Bugger
Probably the most fascinating thing about Eager Index Spools to me is how often the optimizer will insert them into execution plans, often to a query’s detriment.
In a sane world, a non-loop join plan would be chosen, a missing index request would be registered that matches whatever would have been spooled into an index, and we’d all have an easier time.
While I understand that all of the optimizer stuff around spools in general was written before storage hardware wasn’t crap, and 32bit software couldn’t see more than a few gigs of memory, I do find it odd that so little revision and correction has been applied.
Of course, there are use cases for everything. I was involved in a data warehouse tuning project where rewriting a query to corner the optimizer into using a nested loops join was necessary to build an Eager Index Spool. Maintaining a nonclustered index on the staging table made data loads horrible, but letting SQL Server build one at query runtime was a massive improvement over other options. All that had to be done was to rewrite a simple inner join to remove any direct equality predicates.
While the below queries don’t even come mildly close to reproducing the performance improvement I’m talking about above, it should give you some idea of how it was done.
/*How it started*/
SELECT
p.Id,
UpMod =
SUM(CASE WHEN v.VoteTypeId = 2 THEN 1 ELSE 0 END),
DownMod =
SUM(CASE WHEN v.VoteTypeId = 3 THEN 1 ELSE 0 END),
PostScore =
SUM(p.Score)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON v.PostId = p.Id
WHERE p.Score > 1000
GROUP BY
p.Id;
/*How it's going*/
SELECT
p.Id,
UpMod =
SUM(CASE WHEN v.VoteTypeId = 2 THEN 1 ELSE 0 END),
DownMod =
SUM(CASE WHEN v.VoteTypeId = 3 THEN 1 ELSE 0 END),
PostScore =
SUM(p.Score)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON v.PostId >= p.Id
AND v.PostId <= p.Id
WHERE p.Score > 1000
GROUP BY
p.Id;
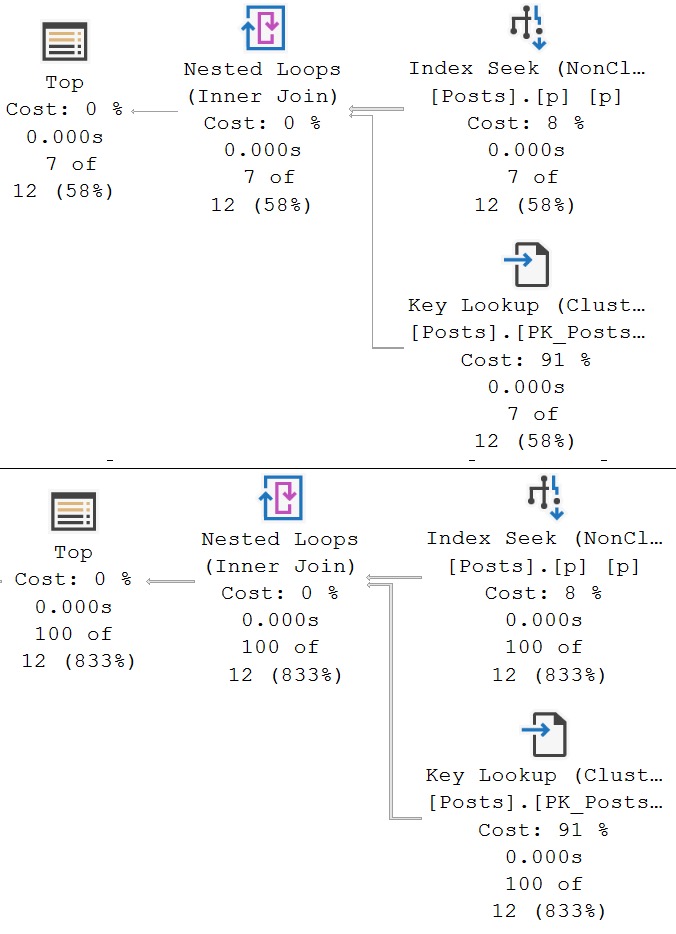
With no equality predicate in the join clause of the second query, only a nested loops join is available. But again, this is the type of thing that you should really have to push the optimizer to do.
