Hash spills are nothing like sort spills, in that even with (very fast) disks, there’s no immediate benefit to breaking the hash down into pieces via a spill.
In fact, there are many downsides, especially when memory is severely constrained.
The query that I’m using looks about like this:
SELECT v.PostId,
COUNT_BIG(*) AS records
FROM dbo.Votes AS v
GROUP BY v.PostId
HAVING COUNT_BIG(*) > 2147483647
The way this is written, we’re forced to count everything, and then only filter out rows at the end.
The idea is to spend no time waiting on rows to be displayed in SSMS.
Just One Int
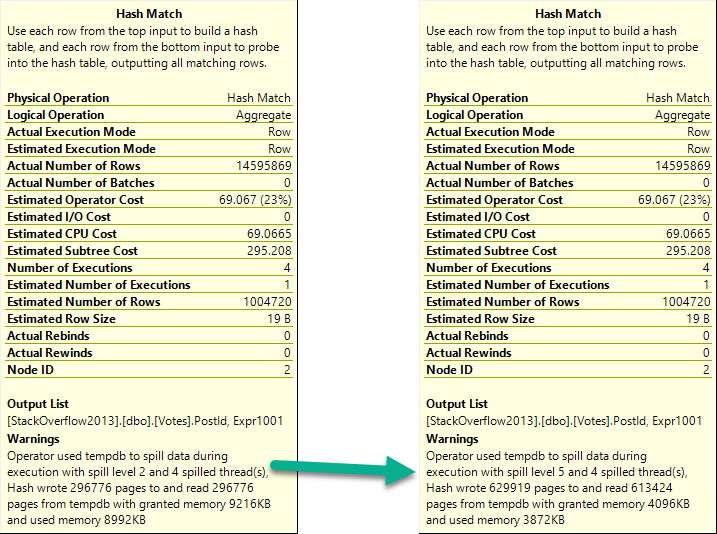
To get an idea what performance looks like, I’m starting with one integer column.
With no spills and a 776 MB memory grant, this runs for about 15 seconds.
Hello
If we drop the grant down to about 10 MB, we spill a bunch, but runtime doesn’t go up too much.
Hurts A Little
And if we drop it down to 4.5 MB, things go absolutely, terribly, pear shaped.
Hurts A Lot
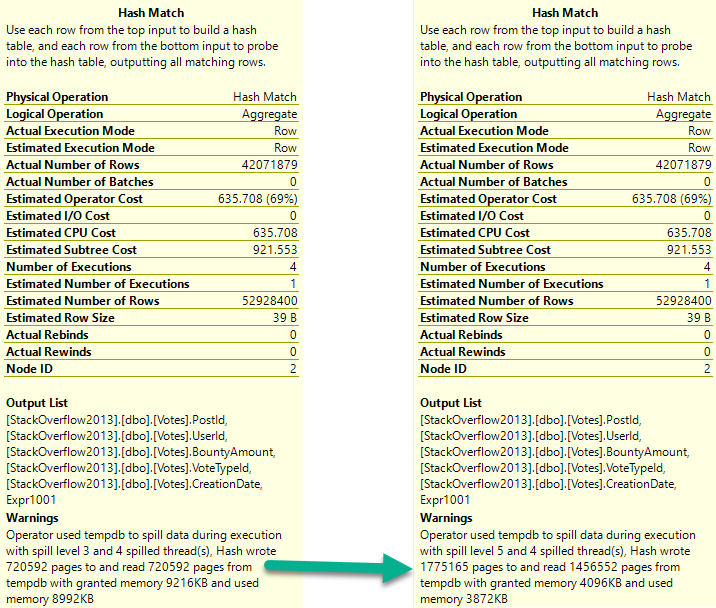
The difference in both the number of pages spilled and the spill level are pretty dramatic.
TWO THOUSAND!
Expansive
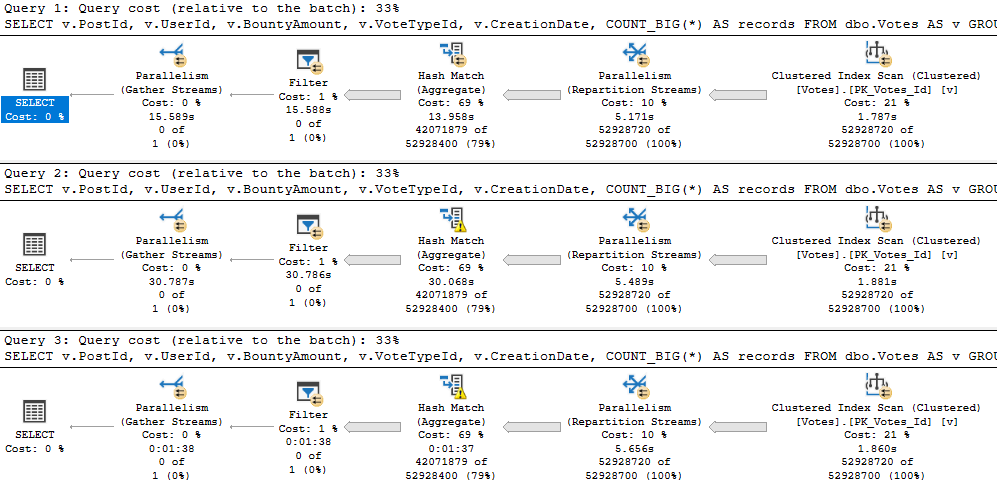
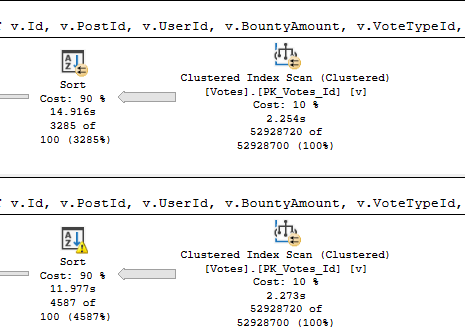
If we expand the query a bit to look like this, memory starts to matter more:
SELECT v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Votes AS v
GROUP BY v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
HAVING COUNT_BIG(*) > 2147483647
Extra Extra
With more columns, the first spill escalates to a higher level faster, and the second spill absolutely wipes out.
It runs for almost 2 minutes.
EATS IT
As a side note, I really hate how long that Repartition Streams operator runs for.
Predictably
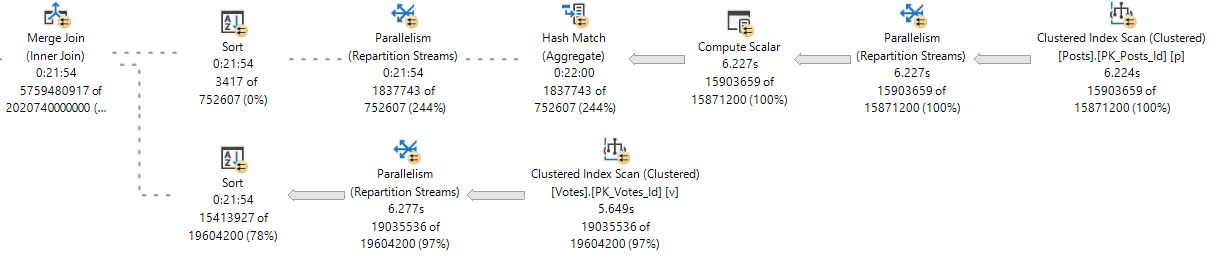
When we get the Comments table involved, that string column beats us right up.
Love On An Escalator
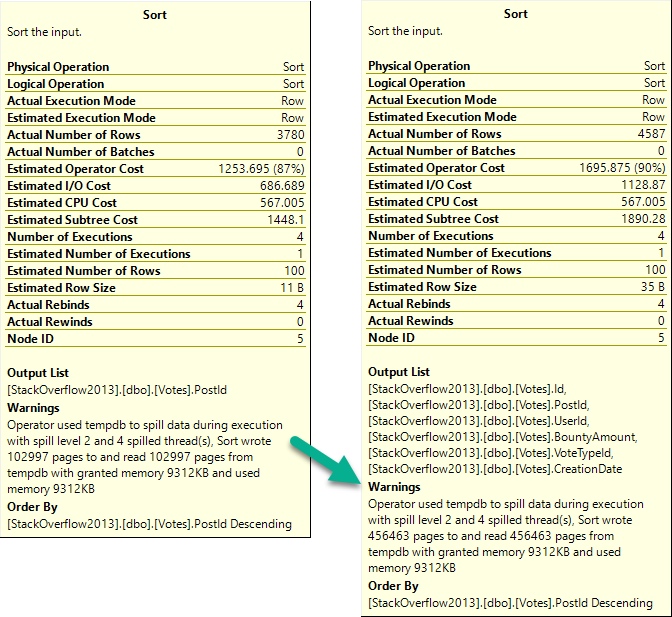
The first query asks for the largest possible grant on my laptop: 9.7GB. The second query gets 10MB.
