelism)
This is a fun one, because of the number of misconceptions around it. Here’s the way I go about it.
- If you have one NUMA node with <= 8 cores, you can probably leave it alone, though sometimes I’ll set it to 4 on a server with 8 cores (like my laptop, ha ha ha) if the server is in tough shape
- If you have one NUMA node with > 8 cores, set it to 8
- If you have more than one NUMA node with <= 8 cores, set it to the number of cores in a NUMA node
- If you have more than one NUMA node with > 8 cores, set it to 8
Will this work perfectly for everyone? No, but it’s a better starting place than 0. There are even some maintenance tasks that you might want to run with higher or lower MAXDOP, but that’s way beyond anything I want to get into here.
Plus, there’s all sorts of oddball CPU configurations that you can see, either because your VM admin has a permanent vape cloud around their head, or because some newer CPUs have non-traditional core counts that don’t follow the power of 2 increases (2, 4, 8, 16, 32, 64…) that CPUs have generally used.
If you leave MAXDOP set to 0, parallel queries can team up and really saturate your CPUs, especially if you don’t change…
CTFP (Cost Threshold For Parallelism)
The default for this is 5. This does not mean seconds. It meant seconds on one computer in the late 90s, but not anymore. I’d link to the post that talked about that one computer, but Microsoft nuked the blog it was on. Thanks, Microsoft.
It’s probably important for you not to have to think about all those old blogs when you’re concentrating so hard on quality CUs and documentation.
For everyone now, they’re sort of like Monopoly money. They don’t mean anything relative to your hardware. It’s not like weight, where you weigh different amounts based on the amount of gravity in your environment. These costs are only meaningful to the optimizer in coming up with plan choices.
Thing is, it’s really easy for a query to cost more than 5 of these whatevers. What’s important to understand up front is how this number is used.
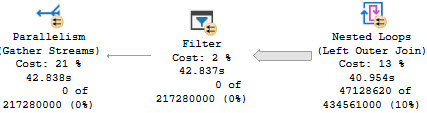
When the optimizer gets a query that it needs to come up with an execution plan for, the first thing it comes up with is a serial execution plan. If the cost of that serial plan is over the CTFP threshold, the optimizer will consider parallel plans (assuming nothing is preventing a parallel plan from being formed, like scalar functions, etc).
If the cost of the parallel plan is cheaper than the cost of the serial plan then SQL Server will go with that one. I’m gonna put this in bold, because it’s a question I answer all the time: The cost of a parallel plan does not have to be higher than CTFP.
Setting Cost Threshold For Parallelism
Well, okay then. This seems important to set correctly. If you have to start somewhere, 50 is a nice number. Do you have to leave it there? No, but just like MAXDOP, it’s a setting you’ll wanna tweak after some observations.
Most importantly, if critical queries got slower after making changes. If they did, we need to figure out if it’s because they either stopped going parallel, or stopped having a higher available degree of parallelism available to them.
Some people will tell you to look at the query costs in your plan cache to figure out what to set this to, but there are some really big problems with that advice: your plan cache could be really unstable, your plan cache could not have plans that are a good representation of your workload, and query plans lie.
Most of that goes for Query Store, too. Even though it theoretically has more history, it’s up to you to sift through everything in there to find the queries you care about trying to get MAXDOP right for.
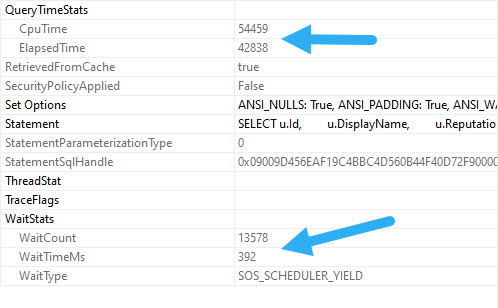
Sure, it’s nice if those CX waits go down when you make changes, since that’s what the settings we talked about most closely control. But there’s a more important wait that changing these can help limit, too.
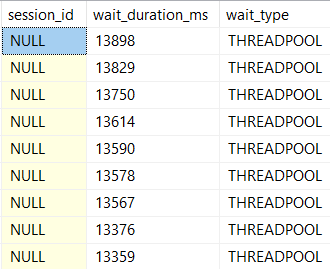
THREADPOOL
This is a wait you generally only want to see in demos done by professionals.
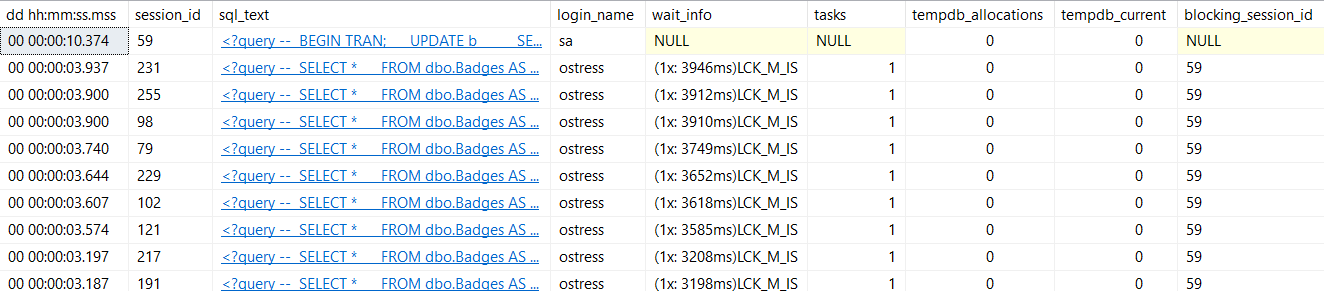
Why? Because it means SQL Server ran out of worker threads to give to queries so that they can run. It’s a really bad situation, because you might have a hard time figuring out what’s wrong.
- You might not be able to connect to your SQL Server
- Your monitoring tool might not be able to connect to your SQL Server
On top of that, your applications might not be able to connect, and even RDP connections might fail. You can mitigate some amount of THREADPOOL incidents by MAXDOP and CTFP correctly. Fewer queries going parallel, and perhaps going parallel to a lesser degree can reduce the number of worker threads that a workload consumes.
But just doing that can’t fix everything. If you just plain have a higher degree of concurrency than your hardware can handle, or if queries are stacking up because of issues with blocking, you still run the risk of this happening. You might need to add hardware or do significant query and index tuning to fix the problem completely.
And no, setting MAXDOP to 1 isn’t a viable solution.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.