You have alerts for when jobs fail, when they run long, and they’re all emailed to the ENTIRE COMPANY in beautifully formatted CSS.
Have a cigar.
But we all go on vacation sometime.
Overtime
One thing that can make a workload feel artificially sluggish is maintenance.
Index stuff: Lotsa work, sometimes blocking
Backup stuff: Native fulls of VLDBs, with compression
DBCC CHECKDB: Oh, you forgot to run this because you were busy rebuilding indexes
Darn. Gimme that cigar back.
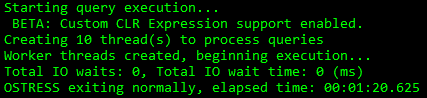
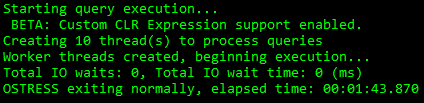
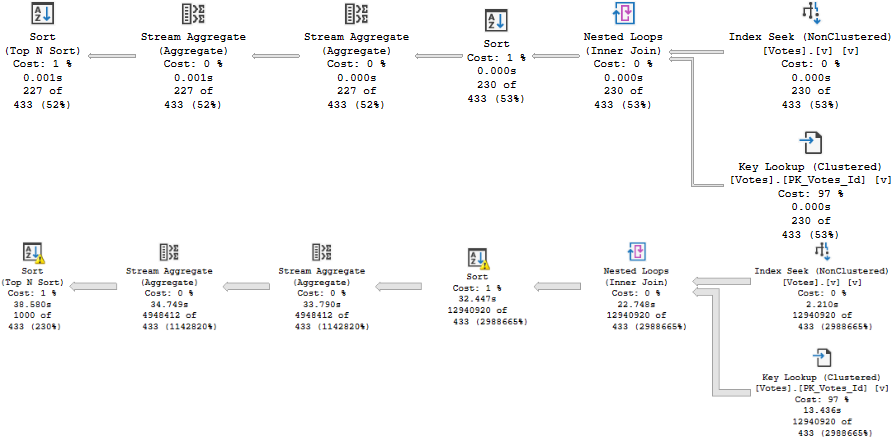
Right now, I’ve got a DBCC CHECK, and a query workload, that both run for one minute and 20 seconds when they run alone.
Quick QueriesDoublefast DBCC CHECKDB
Overlap
The problem becomes when I run them both at the same time. The query workload runs for about 25 seconds longer, and CHECKDB runs for two and a half minutes.
That’s like, almost twice as long.
Ugly QueriesDusty DBCC CHECKDB
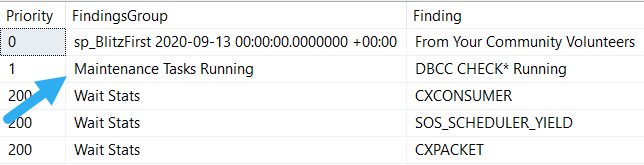
Now, it’s okay if you don’t have all those alerts set up. I guess.
Because you can use sp_BlitzFirst to see what’s going on, and get warned:
If you can end maintenance tasks and have performance go back to normal-bad, congratulations! You’ve solved today’s problem.
Have a cigar.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This isn’t the way most people do it, but it is the least impactful.
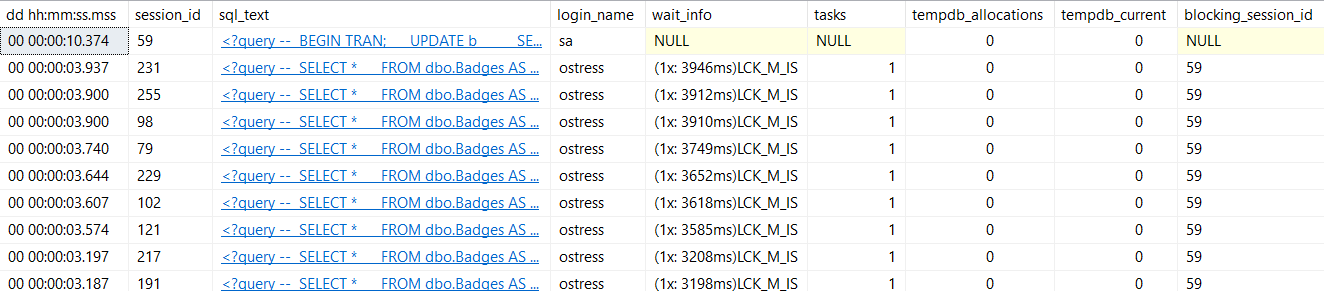
You get back the normal set of results:
peachy
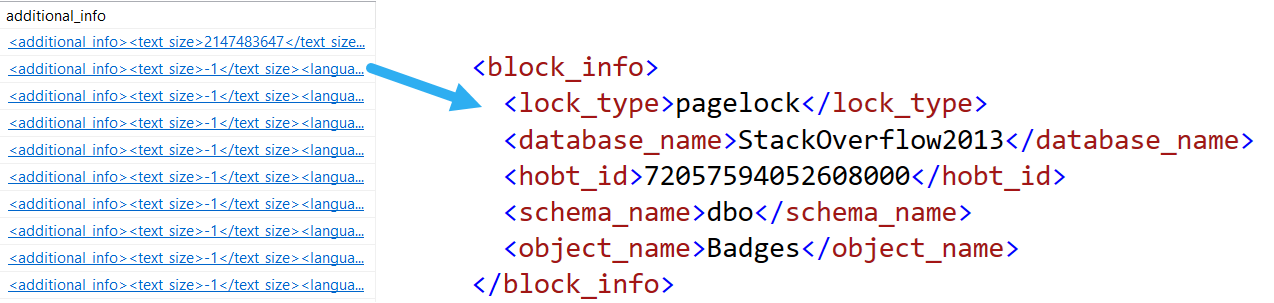
Cool, you can see queries, lock waits, and blocking sessions. But a short scroll to the right also brings you to this additional_info clickable column:
oily water
It’s not so helpful for the query doing the blocking, but it’ll tell you what the queries being blocked are stuck on.
