Roundhouse
Rounding out a few posts about SQL Server’s choice of one or more indexes depending on the cardinality estimates of literal values.
Today we’re going to look at how indexes can contribute to parameter sniffing issues.
It’s Friday and I try to save the real uplifting stuff for these posts.
Procedural
Here’s our stored procedure! A real beaut, as they say.
CREATE OR ALTER PROCEDURE dbo.lemons(@Score INT)
AS
BEGIN
SELECT TOP (1000)
p.Id,
p.AcceptedAnswerId,
p.AnswerCount,
p.CommentCount,
p.CreationDate,
p.LastActivityDate,
DATEDIFF( DAY,
p.CreationDate,
p.LastActivityDate
) AS LastActivityDays,
p.OwnerUserId,
p.Score,
u.DisplayName,
u.Reputation
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON u.Id = p.OwnerUserId
WHERE p.PostTypeId = 1
AND p.Score > @Score
ORDER BY u.Reputation DESC;
END
GO
Here are the indexes we currently have.
CREATE INDEX smooth
ON dbo.Posts(Score, OwnerUserId);
CREATE INDEX chunky
ON dbo.Posts(OwnerUserId, Score)
INCLUDE(AcceptedAnswerId, AnswerCount, CommentCount, CreationDate, LastActivityDate);
Looking at these, it’s pretty easy to imagine scenarios where one or the other might be chosen.
Heck, even a dullard like myself could figure it out.
Rare Score
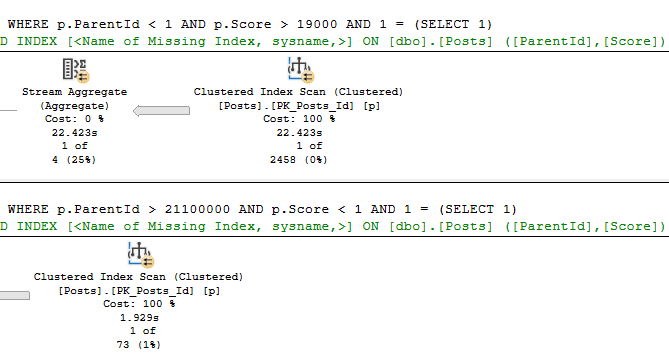
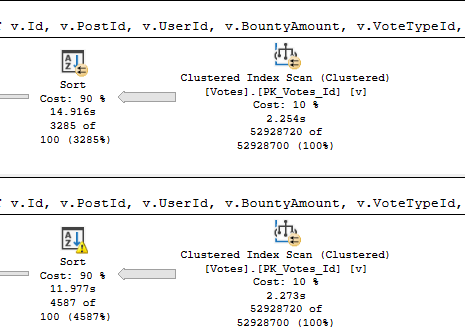
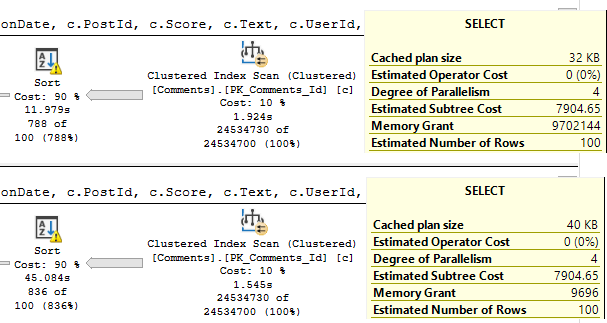
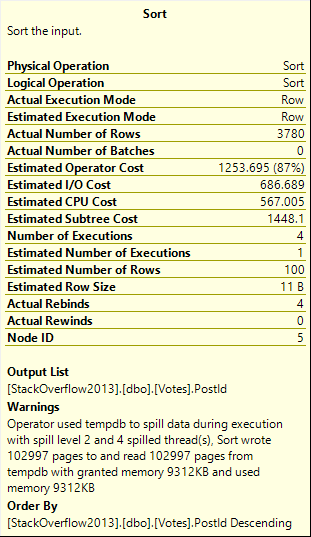
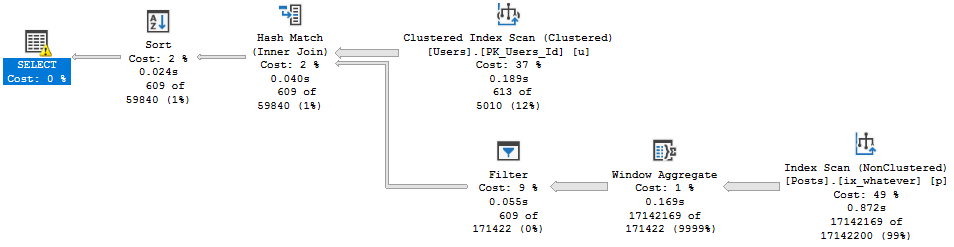
Running the procedure for an uncommon score, we get a tidy little loopy little plan.