The spill is godawful.
When we reduce the memory grant to 4.5MB, the spill runs another 1:20, for a total of 3:31.
Crud
Those spills are the root cause of why these queries run longer than any we’ve seen to date in this series.
Something quite funny happens when Hashes of any variety spill “too much” — which you can read about in more detail here.
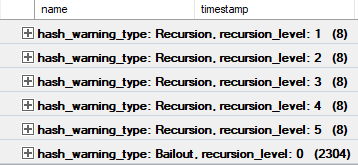
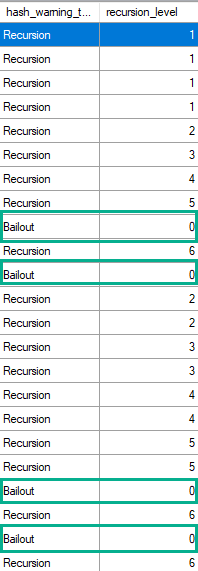
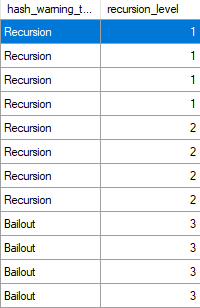
There’s an Extended Event called “hash warning” that we can use to track recursion and bailout.
Here’s the final output aggregated:
[outdated political joke]What happens when a Hash Aggregate bails out?
In Which I Belabor The Point Anyway, Despite Saying…
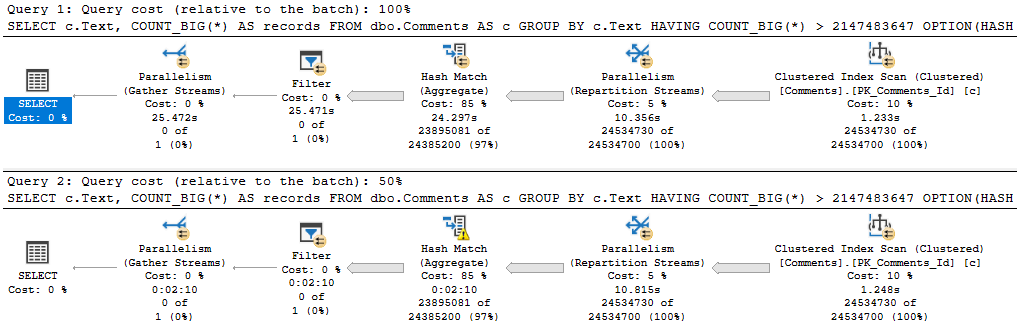
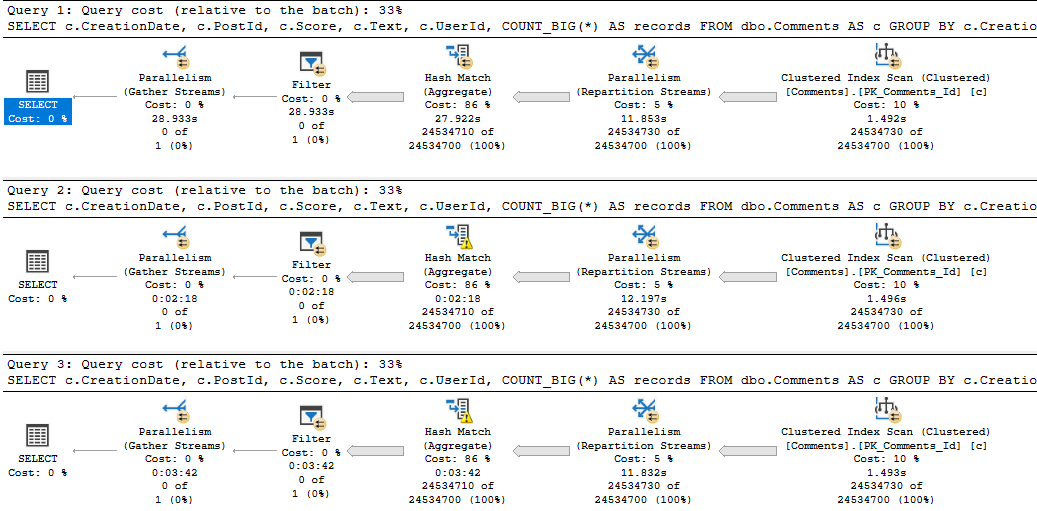
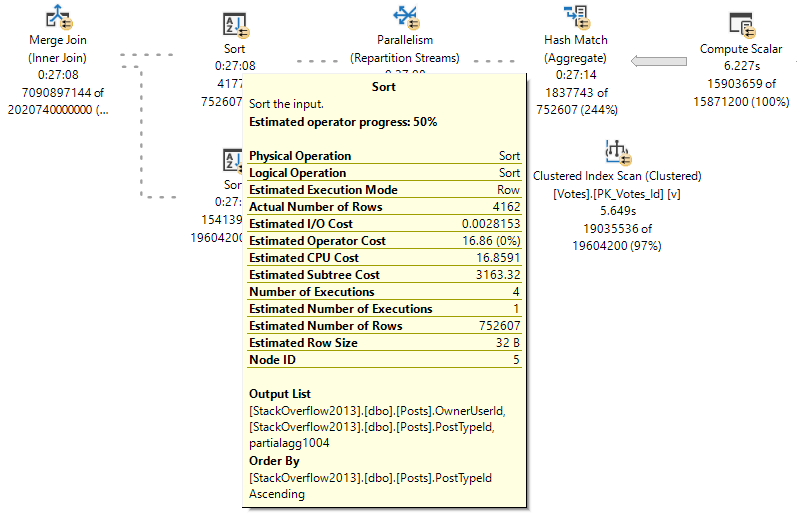
Not to belabor the point too much, but if we select and group all the columns in the Comments table, things get a bit worse.
Not fond
Three minutes of spills. What a time to be alive.
But, yeah, the bulk of the trouble here is caused by the string column.
Adding in some numbers and a date on top doesn’t have a profound effect.
Taking Up
While Sort Spills certainly dragged query performance down a bit when memory was severely limited, Hash Spills were far more detrimental.
If I had to choose between which one to investigate first, it’d be Hash spills.
But again, small spills are often not worth the effort, and in some cases, you may always see spills.
If your server is totally under-provisioned from a memory perspective, or if there are multiple concurrent memory consuming operations (i.e. they can’t share intra-query memory), it may not be possible for a large enough grant to be give to satisfy all of them.
This is part of why writing very large queries can be perilous, and it’s usually worth splitting them up.
In tomorrow’s post, we’ll look at hash joins.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In yesterday’s post, we looked at a funny situation where a query that spilled was about 5 seconds faster than one that didn’t.
Here’s what the query looked like:
SELECT x.PostId
FROM (
SELECT v.PostId,
ROW_NUMBER() OVER ( ORDER BY v.PostId DESC ) AS n
FROM dbo.Votes AS v
) AS x
WHERE x.n = 1;
Now, I can add more columns in, and the timing will hold up:
SELECT x.Id,
x.PostId,
x.UserId,
x.BountyAmount,
x.VoteTypeId,
x.CreationDate
FROM (
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate,
ROW_NUMBER() OVER ( ORDER BY v.PostId DESC ) AS n
FROM dbo.Votes AS v
) AS x
WHERE x.n = 1;
Gas Pedal
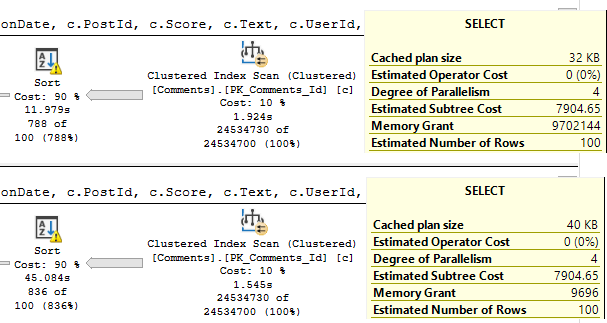
They both got slower, the non-spill plan by about 2.5s, and the spill plan by about 4.3s.