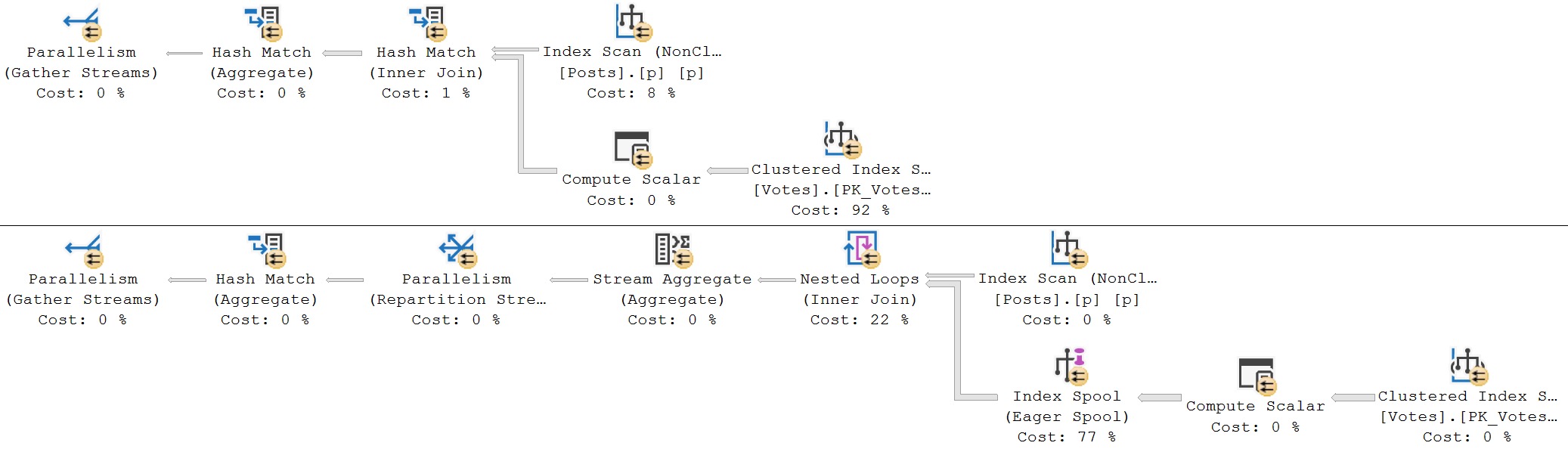
Of course, for the above queries, the second plan is a disaster, like most Eager Index Spool plans tend to be. The non-spool query with the hash join finishes in about 600ms, and the Eager Index Spool plan takes a full 1 minute and 37 seconds, with all of the time spent building the spool.
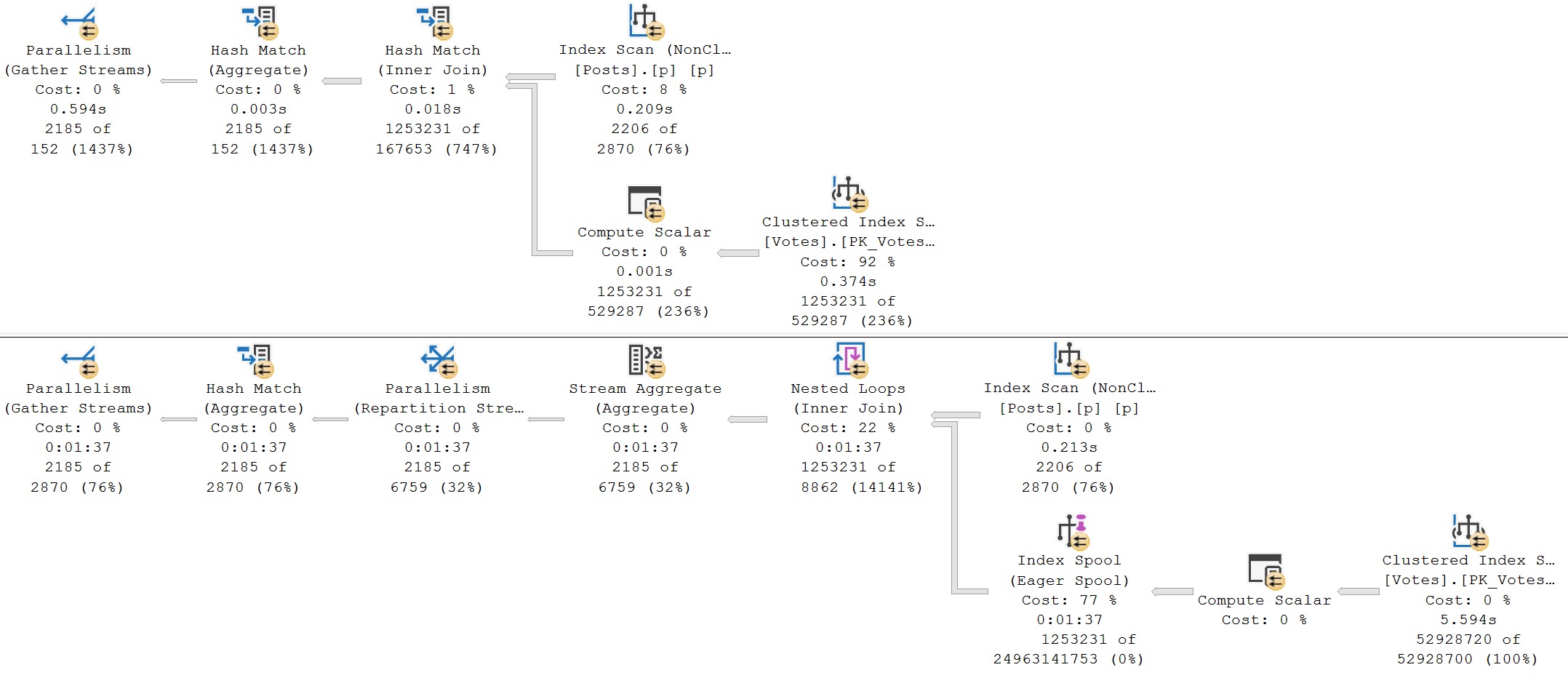
So, like I’ve been saying, one should really have to go out of their way to have this type of plan chosen.
Matter Worse
Compounding the issue is that the optimizer will sometimes choose Eager Index Spool plans when they are entirely unnecessary, and indexes exist to fully support query requirements.