The usual way
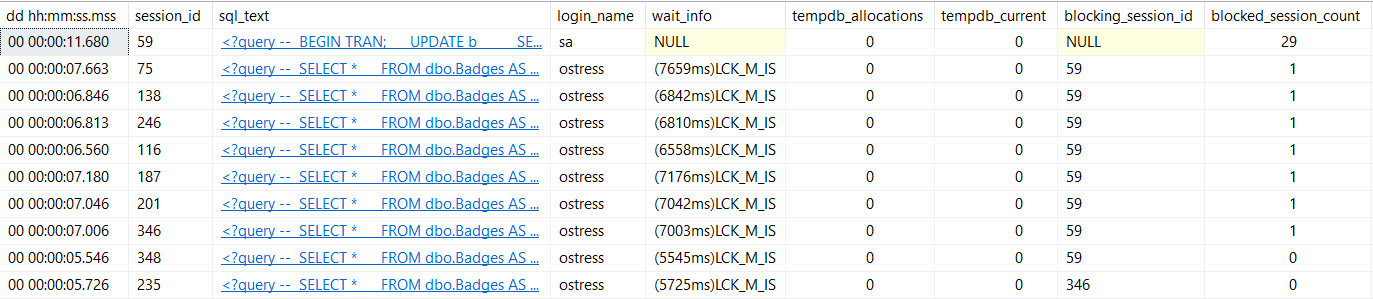
EXEC sp_WhoIsActive @get_locks = 1;
This is the way I normally demo looking for blocking with it, because it is more useful to see what the blocking query is doing.
But I’ve also had it be slow. Really, really slow.
That can happen when there is JUST SO MUCH BLOCKING that it takes a long time to enumerate all of it.
It’s not always obvious by runtime which session is causing blocking, so you can use this command to find blocking chains, and order output by who’s doing the most blocking.
troubleshot
Fixins
When you need to troubleshoot live blocking, these are the ways I usually check in on things with sp_WhoIsActive. It’s hard to beat.
We’ve peeled back a couple scenarios where oddball things can slow a server down. Tomorrow we’ll look at a new one!
What’ll it be?
Your guess is not as good as mine.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Don’t you love lists? I love lists. They’re so nice and tidy, like a RegEx. Just the other night I was thinking how nice it’d be to write a RegeEx to detect RegEx patterns.
I didn’t sleep.
Anyway, SQL Server. Things. Things running slowly. What’s up with that?
In these posts, I’ll walk through some common scenarios, and how to look for them.
It might even be in the EXACT SAME VERY ORDER I LOOK FOR THEM!
Put your money away.
Reason 1: The Server Is Overloaded
If you go to open a new tab in SSMS and you hear a creaking sound, it might be time to revisit some of your hardware choices.
But that’s a problem for future you. Your problem is right now.
What to look for: Stuck queries, Resource Usage, Wait Stats
By default, it’ll look at both CPU and Memory counters. If you don’t know what’s going on, just hit F5.
EXEC dbo.sp_PressureDetector;
If you’re hitting memory limits, things will look like this:
are you ready?