But the spill plan is still 3s faster. With fewer columns it was 5s faster, but hey.
No one said this was easy.
Fully comparing things from yesterday, when memory is capped at 0.0, the query takes much longer now, with more columns:
Killing Time
To compare the “fast” spills, here’s yesterday and today’s warnings.
More Pages, More Problems
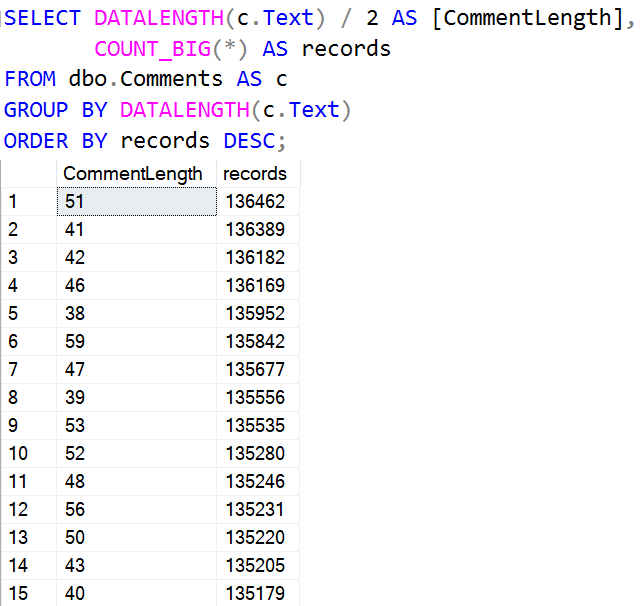
With one integer column, we spilled 100k pages.
With five integer columns and one datetime column, we spill 450k pages.
That’s a non-trivial amount. That’s like every column adding 75k pages to the spill.
If you’re really worried about spills: STOP SELECTING SO MANY COLUMNS.
For The Worst
I promised to show you things going quite downhill, and for the spill query to no longer be faster.
To do that, we need a different table.
I’m going to use the Comments table, because it has a column called Text in it, which is an NVARCHAR(700).
Very few comments are 700 characters long. The majority are < 120 or so.
5-7-9
This query looks about like so:
SELECT x.Id,
x.CreationDate,
x.PostId,
x.Score,
x.Text,
x.UserId
FROM (
SELECT c.Id,
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId,
ROW_NUMBER()
OVER ( ORDER BY c.PostId DESC ) AS n
FROM dbo.Comments AS c
) AS x
WHERE x.n = 1
And the results are… icky.
Gigs To Spare?
The top query asks for 9.7GB of RAM. That’s as much as my laptop can give out.
It still spills. Nearly 10GB of memory grant, and it still spills.
If you care about spills: STOP OVERSIZING STRING COLUMNS:
Billy Budd
Apparently only spilling 1mm pages is a lot faster than spilling 2.5mm pages.
But still much slower than not spilling string columns.
Who knew?
Matters of Whale
I was using the Stack Overflow 2013 database for that, which is fairly big relative to the 64GB of RAM my laptop has.
If I go back to using the 2010 version, we can get a better comparison, because the first query won’t spill anymore.
It’s like what all those query tuners keep telling you.
Some points to keep in mind here:
I’m testing with (very fast) local storage
I don’t have tempdb contention
But still, it seems like spilling out non-string columns is significantly less painful than spilling out string columns.
Ahem.
“Seems.”
I’ll reiterate two points:
Stop selecting so many columns
Stop oversizing string columns
In the next two posts, we’ll look at hash match and hash join spills under similar circumstances.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Every post this week is going to be about spills. No crazy in-depth, technical, debugger type stuff.
Just some general observations about when they seem to matter more for performance, and when you might be chasing nothing by fixing them.
The queries I use are sometimes a bit silly looking, but the outcomes are ones I see.
Sometimes I correct them and it’s a good thing. Other times I correct them and nothing changes.
Anyway, all these posts started because of the first demo, which I intended to be a quick post.
Oh well.
Intervention
Spills are a good thing to make note of when you’re tuning a query.
They often show up as a symptom of a bigger problem:
Parameter sniffing
Bad cardinality estimates
My goal is generally to fix the larger symptom than to hem and haw over the spill.
It’s also important to keep spills in perspective.
Some are small and inconsequential
Some are going to happen no matter what
And some spills… Some spills…
Can’t Hammer This
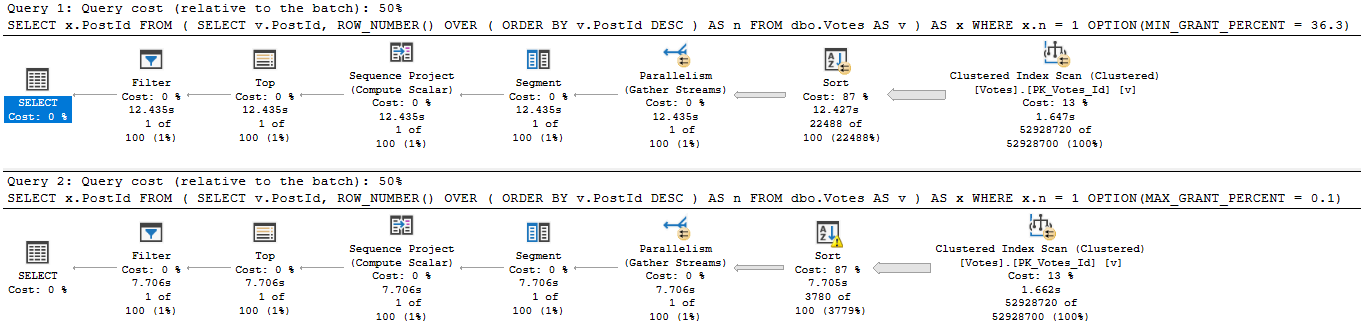
Pay close attention to these two query plans.
Completely unfounded
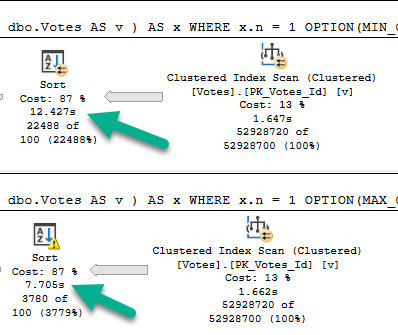
Not sure where to look? Here’s a close up.
Grounded
See that, there?
Yeah.
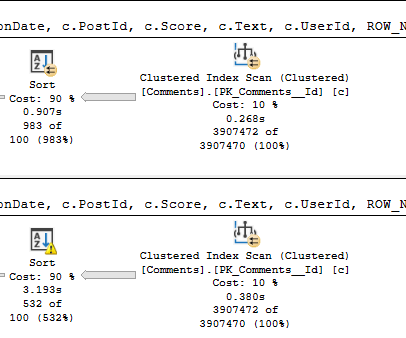
That’s a Sort with a Spill running about 5 seconds faster than a Sort without a Spill.
Wild stuff, huh? Here’s what it looks like.
Still got it.
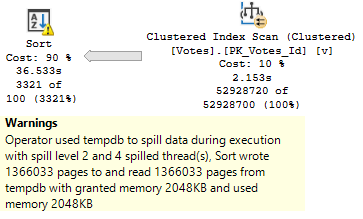
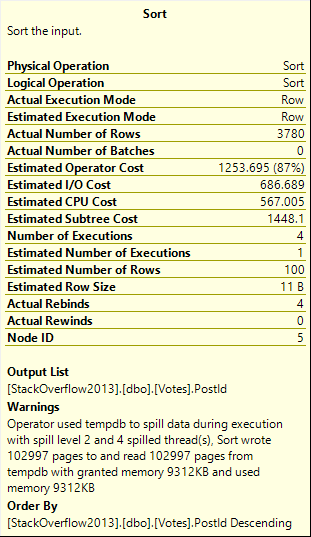
Not inconsequential. >100k 8kb pages.
