Economy Of Words
When someone says that something is slower than it was before, whether it’s a query, a whole SQL Server, a website, or an app screen, it’s almost never while the perceived slowness is happening, nor is it reproducible (especially when a consultant is watching).
There are some basic things you need to have historical record of if you wanna figure it out:
- What queries were running
- What queries were waiting on
- What was different from last time those queries ran
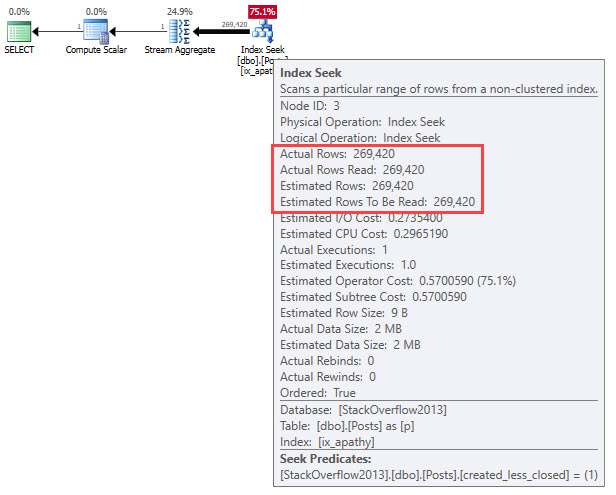
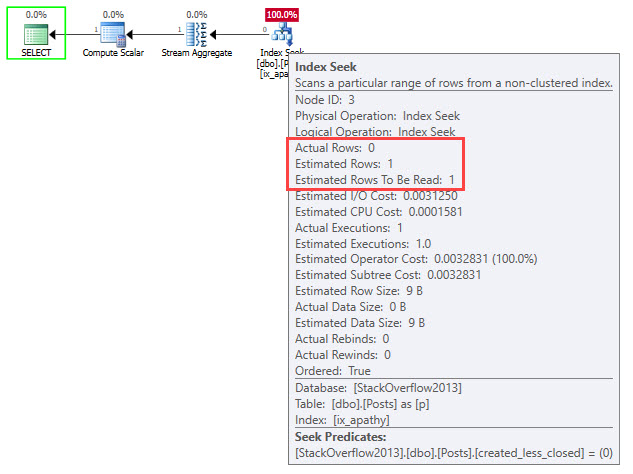
Microsoft has taken some steps to help us figure this out with Query Store, but really only for SQL Server 2017, when aggregated wait stats were added to the family of Query Store views.
But if you’re like most people, you’re not on SQL Server 2017, and even further into that segment, you don’t have Query Store enabled.
I think there’s more Microsoft could do to improve data that’s collected, but right now it’s just a collection of votes.
Right now, the GUI is so limited in what you can search for that I wrote a sp_QuickieStore to make working with the data easier.
Compared To What?
If you’re on older versions of SQL Server, including those about to be taken off life support, what are your options?
For Free!
- You can log sp_BlitzFirst output to tables, and use PowerBi to view the data.
- You can use Open Query Store to produce a similar data set to the Query Store feature.
- You can use sp_WhoIsActive, and log those results to a table
For Money!
There’s a whole landscape of SQL Server monitoring tools out there, as well as things people get confused with SQL Server monitoring tools.
Ultimately, the best monitoring tool for you is one you:
- Will actually use
- Will enable you to find problems
- Will enable you to solve problems
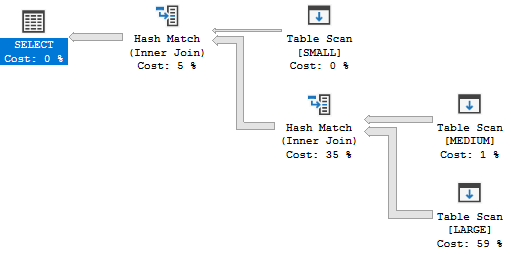
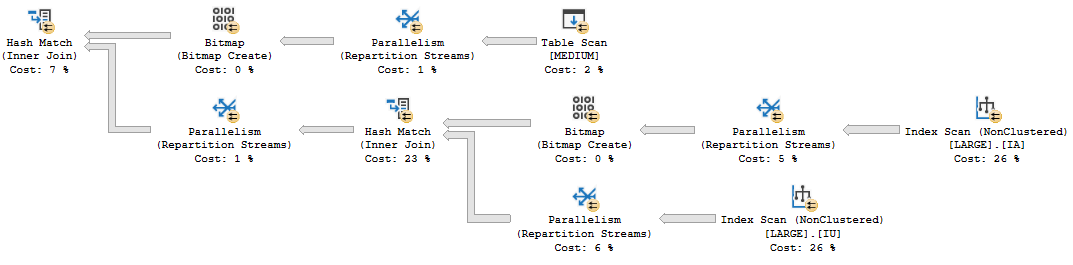
Getting overwhelmed with meaningless metrics (there were how many logouts per second?!), standalone charts that don’t allow you to correlate system activity to resource usage (save as image?!), or long lists of queries that may or may not run when anyone cares (yes, CHECKDB did a lot of reads, thanks) doesn’t help anyone. If that sounds like your monitoring tool, it might be time to trade it for a carton of Gatorade.
You’ve got a glorified FitBit strapped onto your SQL Server.
Here And Now
What’s currently happening on your SQL Server is often only a symptom of what’s been happening on your SQL Server for a long time.
There are very few problems I’ve seen that are truly “sudden”, unless someone recently made an ill-advised change to the server, like dropping an important index, etc.
The longer you let things like aging hardware, growing data, and ignoring query and index problems go, the worse things get.
Monitoring your server is a good first step, but it’s still up to you to address the problems, and address the right problems.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.