The below join doesn’t actually work, because it’s not how the tables are related, but it’s a good example of that I mean.
SELECT
u.Id,
u.DisplayName,
p.*
INTO #p1
FROM dbo.Users AS u
OUTER APPLY
(
SELECT
Score = SUM(p.Score),
AnswerCount = SUM(p.AnswerCount)
FROM dbo.Posts AS p
WHERE p.Id = u.Id
) AS p;
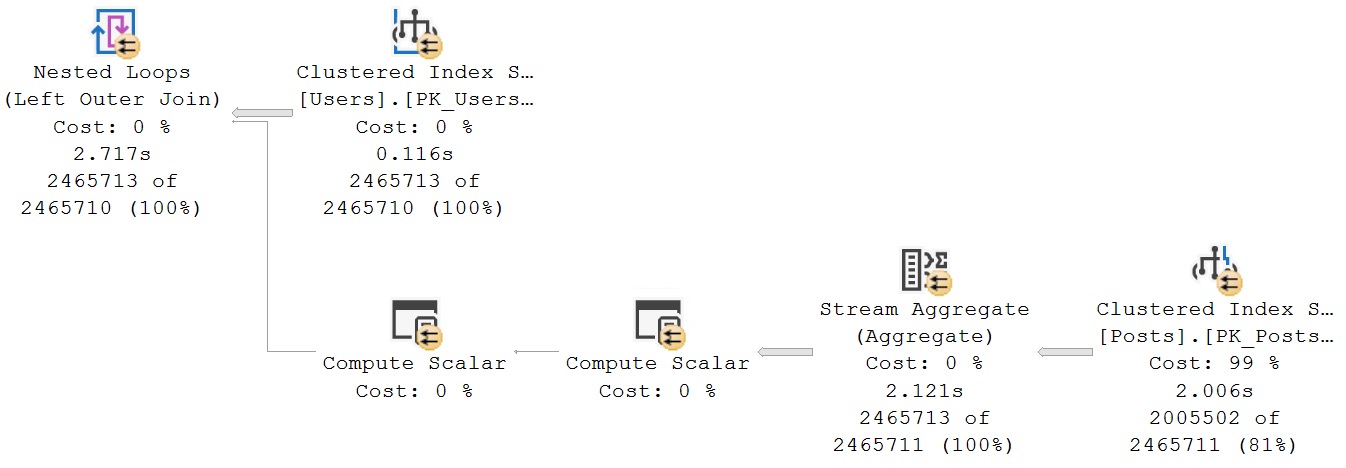
The Id column in both the Users table and Posts table is the clustered primary key. There’s no sensible reason for an index to be created at runtime, here.