Spill level 2, too. Four threads.
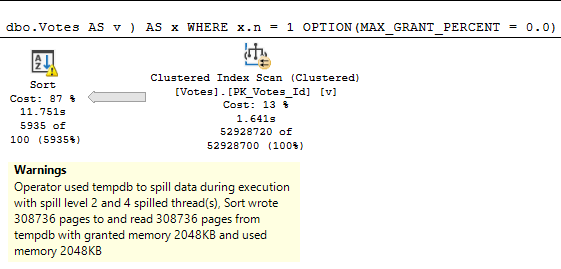
A note from future Erik: if I run this with the grant capped at 0.0 rather than 0.1, the spill plan takes 12 seconds, just like the non-spill plan.
There are limits to how efficiently a spill can be handled when memory is capped at a level that increases the number of pages spilled without increasing the spill level.
Z to the Ero
But it’s still funny that the spill and non-spill plans take about the same time.
Why Is This Faster?
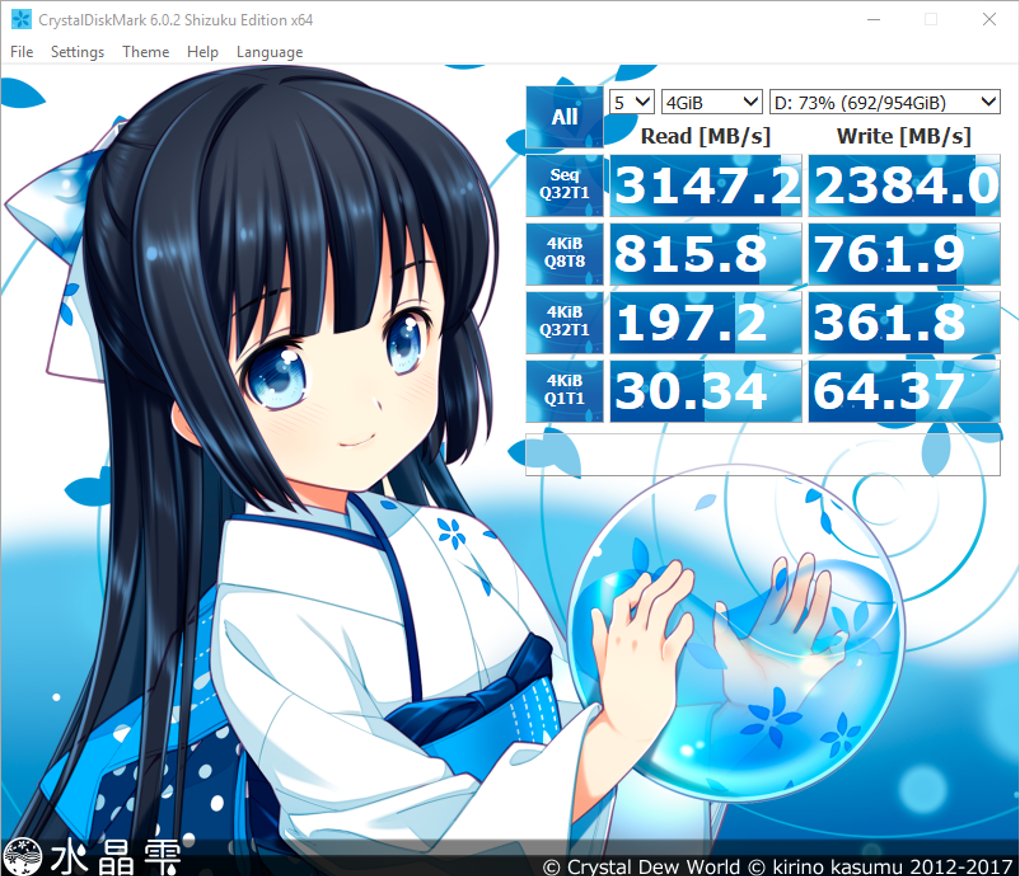
Well, the first thing we have to talk about is storage, because that’s where I spilled to.
My Lenovo P52 has some seriously fast SSDs in it. Here’s what they give me, via Crystal Disk Mark:
Girlfriend In A Cartoon
If you’re on good local storage, you might see those speeds.
If you’re on a SAN, I don’t care how much anyone squawks about how fast it is: you’re not gonna see that.
(But seriously, if you do get those speeds on a SAN, tell me about your setup.)
Multiple merge passes can be used to work around this. The general idea is to progressively merge small chunks into larger ones, until we can efficiently produce the final sorted output stream. In the example, this might mean merging 40 of the 800 first-pass sorted sets at a time, resulting in 20 larger chunks, which can then be merged again to form the output. With a total of two extra passes over the data, this would be a Level 2 spill, and so on. Luckily, a linear increase in spill level enables an exponential increase in sort size, so deep sort spill levels are rarely necessary.
Next, Paul White showing an Adam Machanic demo:
Well, okay, I’ll paraphrase here. It’s faster to sort a bunch of small things than one big thing.
If you watch the demo, that’s what happens with using the cross apply technique.
And that’s what’s happening here, too, it looks like.
On With It
The spills to (very fast) disk work in my favor here, because we’re sorting smaller data sets, then reading from (very fast) disk more small data sets, and sorting/merging those together for a final finished product.
Of course, this has limits, and is likely unrealistic in many tuning scenarios. I probably should have lead with that, huh?
But hey, if you ever fix a Sort Spill have have a query slow down, now you know why.
In tomorrow’s post, you’ll watch my luck run out (very fast) with different data.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There’s a wonderful explanation from Paul White about spill levels here. At the risk of offending the copyright godses, I’m going to quote it here.
Consider the task of sorting 4000MB of data, when we only have 500MB of memory available. Obviously, we cannot sort the whole set in memory at once, but we can break the task down:
We first read 500MB of data, sort that set in memory, then write the result to disk. Performing this a total of 8 times consumes the entire 4000MB input, resulting in 8 sets of sorted data 500MB in size. The second step is to perform an 8-way merge of the sorted data sets. Note that a merge is required, not a simple concatenation of the sets since the data is only guaranteed to be sorted as required within a particular 500MB set at the intermediate stage.
Alright, interesting! That’d make me think that the number of pages involved in the spill would increase the spill level. In real life, I saw spill level 11 once. I wish I had that plan saved.
Rowed To Nowhere
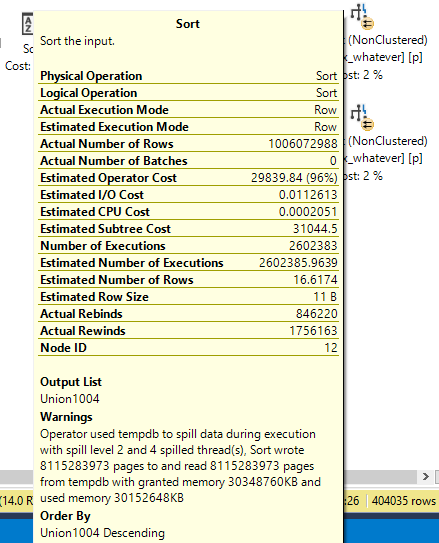
Here’s a pretty big spill. But it’s only at level two.
Insert commas.
That’s 8,115,283,973 rows.
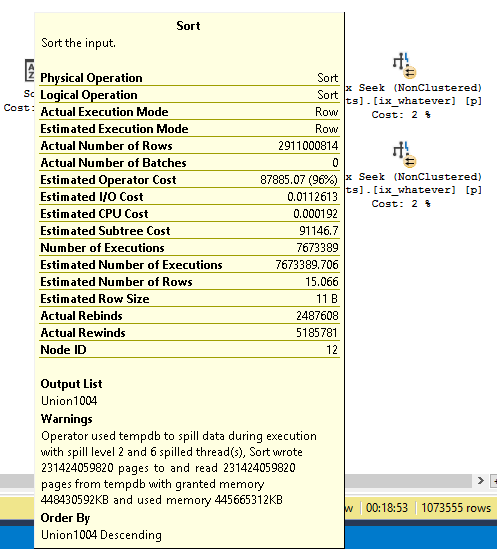
Here’s a much larger spill that’s still only at level two.
Insert more commas.
That’s um… hang on.
231,424,059,820 rows. It’s crazy that we can add 223,308,775,847 rows to a spill and not need more passes than before.
