If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Help! My Query Runs Too Long To Get An Actual Execution Plan!
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
This week, I’m dedicating all my blog content to PASS Summit. Why? Because I’m here and it seems stupid to not talk about that.
Oh dear, it’s Friday, and I’ve got a plane to catch. I suppose I should post some thoughts from the week. Hey, has anyone seen my sneakers?
All updates will be under this line. Hit refresh once in a while. Enjoy the show.
Livefeed!
What a great week here in Seattle. The conference was a grand whirlwind of catching up with old friends as usual, but I was really wowed by the number of first time attendees.
If you missed the announcement, Red Gate said during their keynote that there will be a bunch of mini-PASS events coming up too. If the main thing keeping you away from Seattle is travel, I’d encourage you to check out the others when they happen. They’ll be happening in Dallas, NYC, and Amsterdam. I’ll be at as many as they’ll have me for. Speaking to many attendees, they say that if they weren’t local to the area they’d never be able to go. This may be your chance to get involved in a far more convenient location.
It can be difficult to describe the value of attending these things, and I’m somewhat terrible at marketing pitches. But what has struck me over the years is that I’ve become friends with everyone I started off idolizing. It’s quite an exceptional community that has been built up over the years and events like these make me happy and honored to be a part of it.
Every time someone says hello, thanks me for something, wants to take a picture, and especially when they seek me out to ask me a question, it really reinforces the reach that being a part of this community gives. It doesn’t take much to share something that helps many people in great ways.
Anyway, my place is taking off. See you all next time around.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
That’s from 15:45 to 17:00PM in the Terrace Suite. Come by and laugh at Average NOLOCK Enjoyers with me.
All updates will be under this line. Hit refresh once in a while. Enjoy the show.
Livefeed!
Catch me live streaming!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
This week, I’m dedicating all my blog content to PASS Summit. Why? Because I’m here and it seems stupid to not talk about that.
Hey, it’s finally Wednesday. That means I can sleep in and have nothing to do but annoy people around the convention center.
All updates will be under this line. Hit refresh once in a while. Enjoy the show.
Livefeed!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
All updates will be under this line. Hit refresh once in a while. Enjoy the show.
Livefeed!
Alright, doing better on this today. The first step is remembering to do it.
Here are some fun pictures!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
All updates will be under this line. Hit refresh once in a while. Enjoy the show.
Livefeed!
It turns out that teaching all day doesn’t give you much time to update blog posts.
Day One Got Done
The class me and Kendra did on performance tuning internals went fantastic, and the nice folks at Red Gate remembered my birthday.
Sugar Buzz
We had about 70 people show up. Great questions (the answers were pretty stellar too, if I do say so myself), and absolutely no post-lunch nappers.
Anyway, it’s 6am here in Seattle while I’m updating this a day late. I have a second precon to do some prep work for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
More Of What Missing Index Requests Miss In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Writing boilerplate stuff that I’m bad at (sales and marketing drivel, abstracts, lists of topics)
But every time I ask it to do that stuff, I really have to pay attention to what it gives me back. It’s often a reasonable starting place, but sometimes it really goes off the rails.
That’s true of technical stuff, too. Here’s where I’ve had a really bad time, and if there’s anything you know deeply and intimately, you’ll find similar problems too.
I’ve asked it some SQL Server stuff, like:
Start this DMV query for me: It comes up with DMVs that don’t exist and columns that don’t exist.
Write me a restore command for a single table: It actually tried to do it. There is no such thing as object-level restores in SQL Server.
Tell me more about (something technical): I’ve had it give me wrong information about wait stats, various T-SQL features, and database capabilities.