Of course, the Posts table relates to the Users table via a column called OwnerUserId, but whatever.
The point is the resulting query plan.
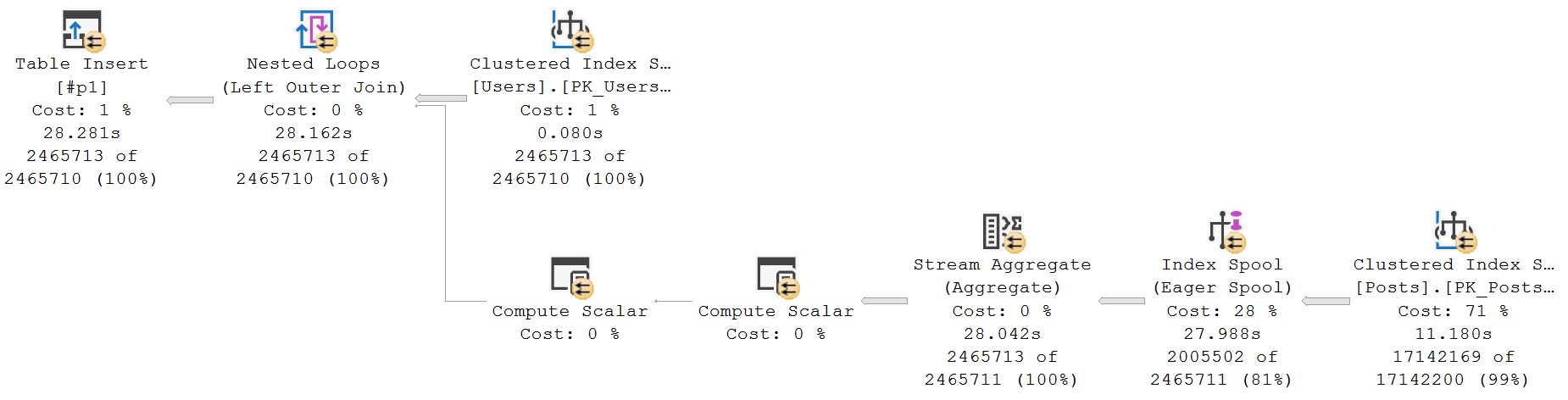
If we tell the optimizer that’s it’s being a dunce, we get a better, much faster, Eager Index Spool-free query plan.
SELECT
u.Id,
u.DisplayName,
p.*
INTO #p2
FROM dbo.Users AS u
OUTER APPLY
(
SELECT
Score = SUM(p.Score),
AnswerCount = SUM(p.AnswerCount)
FROM dbo.Posts AS p WITH (FORCESEEK) /*I am different*/
WHERE p.Id = u.Id
) AS p;
Sometimes this is the only way to solve spool problems.
Option One: Adding An Index
In most cases, Eager Index Spools are just really irritating missing index requests.
Here’s an example of one. The query itself touches the Posts table three times. Once to find questions, a second time to find answers related to those questions, and a third time to make sure it’s the highest scoring question for the answer.
SELECT TOP (100)
QuestionOwner =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE pq.OwnerUserId = u.Id
),
QuestionScore =
pq.Score,
QuestionTitle =
pq.Title,
AnswerOwner =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE pa.OwnerUserId = u.Id
),
AnswerScore =
pa.Score
FROM dbo.Posts AS pq
JOIN dbo.Posts AS pa
ON pq.Id = pa.ParentId
WHERE pq.PostTypeId = 1
AND pa.PostTypeId = 2
AND pa.Score >
(
SELECT
MAX(ps.Score)
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.Id <> pa.Id
)
ORDER BY
pa.Score DESC,
pq.Score DESC;
Are there many different ways to write this query? Yes. Would they result in different query plans? Perhaps, perhaps not.
Right now, this query has this index available to it, along with the clustered primary key on Id.
