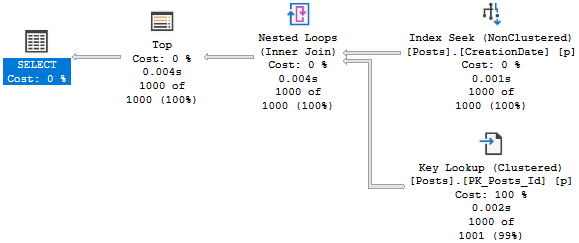
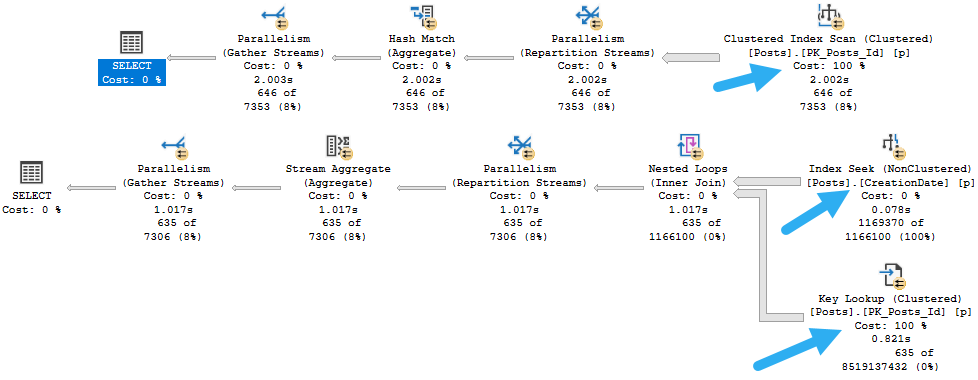
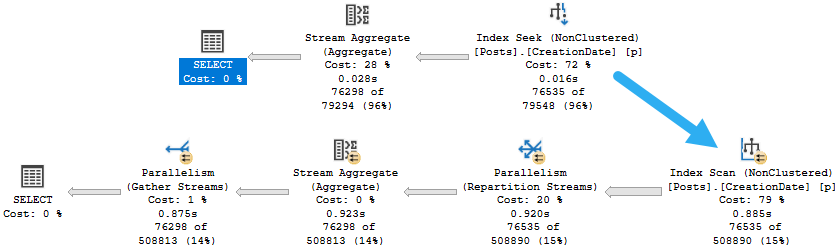
Facsimile
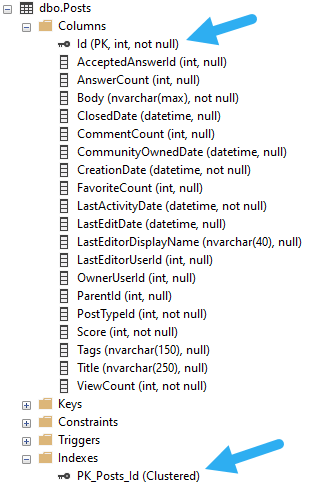
While clustered indexes or heaps are the table, nonclustered indexes are their own special little individual copies of the table data.
They’re ordered by the key columns that you choose, which should probably differ from your clustered index key column(s). There is, of course, no ordering of included columns.
Nonclustered indexes will also have different statistics, and a different set of underlying pages. If you’ve ever wondered why you can drop or disable a corrupt nonclustered index and recreate it, but you can’t do that with a clustered index, it’s because databases hate you and want you to suffer.
Downsides First
There are, of course, downsides to over-indexing a table. Your clustered index is generally there as a good foundation for everything else, but it can’t help everything.
Adding in nonclustered indexes will give you extra objects to:
- Write to and lock when you modify data
- Choices for the optimizer when it comes up with query plans
- Backup, restore, check for corruption, maintain
- Read into memory when you need to read them or write to them
Some caution needs to be exercised when creating indexes, of course. You’ll want to avoid overly wide indexes, and indexes that incorporate the same columns over and over again.
This can be complicated when creating wide tables that lack proper normalization. When you create tables that have many columns with a similar prefix, like “customer_”, it may be a sign that you those columns should be in a separate table with a key to connect it to other tables. Another sign is numbered columns, like “phone_1”, “phone_2” etc.
The more columns you add to a single table, the more trouble you’ll get into trying to index it. Users will want to search those tables in all variety of ways and want to return many different columns. It becomes quite difficult to effectively index a single table like that.
There are exceptions, of course. If you have a reporting table that is purposely denormalized, and has no transactional meaning, you can often afford more indexes being added to it, or even use columnstore indexes to aid reporting queries.
Mitigating Downsides
There are a number of things you can do to mitigate some of the issues you can run into with a lot of indexes, depending on what’s available to your version and edition of SQL Server.
For example, if you want to minimize locking issues, you should add NOLOCK everywhere. No but seriously, don’t do that unless you don’t care at all. A much better option is an optimistic isolation level. It’d be great if SQL Server used one by default, but it’s pointless to kick dust now.
Having good hardware, like enough memory to cache your heavily trafficked data, and write-friendly storage can also help with many issues around writes.
Of course, the indexes you need are going to be a personal issue. Some tables, and workloads, will be able to afford more indexing than others. Putting numbers on these things often takes some digging.
Coming back to the wide tables thing, you may find it difficult to stick to 5 or 10 indexes that have 5 or 10 columns in them without having a static group of queries that touches the table, and forget it if you write anything resembling “SELECT *” from a table like that.
Over Under
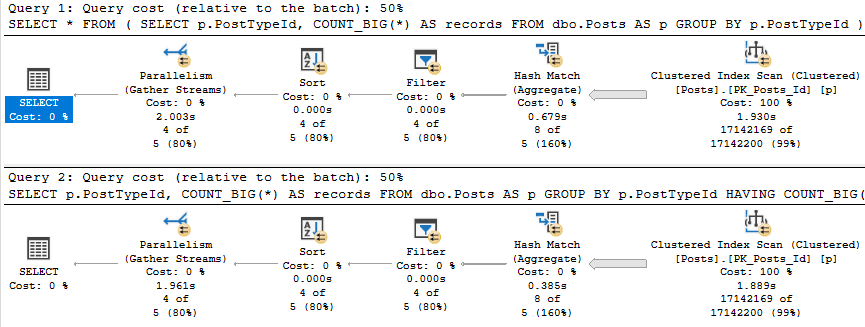
Deciding if a table is over-indexed comes down to looking at usage. If your server has been up for a month or longer, and you see a bunch of indexes that are totally unused by read queries, or queries that have way more writes then reads, you might wanna think about ditching those.
But always do this part first, because it’ll give you a more clear picture of what you should do with indexes that are leftover.
Other indexes that are safe to mess with are ones that have the exact same key columns. If they have different included columns, you can create one index to include them all.
Just remember to look for stuff in these index definitions like filters or uniqueness — those things can make indexes look a lot different to the optimizer.
Next we’ll start to talk about designing effective nonclustered indexes for your queries. Because that’s what we design indexes for, right? We don’t just make them up.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.