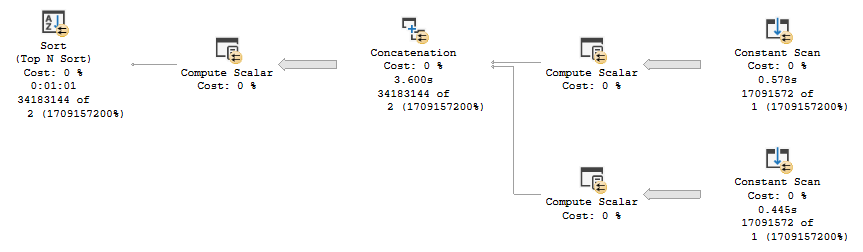
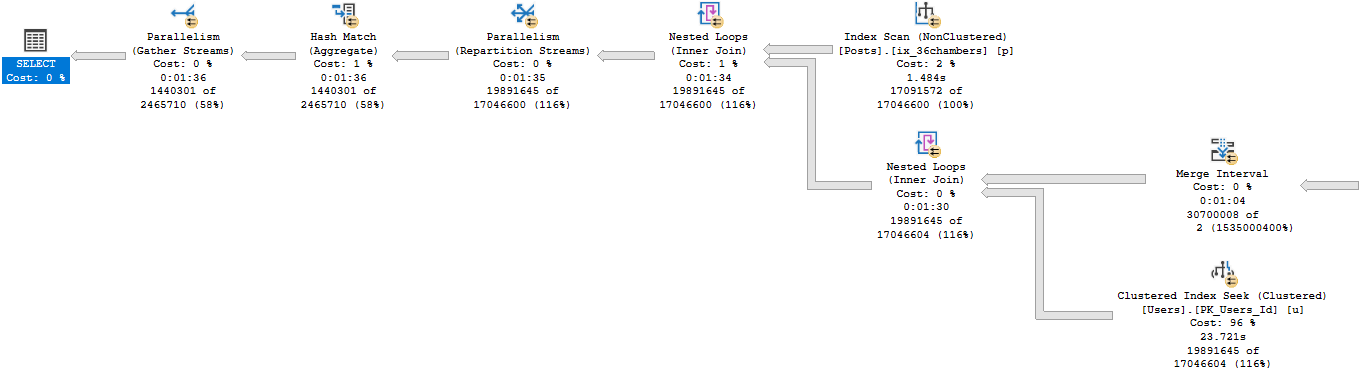
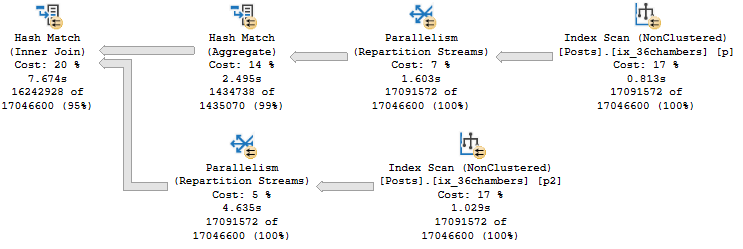
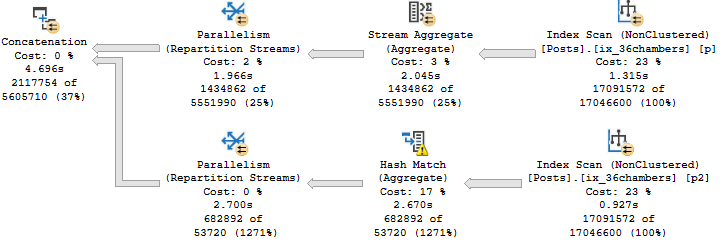
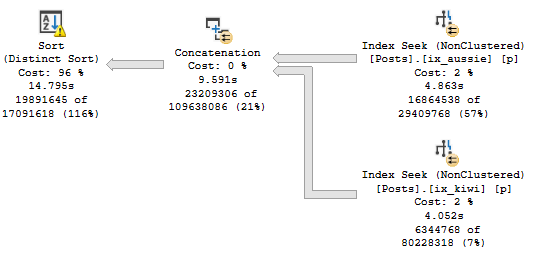
