In the documentation for TOP, the following is listed as a best practice:
In a SELECT statement, always use an ORDER BY clause with the TOP clause. Because, it’s the only way to predictably indicate which rows are affected by TOP.
Let’s work through a real world example.
The good
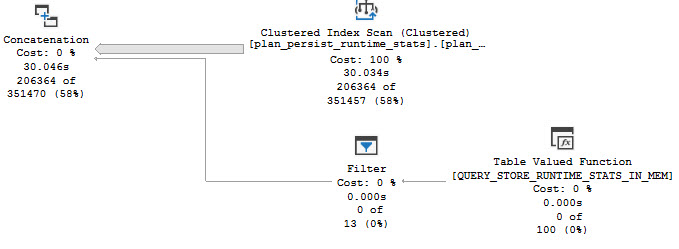
One of the great things about the “Top Resource Consuming Queries” query store SSMS report is that it is always able to render the query plan, even for very complex queries. I’m not aware of a pure T-SQL solution that can avoid requiring the end user to save xml to files in all cases. The report nearly always takes a long time to run, so it’s easy to capture the T-SQL that powers the grid details version:
DECLARE @results_row_count INT = 100,
@interval_start_time DATETIMEOFFSET = '2019-05-24 15:30:00 +00:00',
@interval_end_time DATETIMEOFFSET = '2019-05-24 18:00:00 +00:00';
SELECT TOP (@results_row_count)
p.query_id query_id,
q.object_id object_id,
ISNULL(OBJECT_NAME(q.object_id),'') object_name,
qt.query_sql_text query_sql_text,
ROUND(CONVERT(float, SUM(rs.avg_duration*rs.count_executions))*0.001,2) total_duration,
SUM(rs.count_executions) count_executions,
COUNT(distinct p.plan_id) num_plans
FROM sys.query_store_runtime_stats rs
JOIN sys.query_store_plan p ON p.plan_id = rs.plan_id
JOIN sys.query_store_query q ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
WHERE NOT (rs.first_execution_time > @interval_end_time OR rs.last_execution_time < @interval_start_time)
GROUP BY p.query_id, qt.query_sql_text, q.object_id
HAVING COUNT(distinct p.plan_id) >= 1
ORDER BY total_duration DESC;
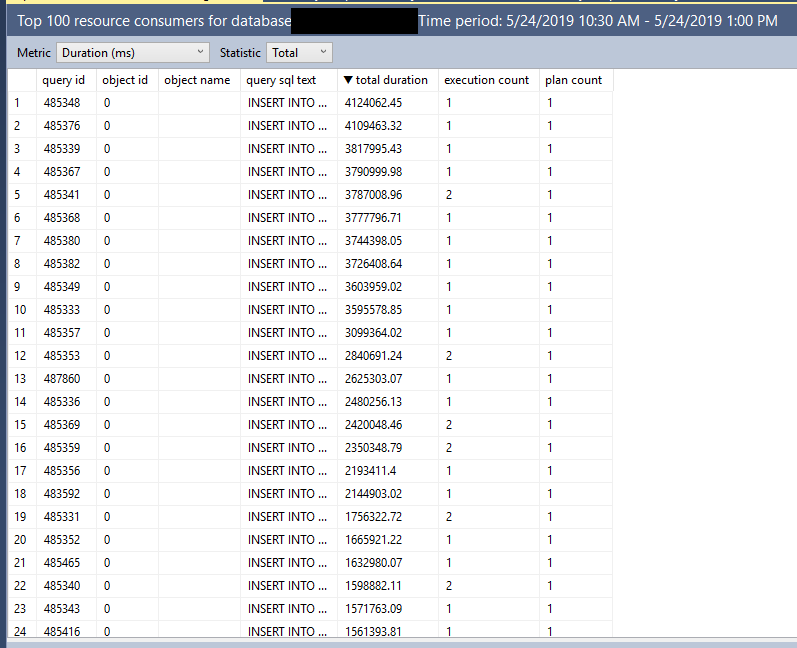
Note the presence of the ORDER BY. I get exactly the results that I was expecting:
The bad
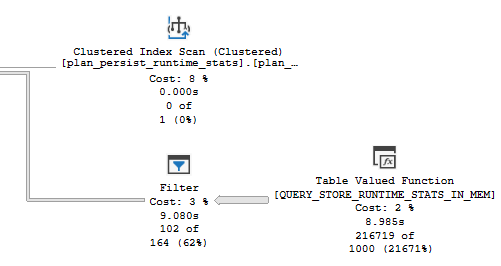
If I ask for extra details (who doesn’t want more details?), a significantly more complex query is generated:
-- grid format query with additional details
-- grid format query with additional details
DECLARE @results_row_count INT = 100,
@interval_start_time DATETIMEOFFSET = '2019-05-24 15:30:00 +00:00',
@interval_end_time DATETIMEOFFSET = '2019-05-24 18:00:00 +00:00';
With wait_stats AS
(
SELECT