CREATE INDEX
p
ON dbo.Posts
(PostTypeId, ParentId, OwnerUserId)
INCLUDE
(Score)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
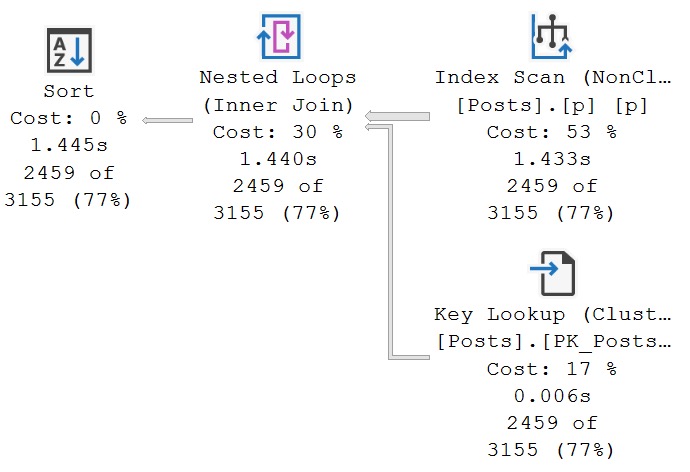
Because we don’t have an index that leads with ParentId, or that allows us to easily seek to ParentId in the MAX subquery (more on that later, though), the optimizer decides to build one for us.
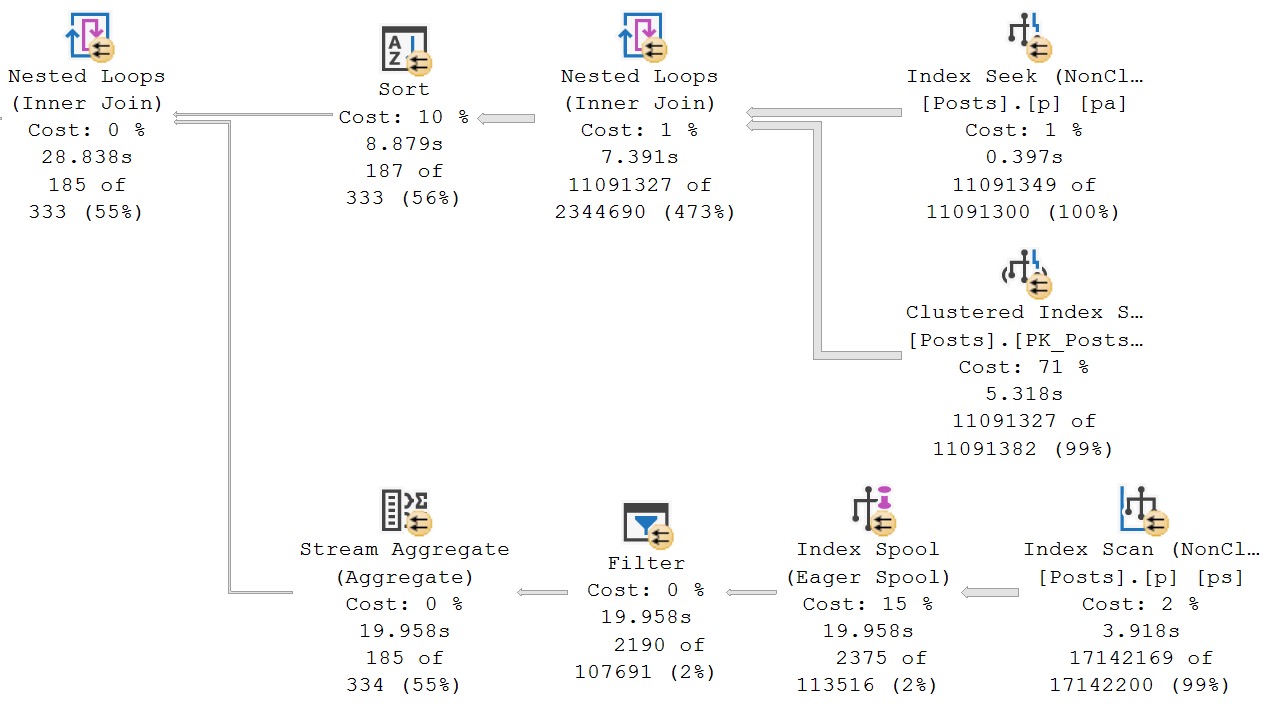
We can see what index the spool is building by looking at the tool tip. In general, you can interpret the seek predicate as what should be the key column(s), and what should be included by what’s in the output list.
There is sometimes some overlap here, but that’s okay. Just ignore any output columns that are already in the seek predicate. And of course, we can generally ignore any clustered index key column(s), since the nonclustered index will inherit those anyway.