But hey, okay. That’s cool. I get it.
Waaaaaiiiiitttt
I found level three! With uh 97,142 pages. That’s weird. I don’t get it.
But whatever, it probably can’t get much weirder than
…
SPILL LEVEL 8 FOR 43,913 PAGES 1-800-COME-ON-YO!
This Is Gonna Take More Digging
I’m gonna have my eye on weird spill levels from now on, and I’ll try to follow up as I figure stuff out.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
That’s a pretty good start, but what about other kinds of writes, like the ones outlined in the Q&A I linked to?
So uh, I wrote this script to find them.
Downsides
The downsides here are that it’s looking at the plan cache, so I can’t show you which operator is spilling. You’ll have to figure that out on your own.
The source of the writes may be something else, too. It could be a spool, or a stats update, etc. That’s why I tried to set the spill size (1024.) kind of high, to not detect trivial writes.
WITH
XMLNAMESPACES
('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS x),
writes AS
(
SELECT TOP (100)
deqs.statement_start_offset,
deqs.statement_end_offset,
deqs.plan_handle,
deqs.creation_time,
deqs.last_execution_time,
deqs.total_logical_writes,
deqs.last_logical_writes,
deqs.min_logical_writes,
deqs.max_logical_writes,
deqs.query_hash,
deqs.query_plan_hash
FROM sys.dm_exec_query_stats AS deqs
WHERE deqs.min_logical_writes > 1024.
ORDER BY deqs.min_logical_writes DESC
),
plans AS
(
SELECT DISTINCT
w.plan_handle,
w.statement_start_offset,
w.statement_end_offset,
w.creation_time,
w.last_execution_time,
w.total_logical_writes,
w.last_logical_writes,
w.min_logical_writes,
w.max_logical_writes
FROM writes AS w
CROSS APPLY sys.dm_exec_query_plan(w.plan_handle) AS deqp
CROSS APPLY deqp.query_plan.nodes('//x:StmtSimple') AS s(c)
WHERE deqp.dbid > 4
AND s.c.value('@StatementType', 'VARCHAR(100)') = 'SELECT'
AND NOT EXISTS
(
SELECT
1/0 --If nothing comes up, quote out the NOT EXISTS.
FROM writes AS w2
CROSS APPLY deqp.query_plan.nodes('//x:StmtSimple') AS s2(c)
WHERE w2.query_hash = w.query_hash
AND w2.query_plan_hash = w.query_plan_hash
AND s2.c.value('@StatementType', 'VARCHAR(100)') <> 'SELECT'
)
)
SELECT
p.creation_time,
p.last_execution_time,
p.total_logical_writes,
p.last_logical_writes,
p.min_logical_writes,
p.max_logical_writes,
text =
SUBSTRING
(
dest.text,
( p.statement_start_offset / 2 ) + 1,
((
CASE p.statement_end_offset
WHEN -1
THEN DATALENGTH(dest.text)
ELSE p.statement_end_offset
END - p.statement_start_offset
) / 2 ) + 1
),
deqp.query_plan
FROM plans AS p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS dest
CROSS APPLY sys.dm_exec_query_plan(p.plan_handle) AS deqp
ORDER BY p.min_logical_writes DESC
OPTION ( RECOMPILE );
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is a short post to “document” something interesting I noticed about… It’s kind of a mouthful.
See, hash joins will bail out when they spill to disk enough. What they bail to is something akin to Nested Loops (the hashing function stops running and partitioning things).
This usually happens when there are lots of duplicates involved in a join that makes continuing to partition values ineffective.
It’s a pretty atypical situation, and I really had to push (read: hint the crap out of) a query in order to get it to happen.
I also had to join on some pretty dumb columns.
Dupe-A-Dupe
Here’s a regular row store query. Bad idea hints and joins galore.
SELECT *
FROM dbo.Posts AS p
LEFT JOIN dbo.Votes AS v
ON p.PostTypeId = v.VoteTypeId
WHERE ISNULL(v.UserId, v.VoteTypeId) IS NULL
OPTION (
HASH JOIN, -- If I don't force this, the optimizer chooses Sort Merge. Smart!
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'),
MAX_GRANT_PERCENT = 0.0
);
As it runs, the duplicate-filled columns being forced to hash join with a tiny memory grant cause a bunch of problems.
The value is a constant, hard coded in the product, and its value is five (5). This means that before the hash scan operator resorts to a sort based algorithm for any given subpartition that doesn’t fit into the granted memory from the workspace, five previous attempts to subdivide the original partition into smaller partitions must have happened.
At runtime, whenever a hash iterator must recursively subdivide a partition because the original one doesn’t fit into memory the recursion level counter for that partition is incremented by one. If anyone is subscribed to receive the Hash Warning event class, the first partition that has to recursively execute to such level of depth produces a Hash Warning event (with EventSubClass equals 1 = Bailout) indicating in the Integer Data column what is that level that has been reached. But if any other partition later also reaches any level of recursion that has already been reached by other partition, the event is not produced again.
It’s also worth mentioning that given the way the event reporting code is written, when a bail-out occurs, not only the Hash Warning event class with EventSubClass set to 1 (Bailout) is reported but, immediately after that, another Hash Warning event is reported with EventSubClass set to 0 (Recursion) and Integer Data reporting one level deeper (six).
But It’s Different With Batch Mode
If I get batch mode involved, that changes.
CREATE TABLE #hijinks (i INT NOT NULL, INDEX h CLUSTERED COLUMNSTORE);
SELECT *
FROM dbo.Posts AS p
LEFT JOIN dbo.Votes AS v
ON p.PostTypeId = v.VoteTypeId
LEFT JOIN #hijinks AS h ON 1 = 0
WHERE ISNULL(v.UserId, v.VoteTypeId) IS NULL
OPTION (
HASH JOIN, -- If I don't force this, the optimizer chooses Sort Merge. Smart!
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'),
MAX_GRANT_PERCENT = 0.0
);
The plan yields several batch mode operations, but now we start bailing out after three recursions.
Creeky
I’m not sure why, and I’ve never seen it mentioned anywhere else.
My only guess is that the threshold is lower because column store and batch mode are a bit more memory hungry than their row store counterparts.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
They also don’t show spills. Say I’ve got a query running, and it’s taking a long time.
I’ve got live query plans turned on, so I can see what it’s up to.
21 minute salute
Hm. Well, that’s not a very full picture. What if I go get the live query plan XML myself?
SELECT deqs.query_plan
FROM sys.dm_exec_sessions AS des
CROSS APPLY sys.dm_exec_query_statistics_xml(des.session_id) AS deqs;
There are three operators showing spills so far.
Leading me on
Frosted Tips
Even if I go look at the tool tips for operators registering spills, they don’t show anything.
Do not serve this operator
It’s fine if SSMS doesn’t decide to re-draw icons with little exclamation points, but if information about runtime and rows processed can be updated in real-ish time, information about spills should be, too.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
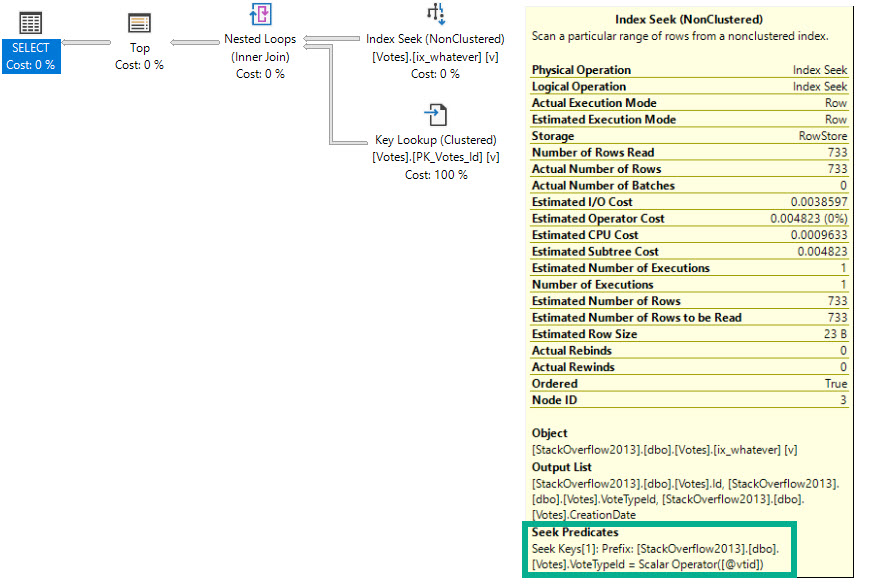
If you saw my post about parameterized TOPs, one thing you may have immediately hated is the index I created.