ws.plan_id plan_id,
ws.execution_type,
ROUND(CONVERT(float, SUM(ws.total_query_wait_time_ms)/SUM(ws.total_query_wait_time_ms/ws.avg_query_wait_time_ms))*1,2) avg_query_wait_time,
ROUND(CONVERT(float, SQRT( SUM(ws.stdev_query_wait_time_ms*ws.stdev_query_wait_time_ms*(ws.total_query_wait_time_ms/ws.avg_query_wait_time_ms))/SUM(ws.total_query_wait_time_ms/ws.avg_query_wait_time_ms)))*1,2) stdev_query_wait_time,
CAST(ROUND(SUM(ws.total_query_wait_time_ms/ws.avg_query_wait_time_ms),0) AS BIGINT) count_executions,
MAX(itvl.end_time) last_execution_time,
MIN(itvl.start_time) first_execution_time
FROM sys.query_store_wait_stats ws
JOIN sys.query_store_runtime_stats_interval itvl ON itvl.runtime_stats_interval_id = ws.runtime_stats_interval_id
WHERE NOT (itvl.start_time > @interval_end_time OR itvl.end_time < @interval_start_time)
GROUP BY ws.plan_id, ws.runtime_stats_interval_id, ws.execution_type ),
top_wait_stats AS
(
SELECT TOP (@results_row_count)
p.query_id query_id,
q.object_id object_id,
ISNULL(OBJECT_NAME(q.object_id),'') object_name,
qt.query_sql_text query_sql_text,
ROUND(CONVERT(float, SUM(ws.avg_query_wait_time*ws.count_executions))*1,2) total_query_wait_time,
SUM(ws.count_executions) count_executions,
COUNT(distinct p.plan_id) num_plans
FROM wait_stats ws
JOIN sys.query_store_plan p ON p.plan_id = ws.plan_id
JOIN sys.query_store_query q ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
WHERE NOT (ws.first_execution_time > @interval_end_time OR ws.last_execution_time < @interval_start_time)
GROUP BY p.query_id, qt.query_sql_text, q.object_id
),
top_other_stats AS
(
SELECT TOP (@results_row_count)
p.query_id query_id,
q.object_id object_id,
ISNULL(OBJECT_NAME(q.object_id),'') object_name,
qt.query_sql_text query_sql_text,
ROUND(CONVERT(float, SUM(rs.avg_duration*rs.count_executions))*0.001,2) total_duration,
ROUND(CONVERT(float, SUM(rs.avg_cpu_time*rs.count_executions))*0.001,2) total_cpu_time,
ROUND(CONVERT(float, SUM(rs.avg_logical_io_reads*rs.count_executions))*8,2) total_logical_io_reads,
ROUND(CONVERT(float, SUM(rs.avg_logical_io_writes*rs.count_executions))*8,2) total_logical_io_writes,
ROUND(CONVERT(float, SUM(rs.avg_physical_io_reads*rs.count_executions))*8,2) total_physical_io_reads,