Some queries will have requested memory, but it won’t have been granted.
payday
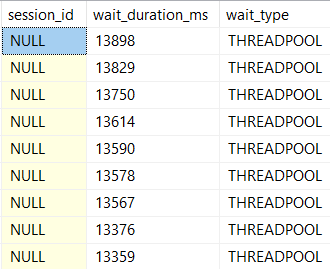
Waiting queries will be stuck in a queue, waiting on RESOURCE_SEMAPHORE.
we’re having a good time
A significant amount of memory will have been granted out, and available memory will be on the lower side. You’ll also probably see the waiter_count column
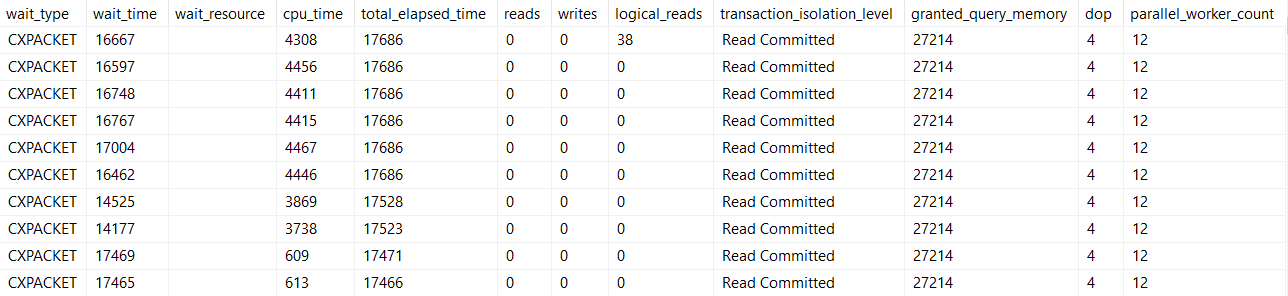
If you’re hitting CPU limits, things will look like this:
negative creep
Available threads might be a negative, or very low number. Requests may be waiting on threads, and the number will pretty closely match the number of rows that are…
bum
Waiting in the pool.
she works hard for the money
This’ll also show you queries that are running, and which ones are using the most threads.
Can You Fix It Quickly?
Maybe, maybe not. If you’re allowed to kill off queries, you might be able to right the ship now. If not, you’re stuck waiting for queries to finish and give back their resources.
Longer term, you have a long checklist to go through, including asking tough questions about hardware, settings memory and parallelism settings, and your queries and indexes. This script will give you a lot of information about what’s going on. It’s up to you to figure out why.
If you need help with this sort of thing, drop me a line.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I think it was Doug Lane who coined the stages of dynamic SQL. One of them dealt with the fact that once you start using it, you just wanna use it everywhere, even places where you think you don’t need it.
Most of the time, you don’t. A parameter is good enough. But like we saw last week, sometimes parameters can backfire, and you can use dynamic SQL to save query performance.
That’s one great use, but it’s one you’re gonna have to use constantly. Most of the time when you’re using dynamic SQL, it’s not going to be to correct performance.
You want to build or use a different string based on some input
You have a statement you want to execute over multiple targets
Your script has to support multiple versions of SQL Server
Of course, one can’t reasonably write about dynamic SQL in SQL Server without linking to Erland. Boy howdy, did I learn most everything I know from him.
I Disconnect From You
One of the big downsides of dynamic SQL is that statements in a stored procedure are no longer associated with that stored procedure in system DMVs.
Of course, you can address this somewhat by adding a comment to the query inside the dynamic SQL:
/*headless*/
DECLARE @super_cool_sql NVARCHAR(MAX) = N'
SELECT *
FROM ALL THE TABLES!
';
/*more headed*/
DECLARE @super_cool_sql NVARCHAR(MAX) = N'
SELECT *
/*super cool procedure name*/
FROM ALL THE TABLES!
';
Where you put the comment is irrelevant, but if it’s a particularly long query, I’d probably want it close to or above the select so it doesn’t get truncated.
But we’re all nice people who don’t write queries with more than 65k characters and spaces in them.
Right? Right.
While it’s nice to know where they came from, they’re not easy to track down because they don’t have a parent object id — they’re rogue agents in the plan cache.
It can also make troubleshooting a stored procedure difficult because it can be a little harder to see which statements did the most work.
You might be conditionally executing certain blocks of dynamic SQL for different reasons
You might be building dynamic where clauses that have different performance profiles
Yes, you can control the flow of logic, but it has no desirable impact on query plan compilation. Everything gets compiled the first time.
Instead of dynamic SQL, though, you could use separate stored procedures, which at least makes the objects a little easier to track down in the plan cache or Query Store.
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
EXEC dbo.VoteCount_InnerBig @VoteTypeId, @YearsBack;
END;
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
EXEC dbo.VoteCount_InnerSmall @VoteTypeId, @YearsBack;
END;
END;
Both of those stored procedures can have the same statement in them, without the ? = (SELECT ?) addition needed with the dynamic SQL option.