And rightfully so — it was a terrible index for reasons we’ll discuss in this post.
If that index made you mad, congratulations, you’re a smart cookie.
CREATE INDEX whatever ON dbo.Votes(CreationDate DESC, VoteTypeId)
GO
Yes, my friends, this index is wrong.
It’s not just wrong because we’ve got the column we’re filtering on second, but because there’s no reason for it to be second.
Nothing in our query lends itself to this particular indexing scenrio.
CREATE OR ALTER PROCEDURE dbo.top_sniffer (@top INT, @vtid INT)
AS
BEGIN
SELECT TOP (@top)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
We Index Pretty
The reason I sometimes see columns appear first in an index is to avoid having to physically sort data.
If I run the stored procedure without any nonclustered indexes, this is our query plan:
EXEC dbo.top_sniffer @top = 1, @vtid = 1;
spillo
A sort, a spill, kablooey. We’re not having any fun, here.
With the original index, our data is organized in the order that we’re asking for it to be returned in the ORDER BY.
This caused all sorts of issues when we were looking for VoteTypeIds that were spread throughout the index, where we couldn’t satisfy the TOP quickly.
There was no Sort in the plan when we had the “wrong” index added.
Primal
B-Tree Equality
We can also avoid having to sort data by having the ORDER BY column(s) second in the key of the index, because our filter is an equality.
CREATE INDEX whatever ON dbo.Votes(VoteTypeId, CreationDate DESC)
GO
Having the filter column first also helps us avoid the longer running query issue when we look for VoteTypeId 4.
EXEC dbo.top_sniffer @top = 5000, @vtid = 4;
I like you better.
Table 'Votes'. Scan count 1, logical reads 2262
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 148 ms.
Solving for Sorts
If you’ve been following my blogging for a while, you’ve likely seen me say this stuff before, because Sorts have some issues.
They’re locally blocking, in that every row has to arrive before they can run
They require additional memory space to order data the way you want
They may spill to disk if they don’t get enough memory
They may ask for quite a bit of extra memory if estimations are incorrect
They may end up in a query plan even when you don’t explicitly ask for them
There are plenty of times when these things aren’t problems, but it’s good to know when they are, or when they might turn into a problem.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
My least favorite tempdb spills are the ones that happen with a large percentage of the memory grant remaining unused. For example, recently I saw tempdb spills with a memory grant of 35 GB but SQL Server reported that only 10 GB of memory was used. Usually this problem can be traced back to suboptimal memory fractions somewhere in a query plan. I suspect that it can also happen with certain types of queries that load data into columnstore tables but haven’t verified that. In the test environment the issue was caused by memory fractions, but these memory fractions were attached to batch mode operators. The rules for batch mode memory fractions certainly appear to be different than those for rowstore memory fractions. I believe that I was able to work out a few of the details for a few simple cases. In some scenarios, plans with multiple batch mode hash joins can ask for significantly more memory than needed. Reducing the memory grant via Resource Governor or a query hint to something more reasonable can lead to unnecessary (and often frustrating) tempdb spills.
What is a Memory Fraction?
There’s very little information out there about memory fractions. I would define them as information in the query plan that can give you clues about each operator’s share of the total query memory grant. This is naturally more complicated for query plans that insert into tables with columnstore indexes but that won’t be covered here. Most references will tell you not to worry about memory fractions or that they aren’t useful most of the time. Out of thousands of queries that I’ve tuned I can only think of a few for which memory fractions were relevant. Sometimes queries spill to tempdb even though SQL Server reports that a lot of query memory was unused. In these situations I generally hope for a poor cardinality estimate which leads to a memory fraction which is too low for the spilling operator. If fixing the cardinality estimate doesn’t prevent the spill then things can get a lot more complicated, assuming that you don’t just give up.
Types of Query Plans
The demos for this blog post all use tables with identical structures and data. The tables are heaps so the plans will only feature hash joins. The most important plan characteristic is how many of the hash tables need to be kept in memory concurrently while the query processor executes the query. This is where memory fractions come in. The query optimizer tries to reuse parts of memory grants as it can. For example, if the hash build for the first join isn’t needed when the third join executes then it’s possible to use the memory grant from the first hash table for the third hash table. Some of the examples below will make this more clear.
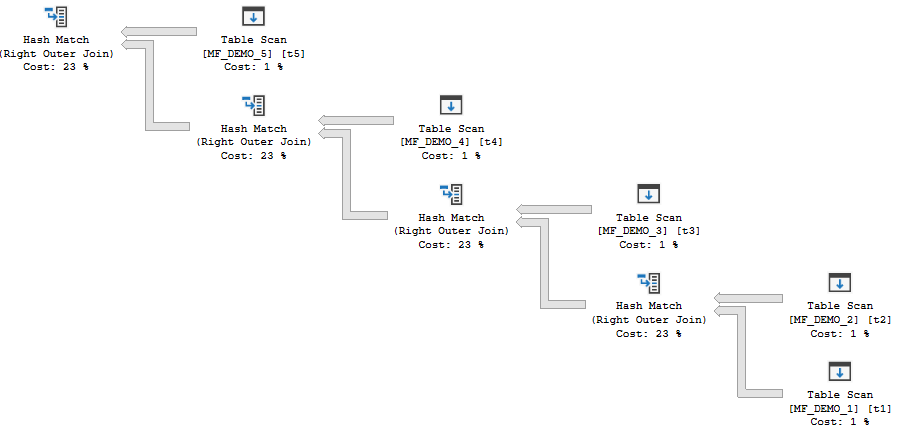
The first type of plan has hash joins which can all run concurrently. Memory for the hash tables cannot be reused between operators.
bushy
For that query, the MF_DEMO_1 table is the probe side for all of the joins. SQL Server builds all of the hash joins and then rows flow from the probe side through the plan (as long as there aren’t tempdb spills). I will refer to this type of plan as a “concurrent join plan” which is a term that I just made up.
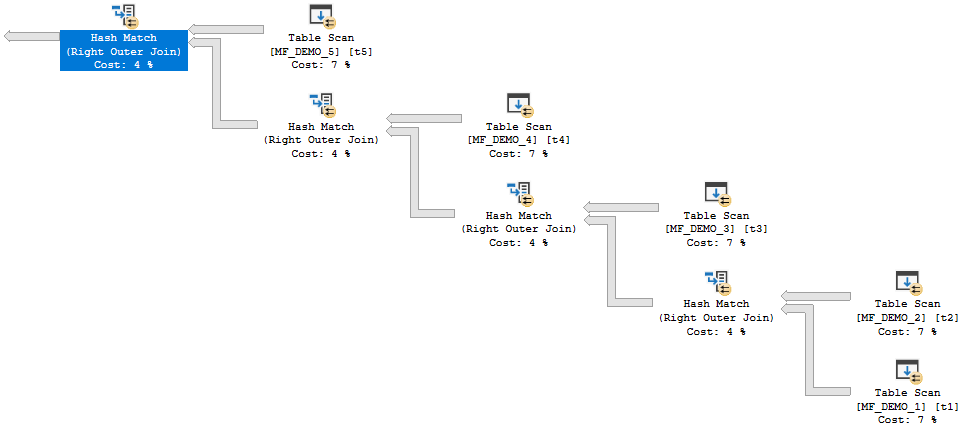
The second type of plan has hash joins which cannot all run concurrently. Pairs of hash tables are active at the same time, but memory grants can be reused between operators.
not bushy
For that query, the MF_DEMO_1 table is the build side for all of the joins. Each hash table blocks the next one from starting. This means that at most two hash tables need to be kept in memory at the same time. Query memory cannot be reused for joins 1 and 2 but join 3 can reuse memory from join 1 and join 4 can reuse memory from join 2. I will refer to this type of plan as a “nonconcurrent join plan” which is another term that I just made up.
If the above wasn’t clear I recommend running through the demos with live query statistics enabled. It can be very useful to understand how rows flow through a plan. As far as I know, all queries of this type can be implemented with the nonconcurrent pattern but not all queries can be implemented with the concurrent pattern .
