Resource Governor can be used to enforce a hard cap on query MAXDOP, unlike the sp_configure setting. However, query plan compilation does not take such a MAXDOP limit into account. As a result, limiting MAXDOP through Resource Governor can lead to unexpected degradations in performance due to suboptimal query plan choices.
Create Your Tables
We start with the not often seen here three table demo. I’d rather not explain how I came up with this sample data, so I’m not going to. I did my testing on a server with max server memory set to 10000 MB. The following tables take about half a minute to create and populate and only take up about 1.5 GB of space:
DROP TABLE IF EXISTS dbo.SMALL;
CREATE TABLE dbo.SMALL (ID_U NUMERIC(18, 0));
INSERT INTO dbo.SMALL WITH (TABLOCK)
SELECT TOP (100) 5 * ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
OPTION (MAXDOP 1);
DROP TABLE IF EXISTS dbo.MEDIUM;
CREATE TABLE dbo.MEDIUM (ID_A NUMERIC(18, 0));
INSERT INTO dbo.MEDIUM WITH (TABLOCK)
SELECT TOP (600000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
OPTION (MAXDOP 1);
DROP TABLE IF EXISTS dbo.LARGE;
CREATE TABLE dbo.LARGE (
ID_A NUMERIC(18, 0),
ID_U NUMERIC(18, 0),
FILLER VARCHAR(100)
);
INSERT INTO dbo.LARGE WITH (TABLOCK)
SELECT 2 * ( RN / 4), RN % 500, REPLICATE('Z', 100)
FROM
(
SELECT TOP (8000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) q
OPTION (MAXDOP 1)
CREATE INDEX IA ON LARGE (ID_A);
CREATE INDEX IU ON LARGE (ID_U);
The Long-Awaited Demo
I thought up the theory behind this demo on a car ride back from a SQL Saturday, but wasn’t able to immediately figure out a way to get the query plan that I wanted. I ended up finally seeing it in a totally different context and am now happy to share it with you. Consider the following query:
SELECT LARGE.ID_U
FROM dbo.SMALL
INNER JOIN dbo.LARGE ON SMALL.ID_U = LARGE.ID_U
INNER JOIN dbo.MEDIUM ON LARGE.ID_A = MEDIUM.ID_A
OPTION (MAXDOP 1);
The MAXDOP 1 hints results in a serial plan with two hash joins:
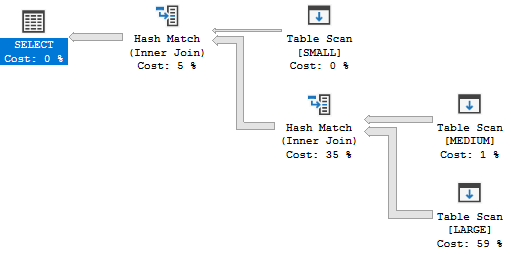
This is a perfectly reasonable plan given the size and structure of the tables. There are no bitmap filters because row mode bitmap filters are only supported for parallel plans. Batch mode is not considered for this query because I’m testing on SQL Server 2017 and there isn’t a columnstore index on any of the tables referenced in the query. On my machine a single query execution uses 2422 of CPU time and 2431 ms of elapsed time.
A parallel plan at MAXDOP 4 is able to run more quickly but with a much higher CPU time. A single execution of the MAXDOP 4 query uses 5875 ms of CPU time and 1617 ms of elapsed time. There are multiple bitmap filters present. I zoomed in on the most interesting part of the plan because I haven’t figured out how images work with WordPress yet:
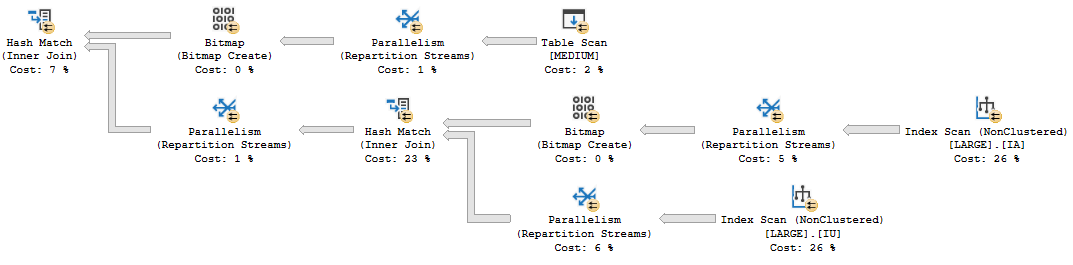
Instead of doing a scan of the LARGE table, SQL Server instead chooses an index intersection plan. The cost of the additional hash join is reduced by multiple bitmap filters. There are only 2648396 and 891852 rows processed on the build and probe side instead of 8 million for each side, which is a significant gain.
Worse Than A Teen Running for Governor
Some end users really can’t be trusted with the power to run parallel plans. I thought about making a joke about an “erik” end user but I would never subject my readers to the same joke twice. After enforcing a MAXDOP of 1 at the Resource Governor level, you will probably not be shocked to learn that the query with the explicit MAXDOP 1 hint gets the same query plan as before and runs with the same amount of CPU and elapsed time.
If you skipped or forget the opening paragraph, you may be surprised to learn that the query with a MAXDOP 4 hint also gets the same query plan as before. The actual execution plan even has the parallel racing arrows. However, the query cannot execute in parallel. The parallelism and bitmap operators are skipped by the query processor and all of the rows are processed on one thread:
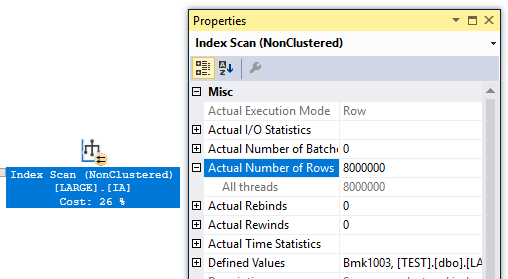
I uploaded the query plan here if you want to look at it. This type of scenario can happen even without Resource Governor. For example, a compiled parallel query may be downgraded all the way to MAXDOP 1 if it can’t get enough parallel threads.
The query performs significantly worse than before, which hopefully is not a surprise. A single execution took 12860 ms of CPU time and 13078 ms of elapsed time. Nearly all of the query’s time is spent on the hash join for the index intersection, with a tempdb spill and the processing of additional rows both playing a role. The tempdb spill occurs because SQL Server expected the build side of the hash join to be reduced to 1213170 rows. The bitmap filtering does not occur so 8 million rows were sent to the build side instead.
In this case, adding a MAXDOP 1 hint to the query will improve performance by about 5X. Larger differences in run times can be easily seen on servers with more memory than my desktop.
Final Thoughts
If you’re using using Resource Governor to limit MAXDOP to 1, consider adding explicit MAXDOP 1 hints at the query level if you truly need the best possible performance. The MAXDOP 1 hint may at first appear to be redundant, but it gives the query optimizer additional information which can result in totally different, and sometimes significantly more efficient, query plans. I expect that this problem could be avoided if query plan caching worked on a Resource Governor workload group level. Perhaps that is one of those ideas that sounds simple on paper but would be difficult for Microsoft to implement. Batch mode for row store can somewhat mitigate this problem because batch mode bitmap filters operate even under MAXDOP 1, but you can still get classic row mode bitmaps even on SQL Server 2019.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.