That they’re owned by different objects is enough to get them separate optimization paths. You’re also a bit less prone to permissions issues, if you’re the kind of person who takes those seriously. But if your app logs in as db_owner or whatever, well, BOFL with that.
Speaking of which, even though I find security incredibly dull and frustrating, let’s talk a little about how people can take advantage of bad dynamic SQL.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
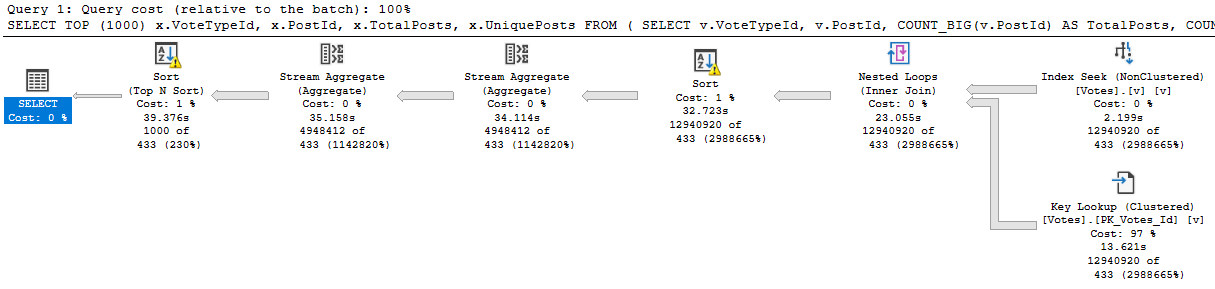
It would certainly be a good candidate for index changes though, because the first thing we need to address is that key lookup.
It’s a sensitive issue.
King Index
We’re going to walk through something I talked about what seems like an eternity ago. Why? Because it has practical application here.
When you look at the core part of the query, PostId is only in the select list. Most advice around key lookups (including, generally, my own) is to consider putting columns only in the output into the includes of the index.
and that’s where this is
But we’re in a slightly different situation, here.
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
We’re getting a distinct count, and SQL Server has some choices for coming up with that.
If we follow the general advice here and create this index, we’ll end up in trouble:
CREATE INDEX v
ON dbo.Votes(VoteTypeId, CreationDate) INCLUDE(PostId)
WITH (DROP_EXISTING = ON);
growling intensifies
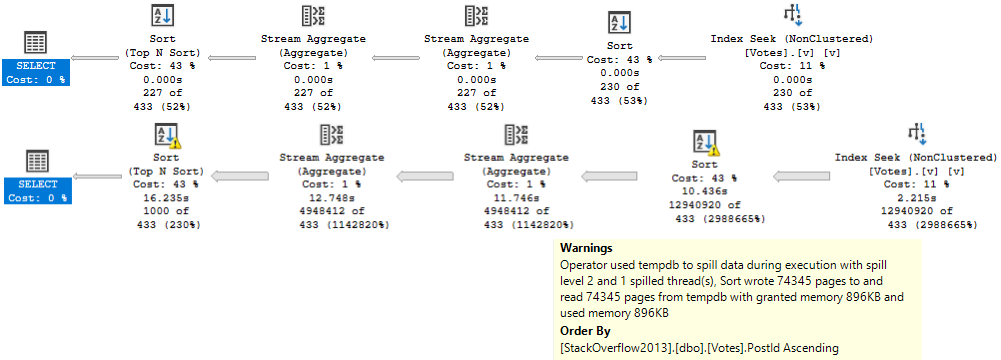
Since the Stream Aggregate expects ordered data, and PostId isn’t in order in the index (because includes aren’t in any particular order), we need to sort it. For a small amount of data, that’s fine. For a large amount of data, it’s not.
There is a second Sort in the plan further down, but it’s on the count expression, which means we can’t index it without adding in additional objects, like an indexed view.
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts, -- this is the expression
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC; -- this is the ordering
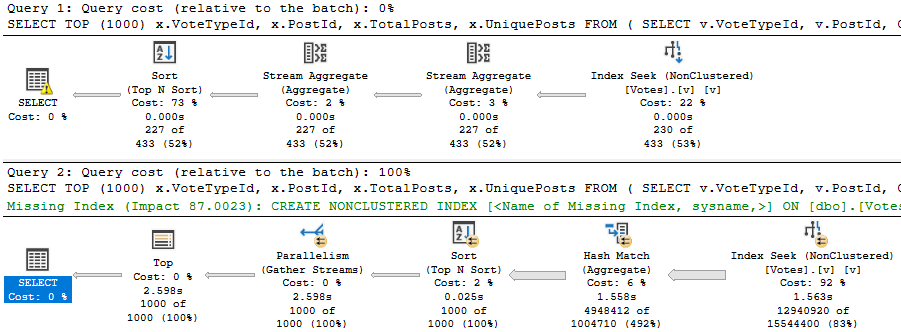
What’s An Index To A Non-Believer?