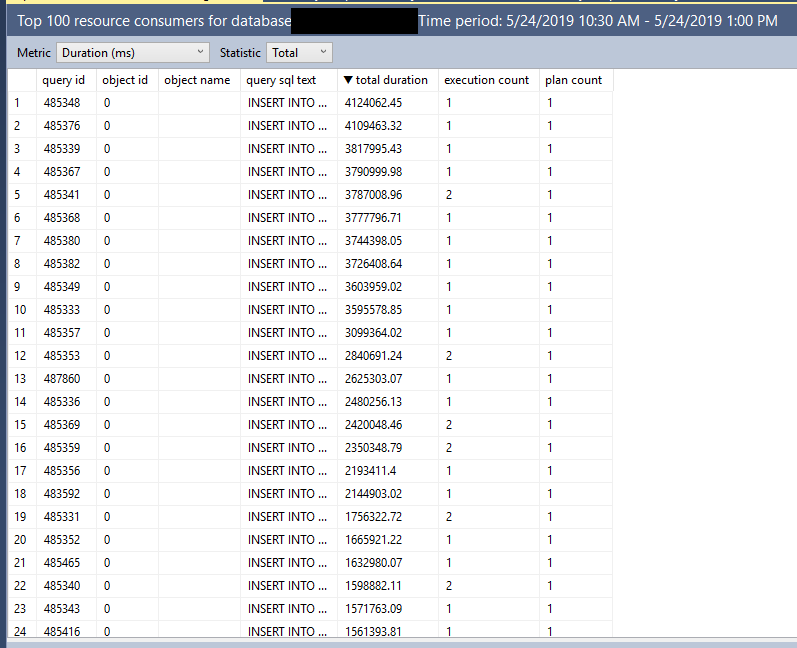
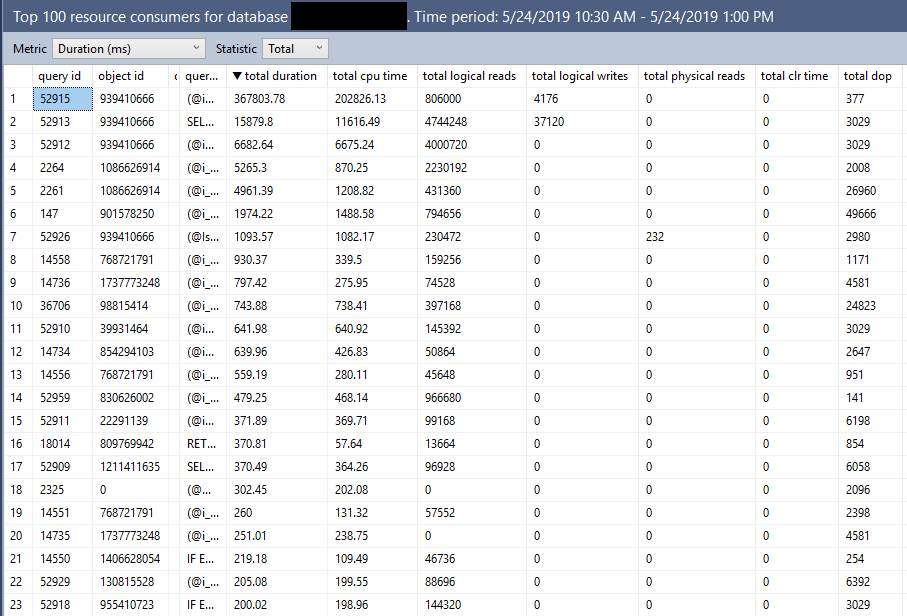
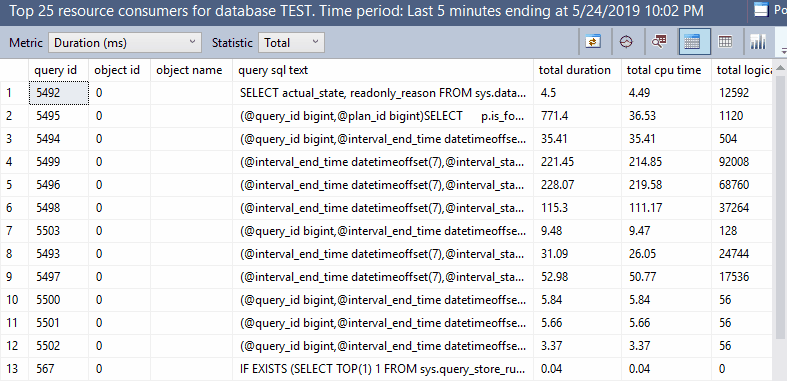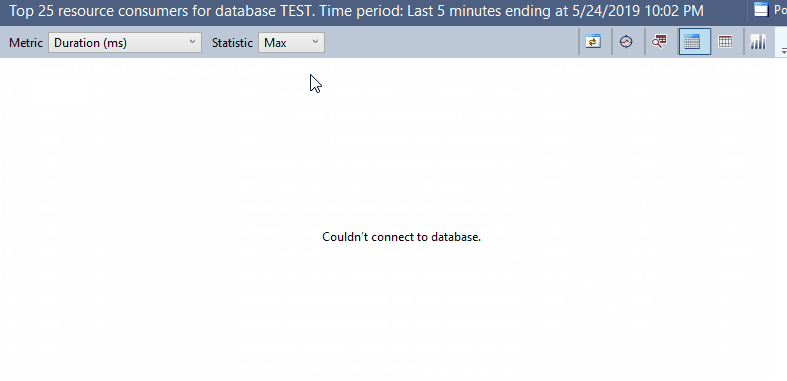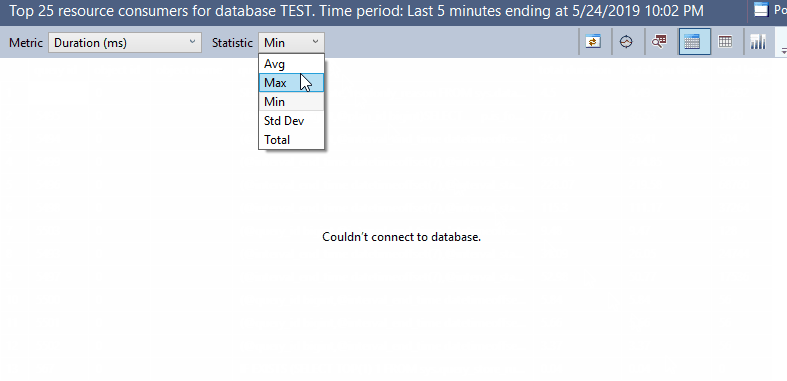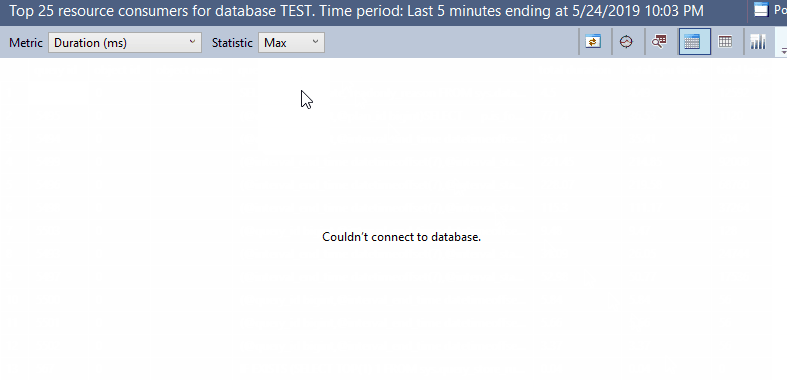
Knock Knock
There’s nothing technical in this post.
It’s just sort of a general accounting of what six months of independent consulting has looked like for me.