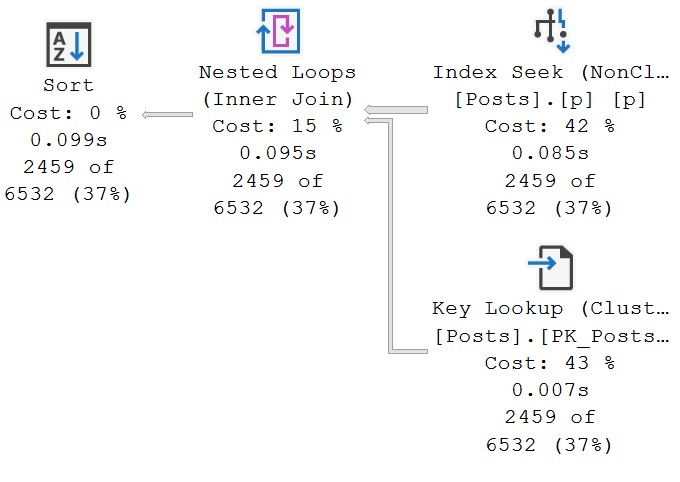
Adding this index will get rid of the Eager Index Spool:
CREATE INDEX
p2
ON dbo.Posts
(ParentId, Score)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
In this case, I’ve chosen to add the Score column to they key of the index to allow for an ordered aggregation (SUM function) to take place without a Sort operator.
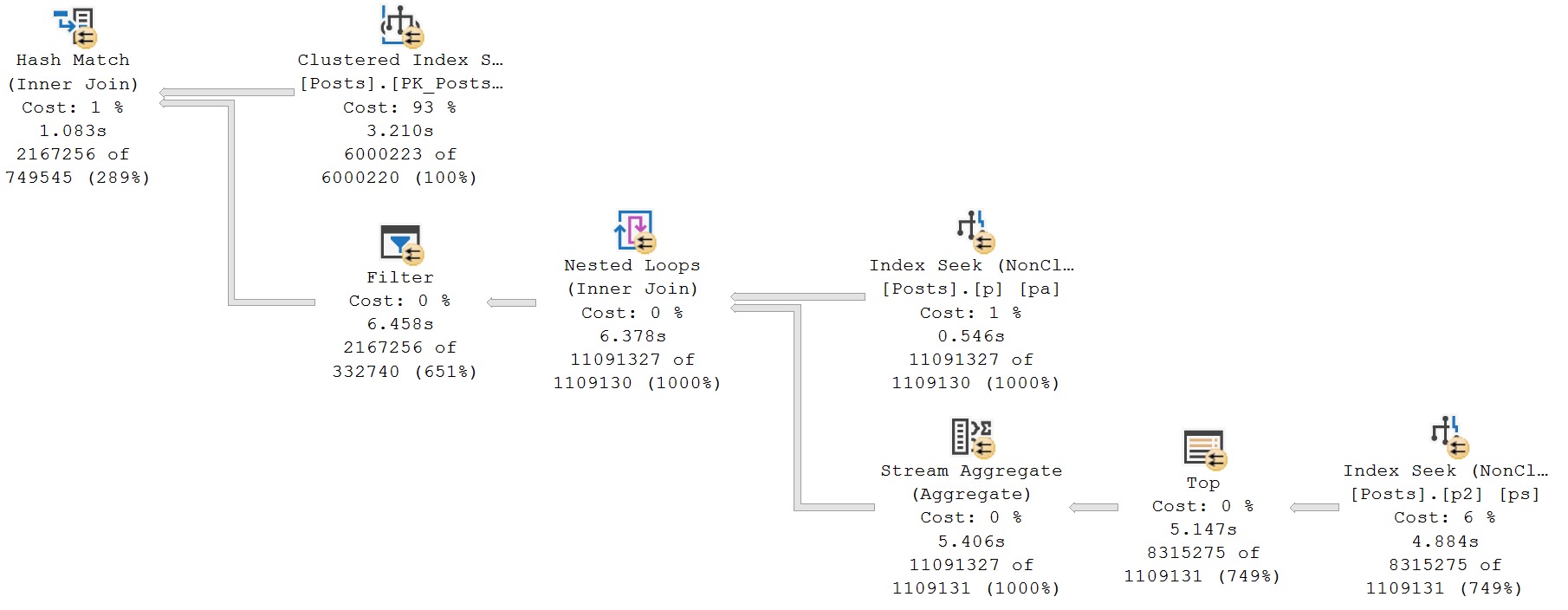
Option Two: Over Communicating
Let’s take a step back. We currently have this index, that leads with PostTypeId.