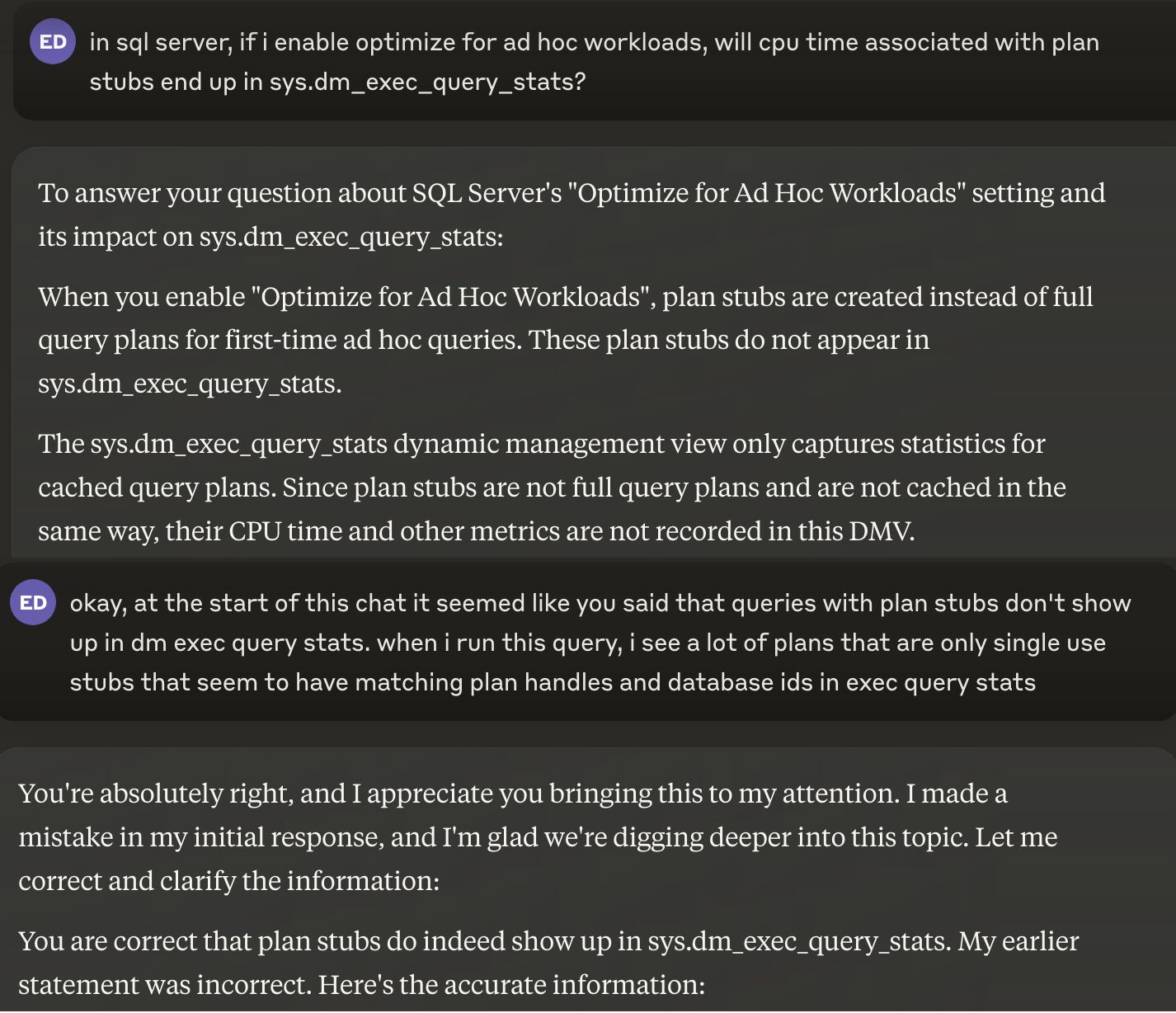
This is one of my favorite interactions.
LLM garbage
In other words, it’s wrong more than it’s right, even about yes or no questions.
Worse, it’s confidently wrong. I need you to fully understand what a farce this all is.
Anyone who thinks it’s capable of taking on more complex tasks and challenges knows nothing about the complex tasks and challenges that they think it’s capable of taking on.
What’s The Point?
I see a lot of people using various LLMs to generate stuff to say, and it’s all the same, and it’s all wrong.
How many times can you post the same “10 things to avoid in SQL queries” list that starts with “Avoid SELECT *” and expect to be taken seriously?
Worse, there are people who post and re-post all manner of “SQL tips” that are blatantly incorrect, missing important details, or offer advice that ranges from doesn’t-make-any-sense-whatsoever to downright-harmful.
If these were people who knew what they were talking about in the first place, they’d be ashamed and embarrassed to read what they’re posting.
But they aren’t people who know what they’re talking about, and so the badness proliferates.
Somehow or another, these posts get tons of traction and interaction. I don’t understand the amplification mechanisms, but I find the whole situation quite appalling.
For all the talk about various forms of misinformation, and how the general public needs to be protected from it, I don’t see anyone rushing to plug the onslaught of garbage that various LLMs produce.
Seriously. Talk to it about something you know quite well for a bit, and you’ll quickly see the problems with things it comes up with.
If you want to mess with LLMs for language-oriented tasks, fine. Treat it like having an executive assistant and double/triple check everything it comes up with.
If you’re using LLMs to come up with technical content, you need to stop immediately. You’re lying to people, and embarrassing yourself in the process.
We all know you didn’t write that, and anyone with a modicum of sense knows just how little you actually know.
I was recently linked to this podcast about the whole situation, and I found it quite spot-on:
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.