EXEC dbo.lemons @Score = 385;

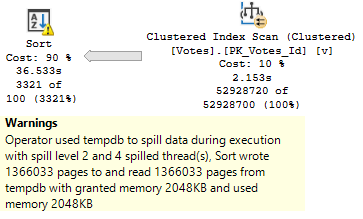
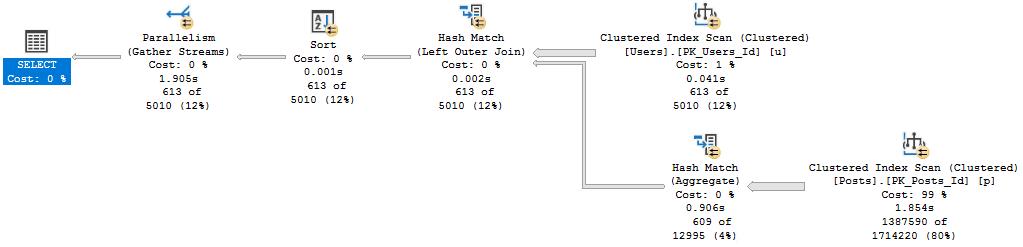
Of course, that plan applied to a less common score results in tomfoolery of the highest order.
Lowest order?
I’m not sure.

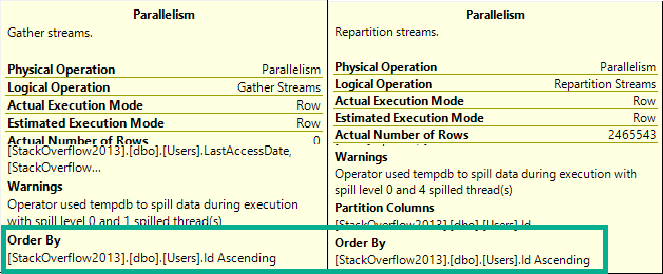
In both of these queries, we used our “smooth” index.
Who created that thing? We don’t know. It’s been there since the 90s.
Sloane Square