Some things I’ve learned, things I’m happy with, things I’m unhappy with. I dunno.
We’ll see where this goes as I’m writing it. Don’t count on it being terribly insightful.
There are countless people who are owed great amounts of gratitude for the advice, encouragement, referrals, and all the other Spackle needed to get things off the ground.
Words in a blog post are insufficient. I’m plotting my thank yous carefully.
Caliente
I’ve had 23 clients in 6 months, not counting work that Mike Walsh has outsourced to me (insert largest possible thank you here).
The projects have varied quite a bit in length and price, so don’t go trying to reverse engineer my income.
I’m not as comfortable as some other people in talking about that, though I’m entirely willing to tell you I made $300 in January.
The only thing I’ll say is that I made just about my base salary last year at the beginning of May.
I’m very happy with that, but the thing I want to share is this: lump slums are really misleading.
I learned this from Brent.
An equally large thank you should be here, too, for probably the best education one could ask for in how to run a consulting business.
Bill Factor 100
Whenever money comes in, I pull 30% out to pay taxes with.
I stick it in a savings account, so maybe it’ll earn whatever pittance interest rates are these days.
Just to use a round number: If I charge someone $1000, $300 leaves immediately.
When you’re setting prices on your time, factoring in that 30% is really important.
The other things you need to consider are, obviously, your expenses.
I have rent, I have to fully pay for my own insurance now, and I have the ever-present work-harder motivation that is a wife and two kids.
Plus the usual phone, internet, utilities, and other recurring expenses.
To put $1000 in perspective: if I charge someone $1000, I still owe my insurance company $800.
To put it further in perspective, I’d still owe my landlord $2000.
And I owe Uncle Sam™ that $300. Whew.
If you ever wonder why consultants seem expensive, it’s because we have to factor a lot of stuff in.
Every price tag has that stuff (plus the constant fear of a slow month) built in to it.
Happy Happy
So what am I happy with? I have a thing that’s mine. I can do whatever I want with it.
I’ve found it fun building my own “brand”, even if I’m not terribly good at building a brand.
I’m happy with the work I’ve been doing, too. With Brent, it was very much hands off analysis.
I’ve been getting back into actually tuning stuff.
And you know what? It’s rewarding to know that the advice you give people actually works.
It’s not all fun and games, but what is?
At least I choose what I say yes or no to, so I only have myself to blame.
I’ve gotten to travel a bit more, though the locales haven’t exactly been exotic.
Downers
Stuff I’m unhappy with is largely cosmetic.
I hate the way my website looks. It’s dark, and it doesn’t sell anything very well.
All of the choices I made at the very beginning were very much hair-on-fire, oh-crap-I-gotta-make-this-work-quick.
Believe it or not, layoffs don’t come with a lot of advance notice.
Anyway, I feel like it shows when I look at my website. And I just don’t have time to do anything about it right now.
I’m also not great at marketing.
I mean, I’m pretty good at saying funny things about what I’m doing, but I have no idea how to get it in front of more faces, or get more people to say “yes”.
That psychology escapes me.
I’ve read books. I’ve seen doctors. I’ve talked to people. I just don’t think I have that gene.
Time Management
The one thing I’m really beating myself up about is training.
Writing it from scratch is hard.
And long.
Long and hard.
Like a morning without drinking.
It’s coming along, but all the “keep the lights on” work seems to eat away at the time I want to spend building it.
I’M A BIT OF A PERFECTIONIST (ha ha ha)
No but really. I have a lot to write down.
I’m plotting stuff that can take you from beginner to wherever I’m at currently. Hopefully that line keeps moving.
Futuristic
Alright, yeah. This thing.
My hope is that I can focus on getting training written and produced, even if it’s slower than I’d like.
I realized it would be daft to work on a set of my own data analysis scripts, so I’ll be working on the First Responder Kit as time allows.
When I’m comfortable with the amount of money in the bank, I’ll probably get the website a facelift.
Maybe I’ll magically get good at marketing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.