Whistle Whistle
In yesterday’s post, we looked at four different ways to get the highest value per use with no helpful indexes.
Today, we’re going to look at how those same four plans change with an index.
This is what we’ll use:
CREATE INDEX ix_whatever
ON dbo.Posts(OwnerUserId, Score DESC);
Query #1
This is our MAX query! It does really well with the index.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT MAX(Score) AS Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
) AS ca
WHERE u.Reputation >= 100000
ORDER BY u.Id;
It’s down to just half a second.
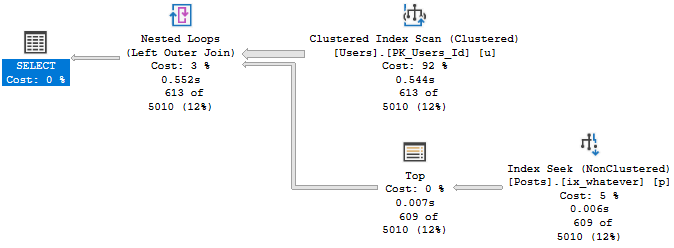
Query #2
This is our TOP 1 query with an ORDER BY.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1) p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
ORDER BY p.Score DESC
) AS ca
WHERE u.Reputation >= 100000
ORDER BY u.Id;
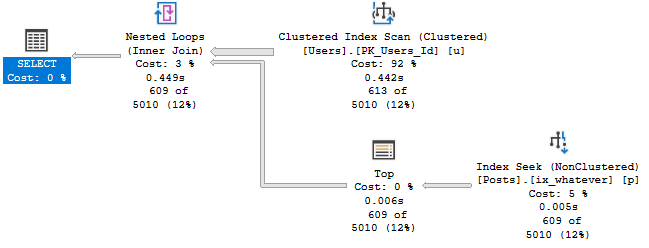
This finished about 100ms faster than MAX in this run, but it gets the same plan.
Who knows, maybe Windows Update ran during the first query.
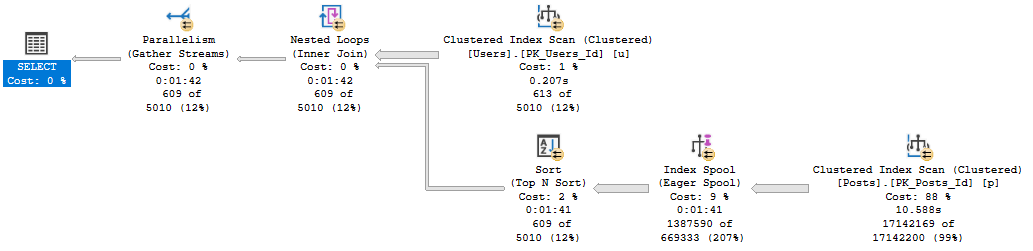
Query #3
This is our first attempt at row number, and… it’s not so hot.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT p.Score,
ROW_NUMBER() OVER (ORDER BY p.Score DESC) AS n
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
) AS ca
WHERE u.Reputation >= 100000
AND ca.n = 1
ORDER BY u.Id;
While the other plans were able to finish quickly without going parallel, this one does go parallel, and is still about 200ms slower.
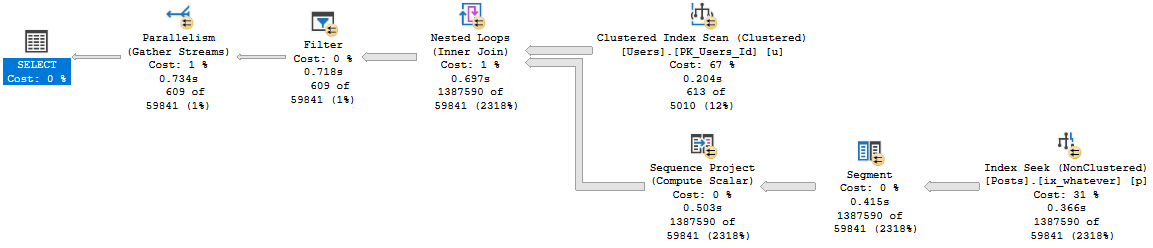
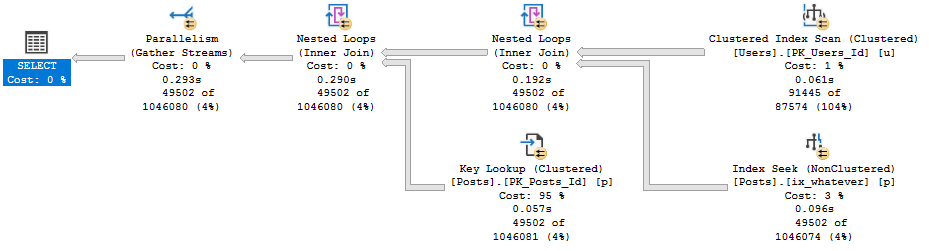
Query #4
Is our complicated cross apply. The plan is simple, but drags on for almost 13 seconds now.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT *
FROM
(
SELECT p.OwnerUserId,
p.Score,
ROW_NUMBER() OVER (PARTITION BY p.OwnerUserId
ORDER BY p.Score DESC) AS n
FROM dbo.Posts AS p
) AS p
WHERE p.OwnerUserId = u.Id
AND p.n = 1
) AS ca
WHERE u.Reputation >= 100000
ORDER BY u.Id;
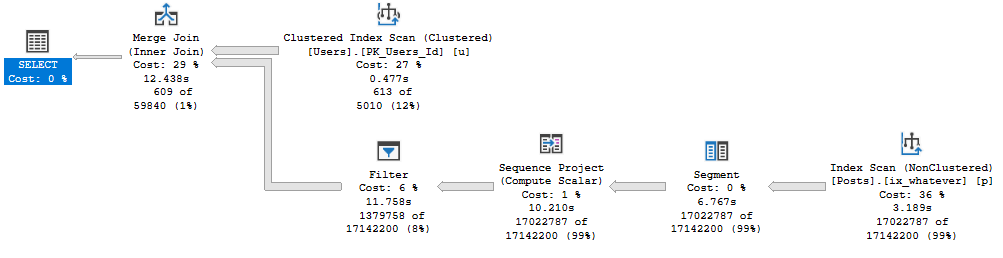
Slip On
In this round, row number had a tougher time than other ways to express the logic.
It just goes to show you, not every query is created equal in the eyes of the optimizer.
Now, initially I was going to do a post with the index columns reversed to (Score DESC, OwnerUserId), but it was all bad.
Instead, I’m going to do future me a favor and look at how things change in SQL Server 2019.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.