A better index in this case looks like this:
CREATE INDEX v
ON dbo.Votes(VoteTypeId, PostId, CreationDate)
WITH (DROP_EXISTING = ON);
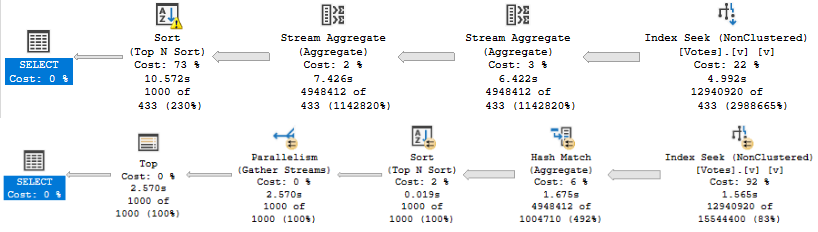
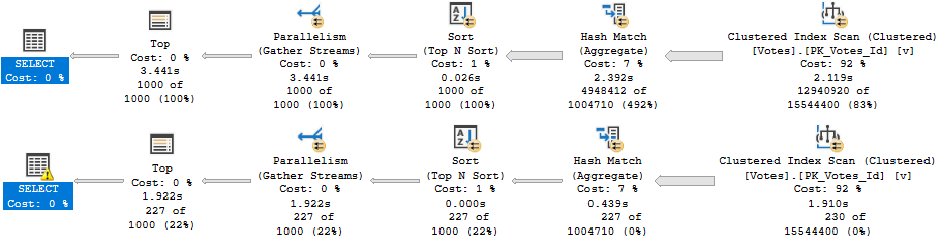
It will shave about 6 seconds off the run time, but there’s still a problem when the “big” data doesn’t go parallel:
big data differences
When the plan goes parallel, it’s about 4x faster than the serial version. Now I know what you’re thinking, here. We could use OPTIMIZE FOR to always get the plan for the big value. And that’s not a horrible idea — the small data parameter runs very quickly re-using the parallel plan here — but there’s another way.
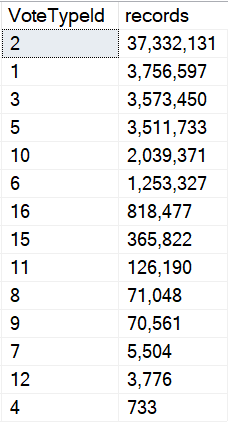
Let’s look at our data.
Don’t Just Stare At It
Let’s draw an arbitrary line. I think a million is a popular number. I wish it was a popular number in my bank account, but you know.
unwritten law
I know we’re ignoring the date column data, but this is good enough for now. There’s only so much I can squeeze into one blog post.
The point here is that we’re going to say that anything under a million rows is okay with using the small plan, and anything over a million rows needs the big plan.
Sure, we might need to refine that later if there are outliers within those two groups, but this is a blog post.
How do we do that? We go dynamic.
Behike 54
Plan ol’ IF branches plan ol’ don’t work. We need something to get two distinct plans that are re-usable.
Here’s the full procedure:
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
/*dbo.VoteCount*/
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), ''2014-01-01'')
AND v.VoteTypeId = @VoteTypeId '
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
SET @sql += N'
AND 1 = (SELECT 1)'
END
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
SET @sql += N'
AND 2 = (SELECT 2)'
END
SET @sql += N'
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC;
';
RAISERROR('%s', 0, 1, @sql) WITH NOWAIT;
EXEC sys.sp_executesql @sql,
N'@VoteTypeId INT, @YearsBack INT',
@VoteTypeId, @YearsBack;
END;
There’s a bit going on in there, but the important part is in the middle. This is what will give use different execution plans.
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
SET @sql += N'
AND 1 = (SELECT 1)'
END
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
SET @sql += N'
AND 2 = (SELECT 2)'
END
Sure, there are other ways to do this. You could even selectively recompile if you wanted to. But some people complain when you recompile. It’s cheating.
Because the SQL Server Query Optimizer typically selects the best execution plan for a query, we recommend only using hints as a last resort for experienced developers and database administrators.
See? It’s even documented.
Now that we’ve got that all worked out, we can run the proc and get the right plan depending on the amount of data we need to shuffle around.
strangers in the night
Little Star
Now I know what you’re thinking. You wanna know more about that dynamic SQL. You want to solve performance problems and have happy endings.
We’ll do that next week, where I’ll talk about common issues, best practices, and more tricks you can use to get queries to perform better with it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are lots of different ways that parameter sniffing can manifest in both the operators chosen, the order of operators chosen, and the resources acquired by a query when a plan is compiled. At least in my day-to-day consulting, one of the most common reasons for plans being disagreeable is around insufficient indexes.