Create the Tables
The table definitions for our demos are pretty boring. I’m using a VARCHAR(100) as the join column to blow up memory grants and requirements a bit. All of the tables are heaps and have about 6.5 million rows in them. TARGET_TABLE is used as a dumping ground for the inserts and #ADD_BATCH_MODE is used to switch the hash joins to batch mode as desired. All testing was done on SQL Server 2016 SP1 CU7.
DROP TABLE IF EXISTS MF_DEMO_1;
CREATE TABLE MF_DEMO_1 (
ID VARCHAR(100)
);
INSERT INTO MF_DEMO_1 WITH (TABLOCK)
SELECT 999999999999999 + ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CREATE STATISTICS S1 ON MF_DEMO_1 (ID) WITH FULLSCAN;
DROP TABLE IF EXISTS MF_DEMO_2;
CREATE TABLE MF_DEMO_2 (
ID VARCHAR(100)
);
INSERT INTO MF_DEMO_2 WITH (TABLOCK)
SELECT 999999999999999 + ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CREATE STATISTICS S2 ON MF_DEMO_2 (ID) WITH FULLSCAN;
DROP TABLE IF EXISTS MF_DEMO_3;
CREATE TABLE MF_DEMO_3 (
ID VARCHAR(100)
);
INSERT INTO MF_DEMO_3 WITH (TABLOCK)
SELECT 999999999999999 + ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CREATE STATISTICS S3 ON MF_DEMO_3 (ID) WITH FULLSCAN;
DROP TABLE IF EXISTS MF_DEMO_4;
CREATE TABLE MF_DEMO_4 (
ID VARCHAR(100)
);
INSERT INTO MF_DEMO_4 WITH (TABLOCK)
SELECT 999999999999999 + ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CREATE STATISTICS S4 ON MF_DEMO_4 (ID) WITH FULLSCAN;
DROP TABLE IF EXISTS MF_DEMO_5;
CREATE TABLE MF_DEMO_5 (
ID VARCHAR(100)
);
INSERT INTO MF_DEMO_5 WITH (TABLOCK)
SELECT 999999999999999 + ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
CREATE STATISTICS S5 ON MF_DEMO_5 (ID) WITH FULLSCAN;
CREATE TABLE #ADD_BATCH_MODE (I INT, INDEX CCI CLUSTERED COLUMNSTORE);
DROP TABLE IF EXISTS TARGET_TABLE;
CREATE TABLE TARGET_TABLE (ID VARCHAR(100));
Row Mode Memory Fractions For Concurrent Join Plans
The following query results in a concurrent join plan with row mode hash joins:
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_3 t3
RIGHT OUTER JOIN MF_DEMO_2 t2
RIGHT OUTER JOIN MF_DEMO_1 t1
ON t1.ID = t2.ID
ON t1.ID = t3.ID
OPTION (FORCE ORDER, MAXDOP 1);
The desired memory grant is 2860640 KB. The memory fractions for both join operators have an input of 0.5 and an output of 0.5. This is exactly as expected. The hash tables can both start at the same time and cannot reuse memory, so each operator gets 50% of the query memory grant for the plan. Adding a third join to the plan increases the query memory grant to 4290960 KB.
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_4 t4
RIGHT OUTER JOIN MF_DEMO_3 t3
RIGHT OUTER JOIN MF_DEMO_2 t2
RIGHT OUTER JOIN MF_DEMO_1 t1
ON t1.ID = t2.ID
ON t1.ID = t3.ID
ON t1.ID = t4.ID
OPTION (FORCE ORDER, MAXDOP 1);
Again, this seems very reasonable. SQL Server now tries to builds three hash tables in memory at the same time. The memory fractions for each operator have fallen to 0.3333333. Each operator gets a third of the query memory grant.
Row Mode Memory Fractions For Nonconcurrent Join Plans
The following query results in a nonconcurrent join plan with row mode hash joins:
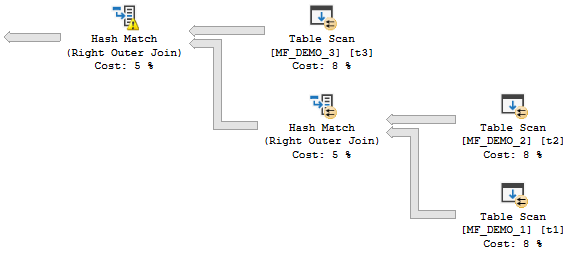
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_1 t1
INNER JOIN MF_DEMO_2 t2 ON t1.ID = t2.ID
INNER JOIN MF_DEMO_3 t3 ON t2.ID = t3.ID
INNER JOIN MF_DEMO_4 t4 ON t3.ID = t4.ID
OPTION (MAXDOP 1, FORCE ORDER);
The query plan was uploaded here. I recommend downloading the all of the plans referenced in this blost post if you’re interested in them so you can see all of the details.
Here are the memory fractions for the rightmost join (node 3):
What do all of those numbers mean? The rightmost join builds its hash table first and starts with all query memory available to it. However, the output fraction is 0.476174. That means that the hash table can only use up to 47.6% of the query memory granted to the plan. The middle join is able to use up to 50% (the minimum of the input and output fractions for the node) of the memory granted to the plan. Note that 0.476174 + 0.523826 = 1.0. The last join to start executing is also able to use up to 50% of the granted memory. That join is the last operator that uses memory in the plan so the output fraction is 1.0. Memory grant reuse allows the plan to use up to 147.6% of the memory grant over the lifetime of the query execution. Without memory grant reuse each operator wouldn’t be able to use as much memory.
Removing one of the joins results in the desired query memory grant dropping from 3146704 KB to 3003672 KB. This is a significantly less drop than the other query. The smaller decrease is expected because the third join that we added can reuse the memory grant from the first. As more joins are added to a nonconcurrent plan the desired memory grant grows at a much slower rate than the memory grant for the concurrent join plan.
Batch Mode Memory Fractions For Concurrent Join Plans
The query plan for the next query is somewhat dependent on hardware. On my machine I had to let it run in parallel to get batch mode hash joins:
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_5 t5
RIGHT OUTER JOIN MF_DEMO_4 t4
RIGHT OUTER JOIN MF_DEMO_3 t3
RIGHT OUTER JOIN MF_DEMO_2 t2
RIGHT OUTER JOIN MF_DEMO_1 t1
LEFT OUTER JOIN #ADD_BATCH_MODE ON 1 = 0
ON t1.ID = t2.ID
ON t1.ID = t3.ID
ON t1.ID = t4.ID
ON t1.ID = t5.ID
OPTION (FORCE ORDER, MAXDOP 4);
The estimated plan is here. It’s easy to tell if the query is using batch mode joins because the joins are run in parallel but there are no repartition stream operators.
parallel and bushy
SQL Server is not able to reuse memory grants for this query. SQL Server tries to build all of the hash tables in memory before probe side is processed. However, the memory fractions are different from before: 0.25, 0.5, 0.75, and 1.0. These memory fractions do not make sense if interpreted in the same way as before. How can the final hash join in the plan have an input memory fraction of 1.0?
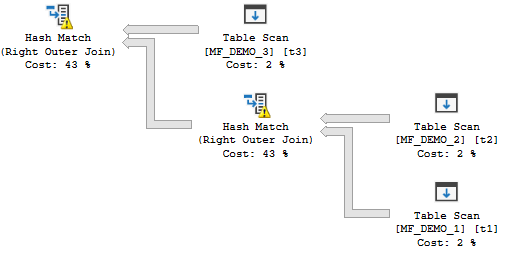
It’s unclear what the memory fractions are supposed to mean here, but there is one observable difference compared to the row mode plan. In the row mode equivalent plan SQL Server divides the memory evenly between operators. For our very simple test plan this means that all of the hash joins will spill to tempdb or none of them will spill. Reducing a MAX_GRANT_PERCENT hint from the right value by 1% results in two spills:
spilly
Both operators spilled because memory was divided evenly and there wasn’t enough memory to hold both hash tables in memory. However, with batch mode hash joins we can get plans like the following:
spilly
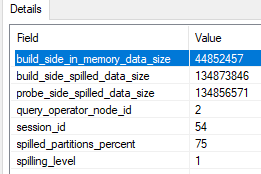
How is it possible that one join spills but the other doesn’t? It is only possible if memory isn’t divided evenly. It appears that memory is used as needed in some situations. Unfortunately, the actual plan for batch mode operators doesn’t give us a lot of spill information like it does for row mode. There’s a debug channel extended event query_execution_batch_hash_join_spilled that can give us some clues. 657920 KB of memory was granted for a two batch mode hash join query. For the operator that spilled, only 44852457 bytes were written to memory on the build side. That’s about 43800 KB, which is significantly less than half of available query memory.
spills!