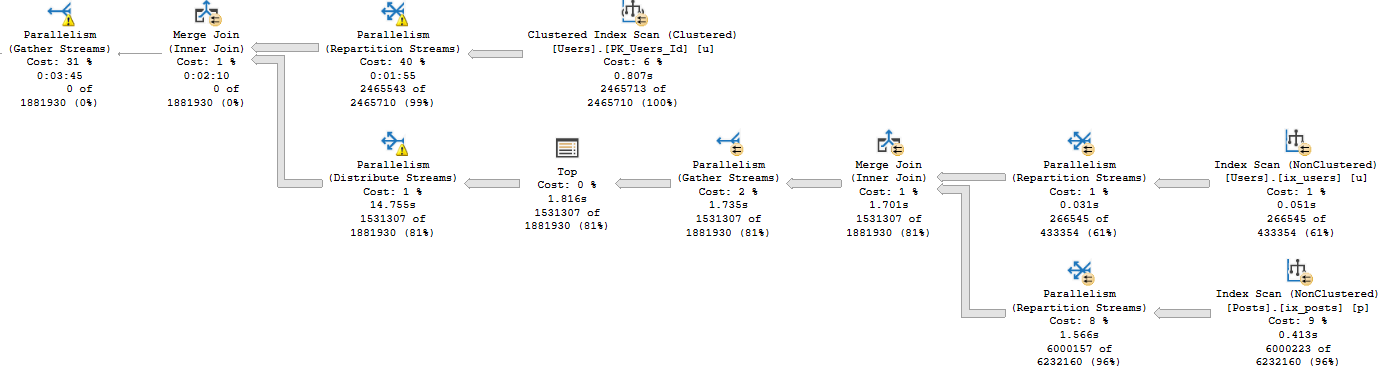
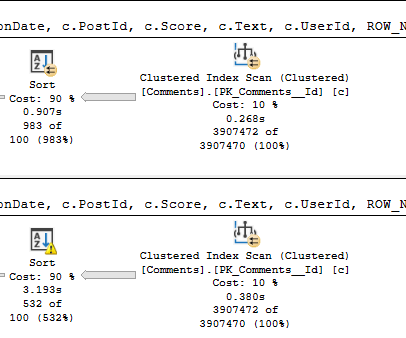
If we recompile, and start with 0 first, we get a uh…

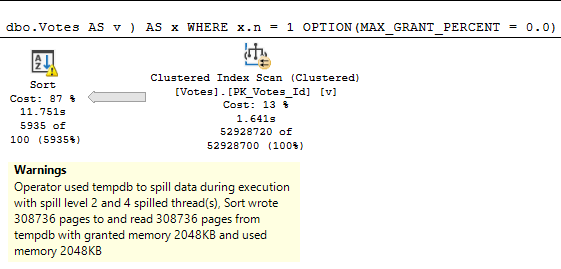
We get an equally little loopy little plan.
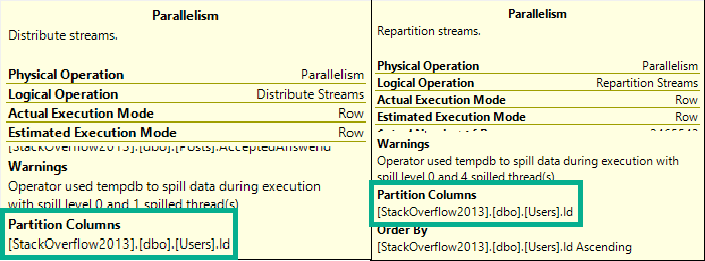
The difference? Join order, and now we use our chunky index.
Running our procedure for the uncommon value…
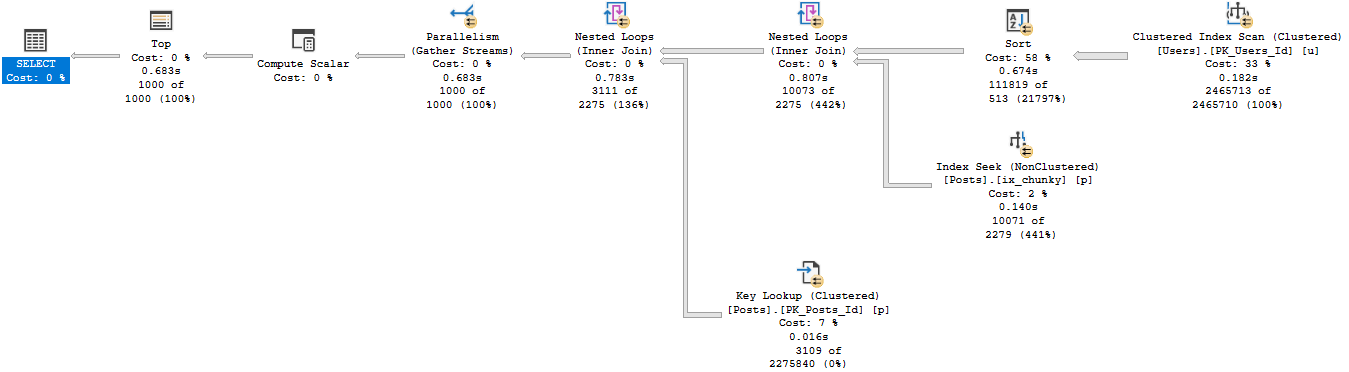
Well, that doesn’t turn out so bad either.