One way to fix the issue is to fix the index. We’ll talk about a way to do it without touching the indexes tomorrow.
Let’s say we have this index to start with. Maybe it was good for another query, and no one ever thought twice about it. After all, you rebuild your indexes every night, what other attention could they possible need?
CREATE INDEX v
ON dbo.Votes(VoteTypeId, CreationDate);
If we had a query with a where clause on those two columns, it’d be be able to find data pretty efficiently.
But how much data will it find? How many of each VoteTypeId are there? What range of dates are we looking for?
Well, that depends on our parameters.
Cookie Cookie
Here’s our stored procedure. There’s one column in it that isn’t in our index. What a bummer.
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC;
END;
That doesn’t matter for a small amount of data, whether it’s encountered because of the parameters used, or the size of the data the procedure is developed and tested against. Testing against unrealistic data is a recipe for disaster, of course.
Cookie Cookie
What can be tricky is that if the sniffing is occurring with the lookup plan, the optimizer won’t think enough of it to request a covering index, either in plan or in the index DMVs. It’s something you’ll have to figure out on your own.
i said me toooh yeah that
So we need to add that to the index, but where? That’s an interesting question, and we’ll answer it in tomorrow’s post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Alright, maybe not any database. Let’s stick with SQL Server. That’s the devil we know.
At some point in your life, you’re going to construct a query that takes user input, and that input is likely going to come in the form of a parameter.
It could be a stored procedure, dynamic SQL, or something from your application. But there it is.
Waiting. Watching.
Sniffing.
Defining A Problem
When we use parameters, we re-use execution plans, at least until a Qualifying Event™ occurs.
What’s a qualifying event?
Recompile hint
Stats update
Temp table modification threshold
Plan eviction
Server restart
Now, it might be reasonable to think that a mature optimizer — and it is an optimizer, not just a planner — would be able to do something a bit more optimal. After all, why would anyone think it would take the same amount of work to get through 100 rows as it would take to get through 1,000,000 rows? It’s a fundamentally different approach.
Doing a run to the grocery store to replenish a few things requires a far different mindset from going to prepare for a large family meal. You have to choose between a basket or a cart, whether you can jump right to the couple spots you need or you need to walk up and down every aisle, and even if you might need to write down a list because it doesn’t fit into brain memory.
One might also have the expectation that if a significant inaccuracy is detected at runtime, the strategy might change. While that does sort of happen with Adaptive Joins, it’s not a full plan rewrite.
Detecting A Problem
The plan cache usually sucks for this, unless you’re saving the data off to more stable tables. Why? Because most people only figure out they’ve been sniffed after a plan changes, which means it’s not in the cache anymore. You know, when end users start complaining, the app goes unresponsive, you can’t connect to the server, etc.
You could set your watch to it.
But sometimes it’s there. Some funny looking little plan that looks quite innocent, but seems to do a lot of work when you bang it up against other DMVs.
If you have the luxury, Query Store is quite a better tool for detecting plan changes. It’s even got reports built in just for that.
how nice of you.
For the extra fancy amongst you, I pray that your expensive monitoring tool has a way to tell you when query plans change, or when normally fast plans deviate from that.
Deciphering A Problem
This is where things can get difficult, unless you’re monitoring or logging information. You typically need a few different combinations of parameter values to feed in to your query, so you can see what changed and when. Quite often, there’s no going back easily.
Let’s say you had a plan, and it was a good plan. Then one of those pesky qualifying events comes along, and it’s decided that you need a new plan.
And what if… that new plan is worse? No matter how much you recompile or update stats or toggle with cardinality estimation, you just can’t go back to the way things were without lots of hints or changes to the query? Maybe that’s not parameter sniffing. Maybe that’s parameter snuffing. I’m gonna copyright that.
Most parameter sniffing will result in a plan with a set of bad choices for different amounts of data, which will result in something like this:
not crafty
This isn’t a “bad estimate” — it was a pretty good estimate for the first parameter value. It just wasn’t a good estimate for the second parameter value.
And to be honest, quite a bit of parameter sniffing issues come from Nested Loops. Not because it’s bad, but because it’s bad for large amount of data, especially in a serial plan. It’s a pretty easy way to gum up a query, though. Make it get stuck in a loop for 13 million rows. It wasn’t fast? No kidding. Poof, be gone.
But then opposite-land isn’t good, either.
like falling, baby
This plan probably makes plenty of sense for a big chunk of data. One big scan, one big hash, one big sort. Done.
Of course, for a small amount of data, we go from taking 1ms to taking 2s. Small amount of data people will likely not be happy with that. Your server might not be either, what with all the extra CPU resources we’re using in this here parallel plan all the time now.