We can’t conclude that exactly 44852457 bytes of memory were granted to the operator. However, it should be somewhat close. In conclusion, for these types of queries it isn’t clear what the memory grant fractions are supposed to mean. SQL Server is able to exceed them in some cases. It’s possible to see 0 bytes of memory used for the build side in the extended event. I believe that this is the bad type of memory reuse as opposed to the good kind.
Batch Mode Memory Fractions For Nonconcurrent Join Plans
The following query results in a nonconcurrent batch mode hash join plan on my machine:
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_1 t1
LEFT OUTER JOIN #ADD_BATCH_MODE On 1 = 0
WHERE EXISTS (
SELECT 1
FROM MF_DEMO_2 t2 WHERE t1.ID = t2.ID
) AND EXISTS (
SELECT 1
FROM MF_DEMO_3 t3 WHERE t1.ID = t3.ID
) AND EXISTS (
SELECT 1
FROM MF_DEMO_4 t4 WHERE t1.ID = t4.ID
) AND EXISTS (
SELECT 1
FROM MF_DEMO_5 t5 WHERE t1.ID = t5.ID
) OPTION (MAXDOP 4, FORCE ORDER);
As far as I know there’s nothing special about the semijoins. I used them to keep the estimated row size as consistent as possible. The behavior detailed below can be observed with normal joins as well.
Here is the estimated query plan. The same memory fraction pattern of 0.25, 0.50, 0.75, and 1.00 can be found in this query. Based on the query’s structure, memory grant reuse should be allowed between operators. Alarmingly, this query has the same desired memory grant as one with four concurrent joins. The desired memory grant changes significantly as tables are added or removed. This is a big change in behavior compared to row mode batch joins.
As far as I can tell, memory grant reuse can happen in plans like this with batch mode hash joins. Removing or adding joins results in very small adjustments in maximum memory used during query execution. Still, it seems as if the query optimizer is assuming that memory cannot be reused. With this query pattern, the first operator to run does not have access more memory implied by the memory fraction. In fact, it has access to less memory implied by the memory fraction.
Running the query without any memory grant hints results in no tempdb spills and a maximum memory use of 647168 KB. Restricting the memory grant to 2 GB results in a tempdb spill for the rightmost operator. This is unexpected. 500000 KB of memory should be more than enough memory to avoid a spill. As before, the only way I could find to investigate this further was to use the query_execution_batch_hash_join_spilled extended event and to force tempdb spills using the MAX_GRANT_PERCENT query hint.
A good amount of testing suggested that the available memory per operator is the input memory fraction for that operator divided by the sum of all output memory fractions. The rightmost operator only gets 0.25 / (0.25 + 0.5 + 0.75 + 1.0) = 10% of the memory granted to the query, the next operator gets 20%, the next operator gets 30%, and the final operator gets 40%. The situation gets worse as more joins are added to the query. Keep in mind that we aren’t doing anything tricky with cardinality estimates or data types which would result in skewed estimates. The query optimizer seems to recognize that each join will require the same amount of memory for each hash join, but it doesn’t make the same minimum amount available for each operator. That’s what is so puzzling.
The preceding paragraph seems to contradict the idea that memory grant reuse is possible for these plan shapes. Perhaps for these simple plans memory grant reuse is possible but it cannot go above 100% like we saw in the row mode plan. This could still be helpful in that the query could steal less memory from the buffer pool, but it’s certainly not as helpful in avoiding spills as the behavior we get with the row mode plan. Under the assumption the total memory grants seem a bit more reasonable, although it’s hard not to object as to how SQL Server is distributing the memory to each operator.
We can avoid the spill by giving SQL Server the memory that it required, but this is undesirable if multiple concurrent queries are running. I’ve often observed higher than expected memory grants for queries with batch mode hash joins. An assumption that query memory reuse will not be available for batch mode hash joins can explain part of what I’ve observed. If memory grants are left unchecked, applications may see decreased possible concurrency due to RESOURCE_SEMAPHORE waits. Lowering memory grants through any available method can result in unnecessary (based on total memory granted) tempdb spills. It’s easy to get stuck between a rock and a hard place.
Batch Mode Workarounds
There is some hope for nonconcurrent batch mode hash join plans. SQL Server 2017 introduces adaptive memory feedback for these operators. I imagine that functionality is a poor fit for ETL queries which may process dramatically different amounts of data each day, so I can’t view it as a complete solution. It certainly doesn’t help us on SQL Server 2016. Are there workarounds to prevent spills without requiring excessive memory grants? Yes, but they are very ugly and I can only imagine using them when truly needed during something like an ETL process.
Consider the following query:
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_1 t1
LEFT OUTER JOIN MF_DEMO_2 t2 ON t2.ID = t1.ID
LEFT OUTER JOIN MF_DEMO_3 t3 ON t3.ID = t2.ID
LEFT OUTER JOIN MF_DEMO_4 t4 ON t4.ID = t3.ID
LEFT OUTER JOIN MF_DEMO_4 t5 ON t5.ID = t4.ID
LEFT OUTER JOIN #ADD_BATCH_MODE ON 1 = 0
OPTION (FORCE ORDER, MAXDOP 4, MAX_GRANT_PERCENT = 60);
On my machine, the memory hint results in a memory grant of 2193072 KB. The rightmost join spills even when only a maximum of 1232896 KB of memory is used during query execution:
more spills!
One way to avoid the spill is to shift the memory fractions in our favor. Ideally SQL Server would think that the rightmost join would need much more memory for its hash table than the other joins. If we can add an always NULL column with a large data type that is only needed for the first hash table, that might do the trick. The query syntax below isn’t guaranteed to get the plan that we want but it seems to work in this case:
ALTER TABLE MF_DEMO_1 ADD DUMMY_COLUMN_V4000 VARCHAR(4000) NULL;
ALTER TABLE MF_DEMO_2 ADD DUMMY_COLUMN_V10 VARCHAR(10) NULL;
INSERT INTO TARGET_TABLE WITH (TABLOCK)
SELECT t1.ID
FROM MF_DEMO_1 t1
LEFT OUTER JOIN MF_DEMO_2 t2 ON t2.ID = t1.ID
LEFT OUTER JOIN MF_DEMO_3 t3 ON t3.ID = t2.ID
LEFT OUTER JOIN MF_DEMO_4 t4 ON t4.ID = t3.ID
LEFT OUTER JOIN MF_DEMO_4 t5 ON t5.ID = t4.ID
LEFT OUTER JOIN #ADD_BATCH_MODE ON 1 = 0
WHERE (t1.DUMMY_COLUMN_V4000 IS NULL OR t2.DUMMY_COLUMN_V10 IS NULL)
OPTION (FORCE ORDER, MAXDOP 4, MAX_GRANT_PERCENT = 32);
An actual plan was uploaded here. The query no longer spills even though the memory grant was cut to 1225960 KB. The memory fractions are now 0.82053, 0.878593, 0.936655, and 1. The change was caused by the increase in estimated row size for the rightmost join: 2029 bytes. That row size is reduced to 45 bytes after the filter is applied, which won’t filter out any rows because both columns are always NULL. The FORCE ORDER hint is essential to get this plan shape. It’s very unnatural otherwise.
If the same rules are followed as before, the rightmost join should get 22.5% of the available query memory grant now. This is enough to avoid the spill to tempdb.
Final Thoughts
I understand that the formulas for memory fractions need to account for an arbitrary combination of row mode and batch mode operators in a query plan. However, it is disappointing that the available information for memory fractions for batch mode operators is so confusing, some queries with batch mode hash joins ask for way more memory than they need, and some queries needlessly spill to tempdb without using close to their full memory grant. Batch mode adaptive memory grant feedback can offer some relief in SQL Server 2017, but why not expect good plans the first time as long as we’re giving the query optimizer good information?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.