Pound Sand
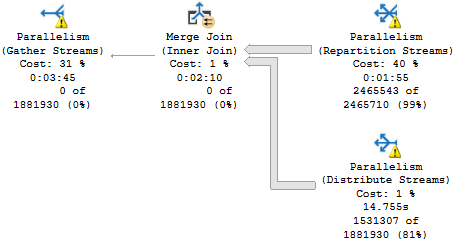
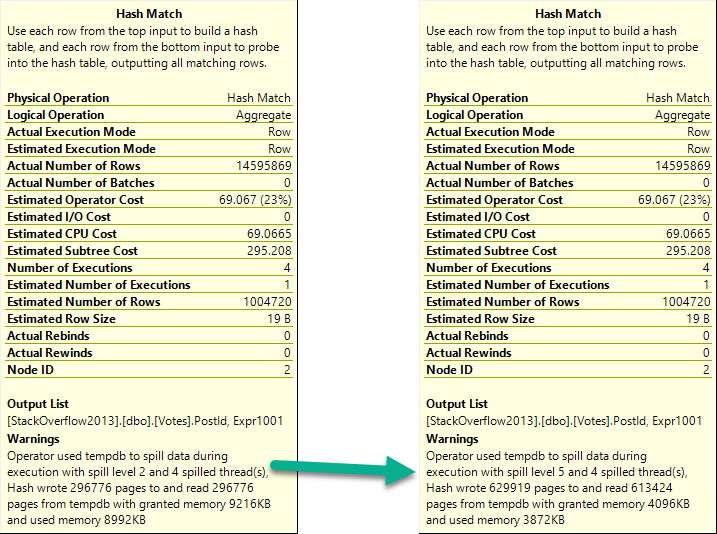
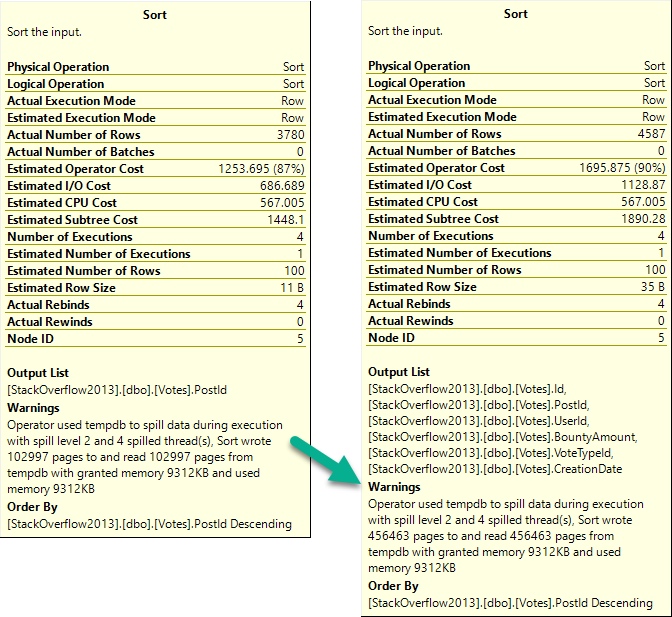
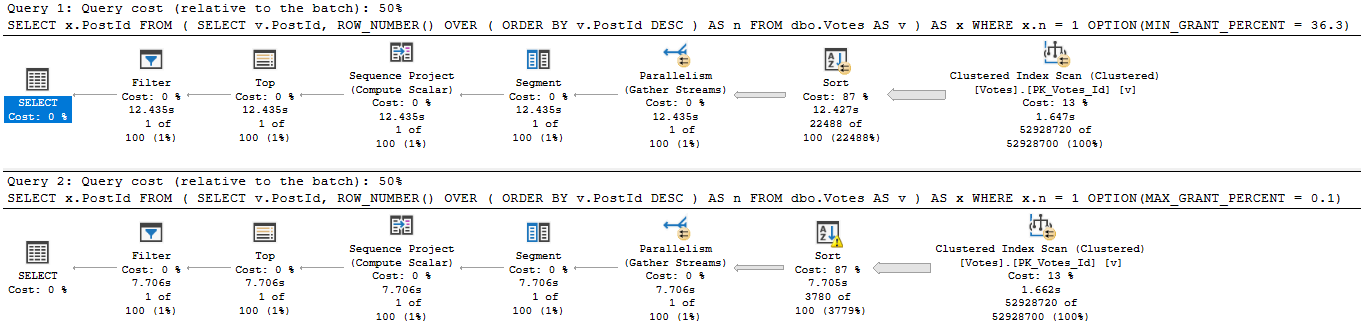
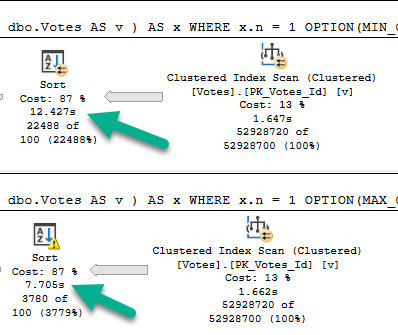
When you’re troubleshooting parameter sniffing, the plans might not be totally different.