Tomorrow, we’ll look at how sometimes you can fix parameter sniffing with better indexes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Microsoft has chosen some odd things to warn us about in query plans. For estimated and cached plans, I totally understand some of the limitations.
Though the DMVs for queries associated with query plans (both in the plan cache and query store) log some additional metrics about memory grants, spills, CPU, duration, reads, and more, none of that additional information ends up as feedback in the plan XML.
I’m not complaining, either. Modifying XML is stupid.
Bellyachin’
What could be in the XML is an extension of the current set of warnings, with maybe a bit more in Actual plans.
Query plans could warn if:
A non-SARGable predicate caused a scan
A non-SARGable/complex predicate caused a Filter
A residual predicate did a lot of reads
Eager Index Spools are over a certain number of rows
Performance Spools have an unfavorable rebind/rewind ratio
Louder warnings for when something forces a query to run serially
Show multiple missing index requests when present
When operators execute more than once
When a statistic used has significant modifications
A roll up of per-operator I/O at the root node
Many of these things could be in both estimated and actual plans, and would really help people understand both why the things they do when writing queries can mess them up, and also when there might be a better way to do things.
A Professional With Standards
Is that a lot of stuff? Yes. But think about the warnings we get now, and the last time they were really helpful to you.
If they ever were, I can guarantee that they’ve been misleading more often.
All in all, people need a more informative query plan, and building this sort of instrumentation for end users also gives the robots in Azure, and future Intelligent Query Processing features some nice feedback.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Whenever I’ve needed to figure something out to query the plan cache, or when I’ve been looking for stuff that might be interesting to pull out of it, this is where I’ve gone.
Especially when plan XML, it helps me rest a bit easier to know I’ve covered all the documented possibilities.
Of course, there’s no distinction in the documentation between what can be in the Estimated plan, and what’s reserved for Actual plans.
Such Document
While that’s inconvenient, you can figure most things out by separating plan elements into two groups:
Optimization time metrics
Runtime metrics
Here are the documented warnings available in query plans.
what was the robot’s name?
Things like spills and memory usage can only be known at runtime, when the optimizer’s estimates are put into play.
For many other things, the optimizer likely knows about and has to account for the warnings while it’s coming up with a query plan.
Warnings About Warnings
One thing to keep in mind about many of these warnings, whether they’re optimization-time or run-time, is that they’re trigger for things that might not matter, or even necessarily be true.
But I do want you to reinforce a couple points I’ve made over the course of the series:
Estimated and cached plans miss details that make troubleshooting easier
Not every metric and warning is a critical datapoint
For example, I’ve seen people focus on small spills in execution plans many times only to have them not be the cause of a performance problem.
Operator times make distinguishing this easier, of course. Prior to that, even actual plans could be misleading and unforgiving.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Most of the time when the optimizer thinks an index will make a big enough difference, it’ll tell you.
Sure, it’s not perfect, but it can get you where you’re going fast enough. If you’re relying on that sort of feedback in query plans, or in the missing index DMVs, you’ll hate this.
Not only does SQL Server create an index for you, it doesn’t really tell you about it. There’s no loud warning here.
It also throws that index away when the query is done executing. It only exists in tempdb while the query executes, and it’s only available to the query that builds it.
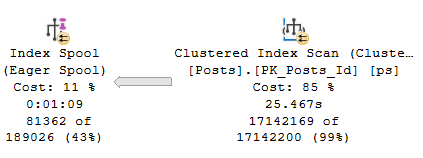
And boy, they sure can take a long time to build.
tick tock
Let’s take a closer look!
Skidding Out
Eager index spools can occur on the inner side of Nested Loops joins to reduce the amount of work that needs to be done there, by creating a more opportune index for the loop to work off of.
That all sounds very good, but there are some problems:
The index gets created single-threaded
The way data is loaded into the spool is very inefficient
The spool is disposed of when the query is finished,
It’ll get built over and over again on later executions
There’s no missing index request for the spool anywhere
I’m not suggesting that the query would be faster without the spool. Reliable sources tell me that this thing runs for over 6 hours without it. My suggestion is that when you see Eager Index spools, you should pay close attention.
Let’s talk about how you can do that.