CREATE INDEX
p
ON dbo.Posts
(PostTypeId, ParentId, OwnerUserId)
INCLUDE
(Score)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
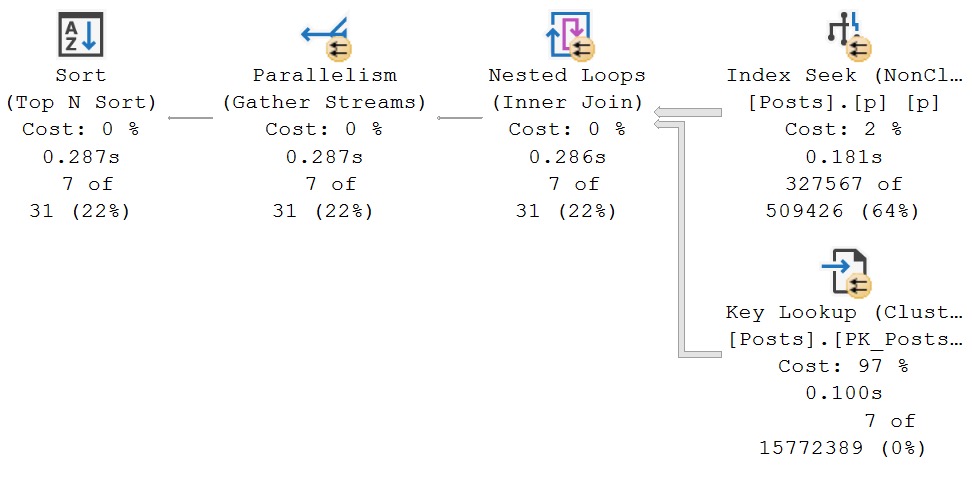
The section of the query that generates the Eager Index Spool is this one:
(
SELECT
MAX(ps.Score)
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.Id <> pa.Id
)
What we know, that the optimizer doesn’t know, is that only rows with a PostTypeId of 2 are answers. We don’t need to compare answers to any other kind of post, because we don’t care about them here.
If we change the subquery to limit comparing answers to other answers, it would also allow us to take care of the existing index by locating the right type of Post, and give seekable access to the ParentId column.
(
SELECT
MAX(ps.Score)
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.PostTypeId = 2
AND ps.Id <> pa.Id
)
That changes the full query to this:
