I Got Five On It
I wish I had a dollar for every wrong thing I’ve heard about CTEs in my life. I’d buy a really nice cigar and light it with fire made by the gods themselves.
Or, you know, something like that.
One common thing is around some persistence of the queries contained inside of them in some form, whether in memory or in tempdb or something else.
I honestly don’t know where these things begin. They’re not even close to reality.
Getting It Right
Let’s take this query as an example:
SELECT u.Id,
u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation * 2 = 22;
If you’ve been tuning queries for longer than a day, you can probably spot the issue here.
Applying expressions to columns in the where clause (or joins) messes up some things. Unfortunately, you can also run into the exact same issues doing this:
WITH cte AS
(
SELECT u.Id,
u.Reputation,
(u.Reputation * 2) AS ReputationDoubler
FROM dbo.Users AS u
)
SELECT c.Id,
c.Reputation
FROM cte AS c
WHERE c.ReputationDoubler = 22;
To be explicit: both of these queries have the same problem.
Erik D Is President
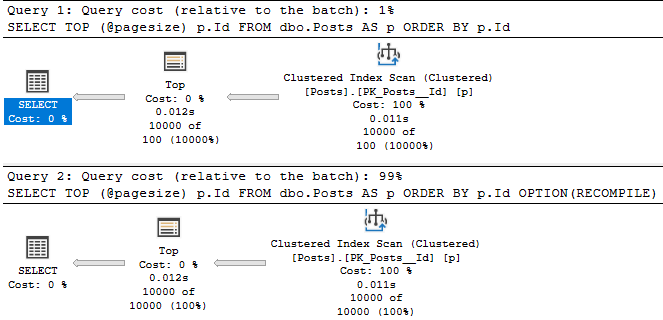
Starting with this index:
CREATE INDEX toodles ON dbo.Users(Reputation);
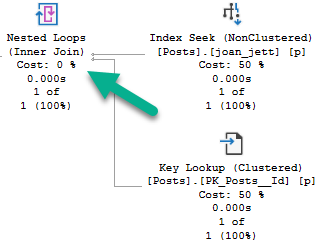
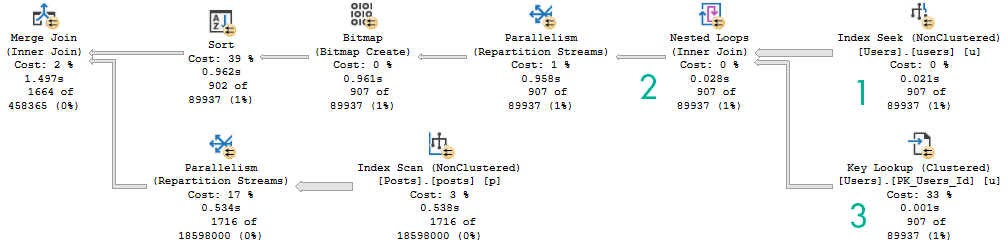
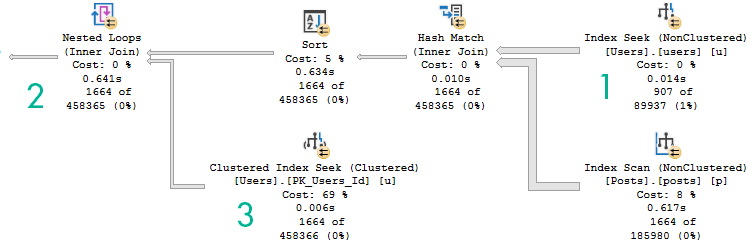
Both queries have the same execution plan characteristics:
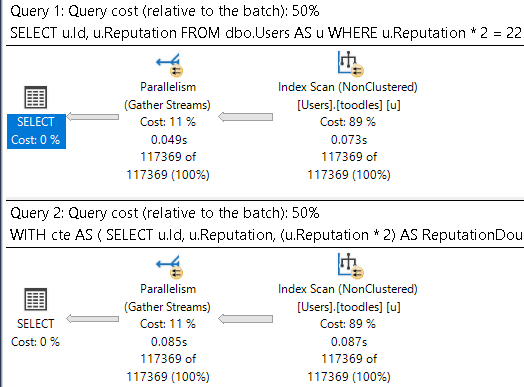
I understand why you think a mature database product might be able to deal with this better:
- Locate values in the index with a value of 11
- Divide the literal value by 2 instead
But SQL Server doesn’t have anything like that, and neither do CTEs. Both indexes get scanned in entirety to retrieve qualifying rows, with the unseekable expression applied as a residual predicate:
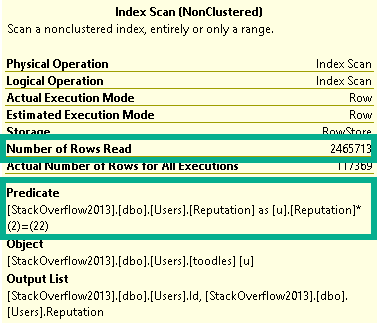
Gopherville
To be clear, and hopefully to persuade you to write clear predicates, this is the end result that we’re after:
SELECT u.Id,
u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation = 11;
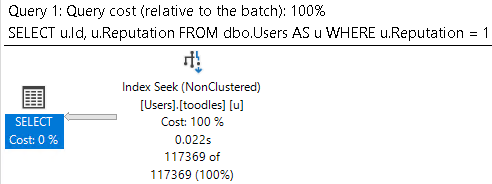
While this is of course intuitive when writing simple queries, the point of this post is to show that expressions in CTEs don’t offer any advantage.
This goes for any flavor of derivation, too. Whether it’s wrapping columns in built in or user defined functions, combining columns, combining columns with values, etc.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.