Mountainous
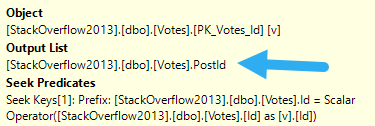
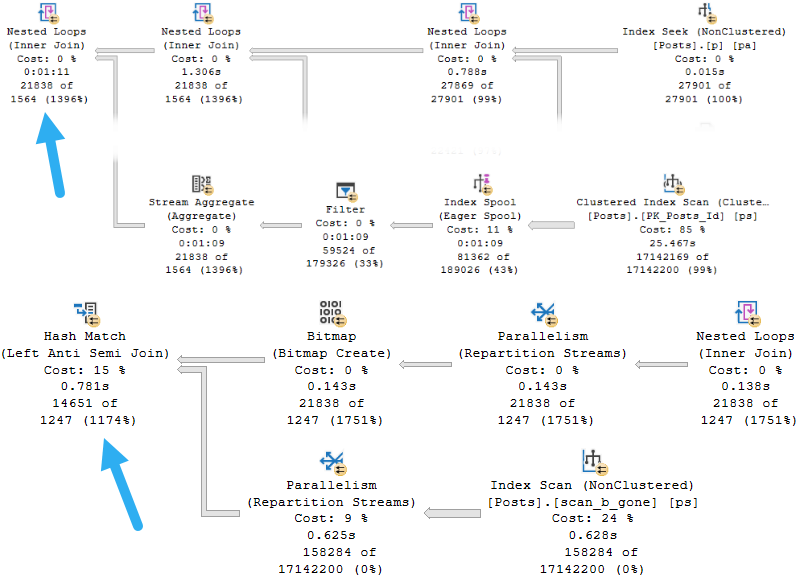
In some cases, your only option is to look at the Eager Index Spool to see what it’s doing, and create an index on your own to mimic it.
If you’re the kind of person who likes free scripts, sp_BlitzCache will look for Eager Index Spools in your query plans and do that for you. You’re welcome.
If you’re a more manual type, here’s what you do: Look at the Eager Index Spool.
ham ham ham ham
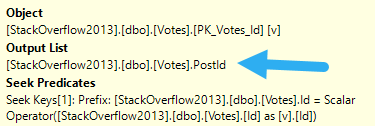
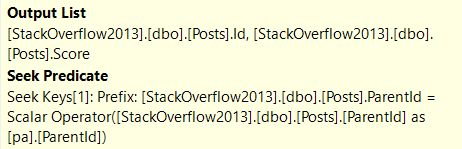
The Seek Predicate(s) are they key columns, and the Output List is the included columns.
CREATE INDEX spool_b_gone
ON dbo.Posts(ParentId) INCLUDE (Score);
Since the Id column is the clustered index, we don’t explicitly need it in the index definition — remember that nonclustered indexes inherit them. It’ll end up as a “hidden” key column, after all.
Human Touch
In most cases, this will be good enough. The performance difference will be night and day, if the build source for the Eager Index Spool was fairly large, or if your query built the same Eager Index Spool multiple times.
Though just like missing index requests, Eager Index Spools don’t always come up with the *best* index.
Thinking through our query, we may want to move Score up to the key of the index.
SELECT pq.OwnerUserId, pq.Score, pq.Title, pq.CreationDate,
pa.OwnerUserId, pa.Score, pa.CreationDate
FROM dbo.Posts AS pa
INNER JOIN dbo.Posts AS pq
ON pq.Id = pa.ParentId
WHERE pq.PostTypeId = 1
AND pq.CommunityOwnedDate IS NULL
AND pq.AnswerCount > 1
AND pa.PostTypeId = 2
AND pa.OwnerUserId = 22656
AND pa.Score >
(
SELECT MAX(ps.Score)
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.Id <> pa.Id
)
ORDER BY pq.Id;
See that subquery at the very end, where we’re aggregating on Score? Having Score in the key of the index will put the data in order, which makes a Stream Aggregate pretty painless. Remember that Stream Aggregates expect sorted input.
That’s, like, how they stream.
CREATE INDEX spool_b_gone
ON dbo.Posts(ParentId, Score);
Letter To The Query Editor
There are some cases where changing a query is a lot less painful than changing or adding indexes.
You might already have a lot of indexes, or you might have a really big table, or you might be on Standard Edition, which is a lot like being on one of those airplanes where the entire thing is economy class.
In this case, we can rewrite the query in a way that avoids the Eager Index Spool entirely:
SELECT pq.OwnerUserId, pq.Score, pq.Title, pq.CreationDate,
pa.OwnerUserId, pa.Score, pa.CreationDate
FROM dbo.Posts AS pa
INNER JOIN dbo.Posts AS pq
ON pq.Id = pa.ParentId
WHERE pq.PostTypeId = 1
AND pq.CommunityOwnedDate IS NULL
AND pq.AnswerCount > 1
AND pa.PostTypeId = 2
AND pa.OwnerUserId = 22656
AND NOT EXISTS
(
SELECT 1/0
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.Id <> pa.Id
AND ps.Score >= pa.Score
)
ORDER BY pq.Id;
Which gets us a different plan. And you can see why we’d want one.
spoolishness
Avoiding the need for an Eager Index Spool reduces the query time from over a minute to under a second.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.