Sometimes a subtle change of index usage can really throw gas on things.
It’s also a good example of how Key Lookups aren’t always a huge problem.
Both plans had them, just in different places.
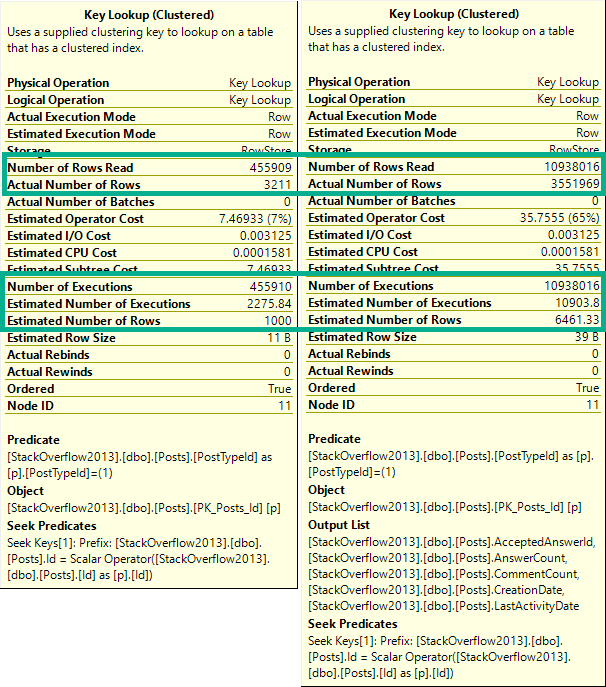
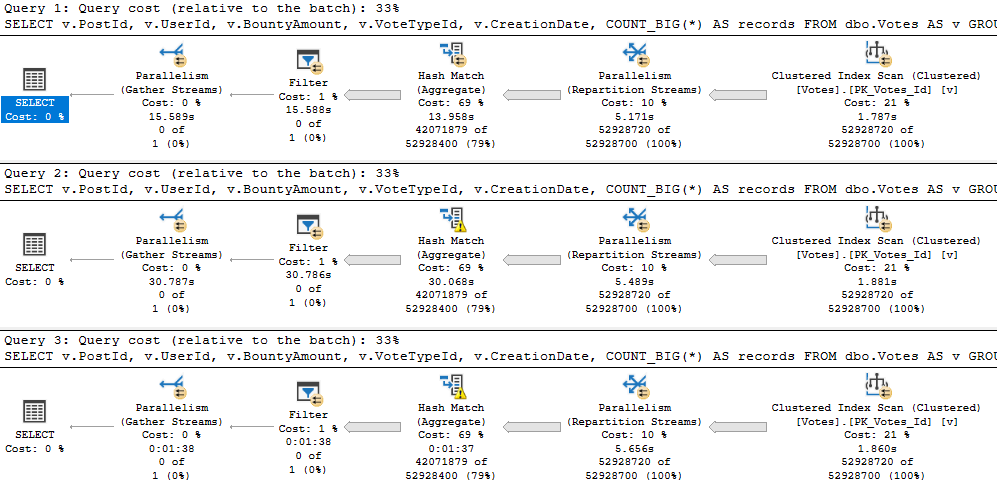
It would be hard to figure out if one is good or bad in estimated or cached plans.
Especially because they only tell you compile time parameters, and not runtime parameters.
Neither one is a good time parameter.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.