SELECT TOP (100)
QuestionOwner =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE pq.OwnerUserId = u.Id
),
QuestionScore =
pq.Score,
QuestionTitle =
pq.Title,
AnswerOwner =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE pa.OwnerUserId = u.Id
),
AnswerScore =
pa.Score
FROM dbo.Posts AS pq
JOIN dbo.Posts AS pa
ON pq.Id = pa.ParentId
WHERE pq.PostTypeId = 1
AND pa.PostTypeId = 2
AND pa.Score >
(
SELECT
MAX(ps.Score)
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.PostTypeId = 2 /* I am new and different and you should pay attention to me */
AND ps.Id <> pa.Id
)
ORDER BY
pa.Score DESC,
pq.Score DESC;
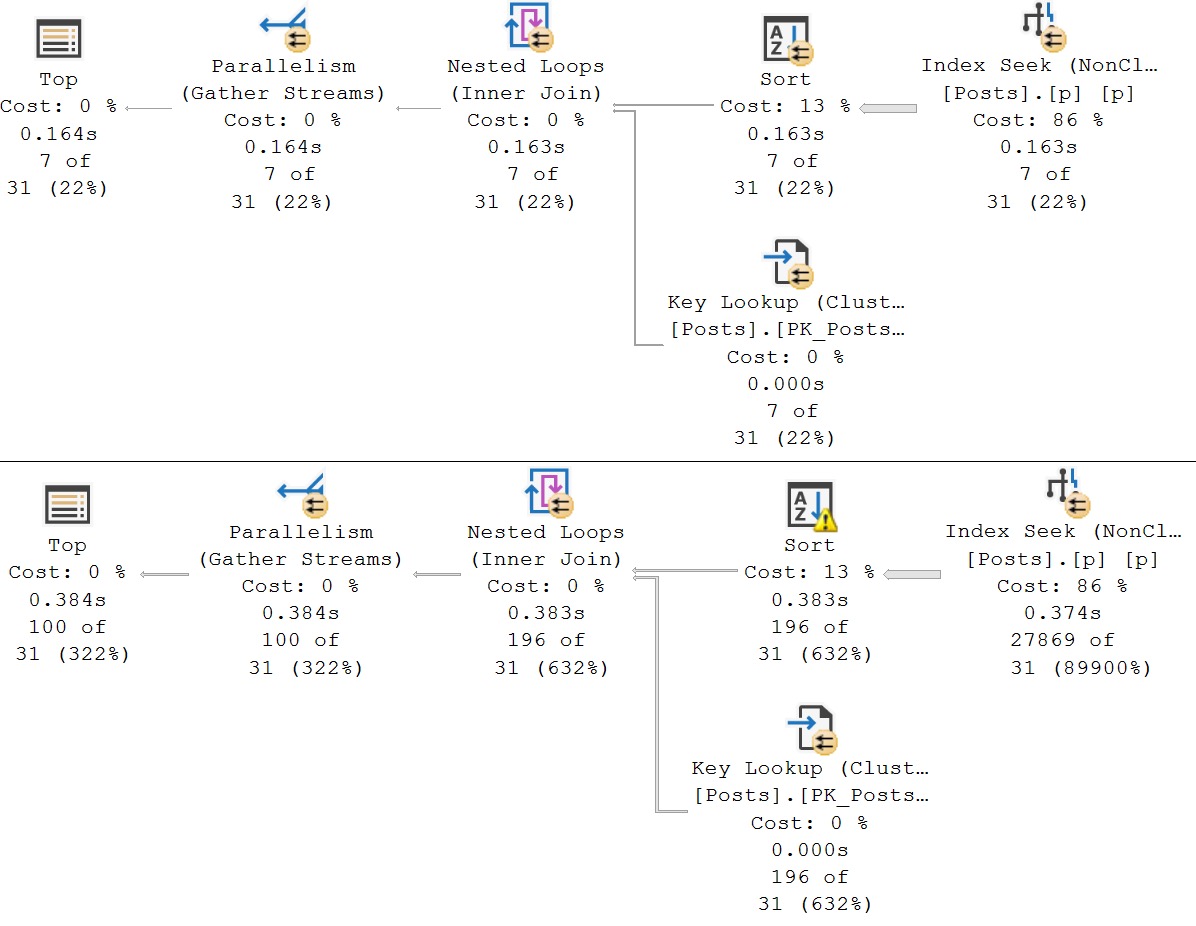
Which changes the section of the query plan that we’re concerned with to this:
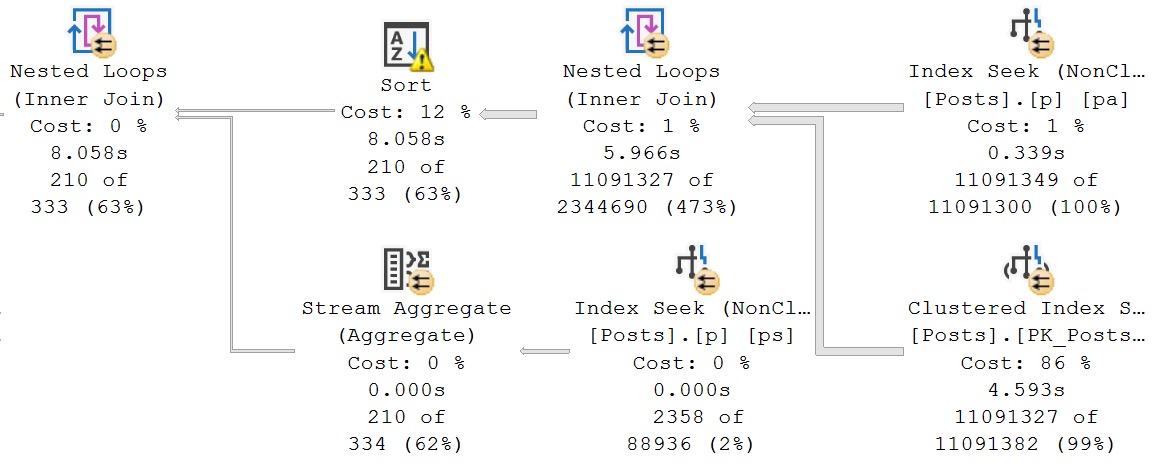
Sometimes the optimizer just needs a little but more information from you.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.