Date Debate
Searching dates is a common enough task. There are, of course, good and bad ways to do this.
Aaron Bertrand’s article, Bad habits to kick: mis-handling date / range queries, is a good place to start to learn about that subject.
This isn’t quite about the same thing, just about some behavior that I thought was interesting, and how it changes between cardinality estimator versions.
Bad Robot
If you’ve been query tuning for a while, you probably know about SARGability, and that wrapping columns in functions is generally a bad idea.
But just like there are slightly different rules for CAST and CONVERT with dates, the repercussions of the function also vary.
The examples I’m going to look at are for YEAR() and MONTH().
If you want a TL;DR, here you go.

If you wanna keep going, follow me!
USING
The takeaway here isn’t that doing either of these is okay. You should fully avoid wrapping columns in functions in general.
One of the main problems with issuing queries with non-SARGable predicates is that the people who most often do it are the people who rely on missing index requests to direct tuning efforts, and non-SARGable queries can prevent those requests from surfacing, or ask for an even more sub-optimal index than usual.
If you have a copy of the StackOverflow2013 database, you can replicate the results pretty easily on SQL Server 2017.
They may be slightly different depending on how the histogram is generated, but the overarching theme is the same.
Yarly
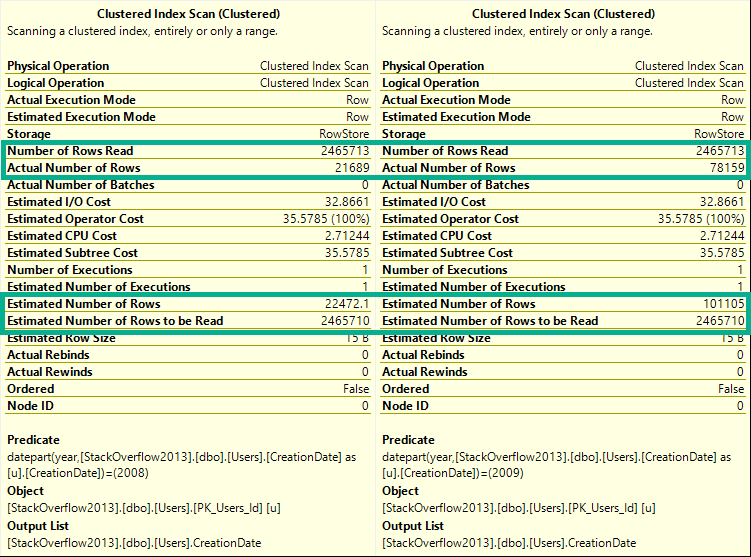
If you run these queries, and look at the estimated and actual rows in the Clustered Index scan tooltip, you’ll see they change for every query.
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2008;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2009;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2010;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2011;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2012;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2013;
GO
Here’s a sample from the 2008 and 2009 queries.
ED: I took a break from writing this and “went to brunch”.
Any logical inconsistencies will work themselves out eventually.
Cash Your Checks And Come Up
Alright, let’s try that again with by month.
If you hit yourself in the head with a hammer and forgot the TL;DR, here’s what happens:
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 1;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 2;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 3;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 4;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 5;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 6;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 7;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 8;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 9;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 10;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 11;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12;
If you run these, they’ll all have the same guess on the clustered index scan.
To keep things simple, let’s look at the first couple:
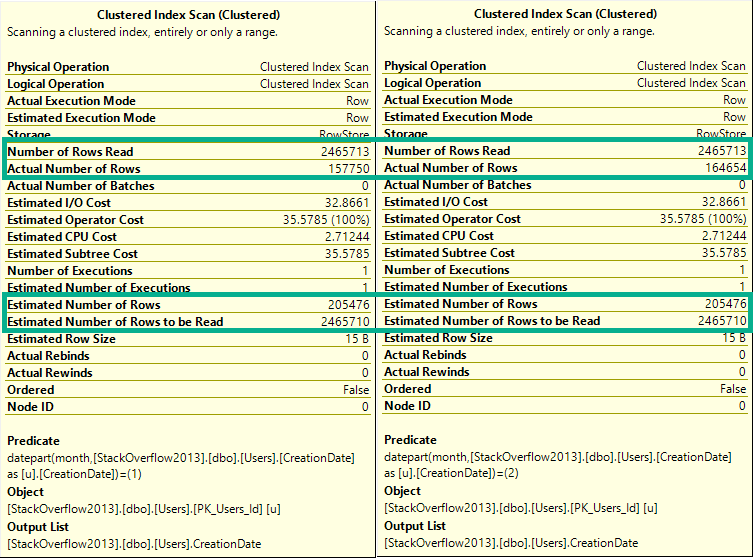
The difference here is that now every single row estimate will be 205,476.
Lesson learned: The optimizer can make a decent statistical guess at the year portion of a date, but not the month portion.
In a way, you can think of this like a LIKE query.
The optimizer can make a decent guess at ‘YEAR%’, but not at ‘%MONTH%’.
Actual Facts To Snack On And Chew
The same thing happens for both new and old cardinality estimators.
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2008
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2008
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
Wouldn’t Get Far
But if we combine predicates, something really different happens between Linda Cardellini estimators.
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
AND YEAR(u.CreationDate) = 2012
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
AND YEAR(u.CreationDate) = 2012
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
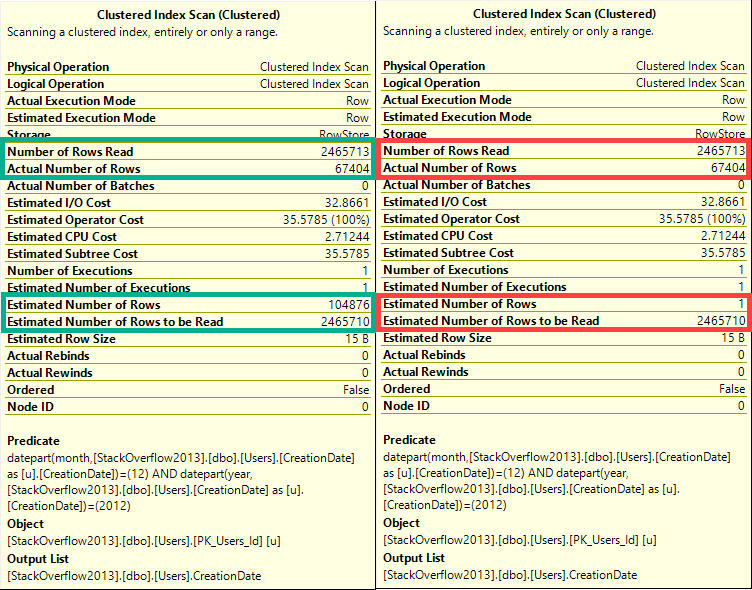
In this case, the old CE (on the right), makes a very bad guess of 1 row.
The new CE (on the left) makes a slightly better, but still not great guess.
Ended
Neither of these is a good way to query date or time data.
You can see in every tooltip that, behind the scenes, the queries used the DATEPART function, which means that also doesn’t help.
The point of this post is that someone may use a function to query the year portion of a date and assume that SQL Server does a good job on any other portion, which isn’t the case.
None of these queries are SARGable, and at no point is a missing index request raised on the CreationDate column, even though if you add one it gets used and reduces reads.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.