ROUND(CONVERT(float, SUM(rs.avg_clr_time*rs.count_executions))*0.001,2) total_clr_time,
ROUND(CONVERT(float, SUM(rs.avg_dop*rs.count_executions))*1,0) total_dop,
ROUND(CONVERT(float, SUM(rs.avg_query_max_used_memory*rs.count_executions))*8,2) total_query_max_used_memory,
ROUND(CONVERT(float, SUM(rs.avg_rowcount*rs.count_executions))*1,0) total_rowcount,
ROUND(CONVERT(float, SUM(rs.avg_log_bytes_used*rs.count_executions))*0.0009765625,2) total_log_bytes_used,
ROUND(CONVERT(float, SUM(rs.avg_tempdb_space_used*rs.count_executions))*8,2) total_tempdb_space_used,
SUM(rs.count_executions) count_executions,
COUNT(distinct p.plan_id) num_plans
FROM sys.query_store_runtime_stats rs
JOIN sys.query_store_plan p ON p.plan_id = rs.plan_id
JOIN sys.query_store_query q ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
WHERE NOT (rs.first_execution_time > @interval_end_time OR rs.last_execution_time < @interval_start_time)
GROUP BY p.query_id, qt.query_sql_text, q.object_id
)
SELECT TOP (@results_row_count)
A.query_id query_id,
A.object_id object_id,
A.object_name object_name,
A.query_sql_text query_sql_text,
A.total_duration total_duration,
A.total_cpu_time total_cpu_time,
A.total_logical_io_reads total_logical_io_reads,
A.total_logical_io_writes total_logical_io_writes,
A.total_physical_io_reads total_physical_io_reads,
A.total_clr_time total_clr_time,
A.total_dop total_dop,
A.total_query_max_used_memory total_query_max_used_memory,
A.total_rowcount total_rowcount,
A.total_log_bytes_used total_log_bytes_used,
A.total_tempdb_space_used total_tempdb_space_used,
ISNULL(B.total_query_wait_time,0) total_query_wait_time,
A.count_executions count_executions,
A.num_plans num_plans
FROM top_other_stats A LEFT JOIN top_wait_stats B on A.query_id = B.query_id and A.query_sql_text = B.query_sql_text and A.object_id = B.object_id
WHERE A.num_plans >= 1
ORDER BY total_duration DESC
)
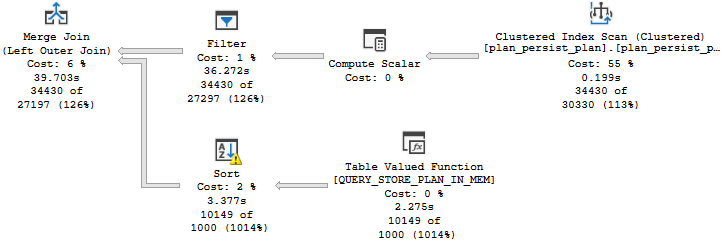
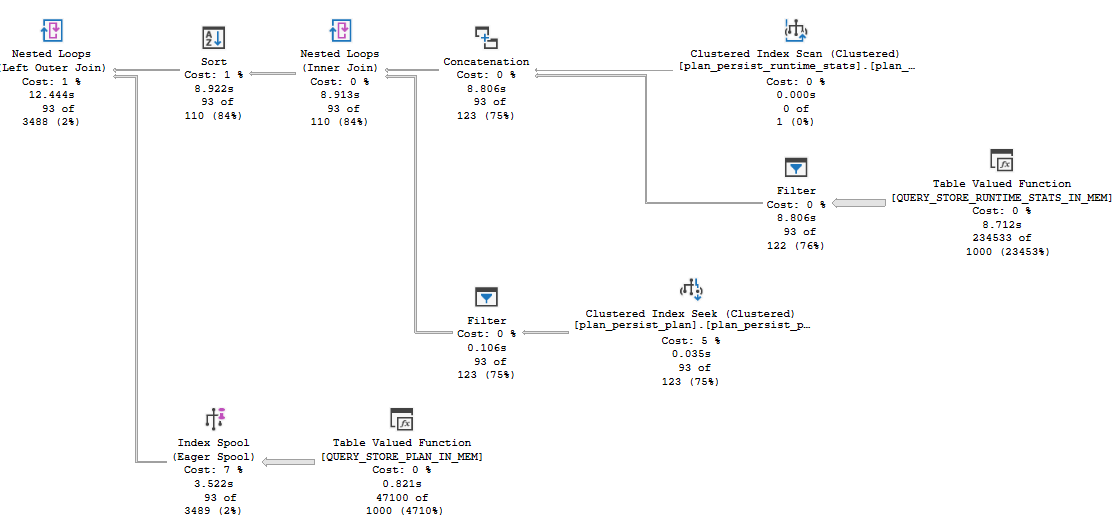
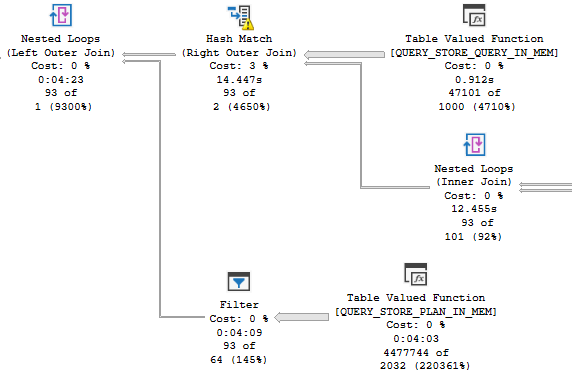
Now we have not 1, not 2, but THREE TOP operators! But only one of them has an ORDER BY. The results are completely different, and are pretty much useless:
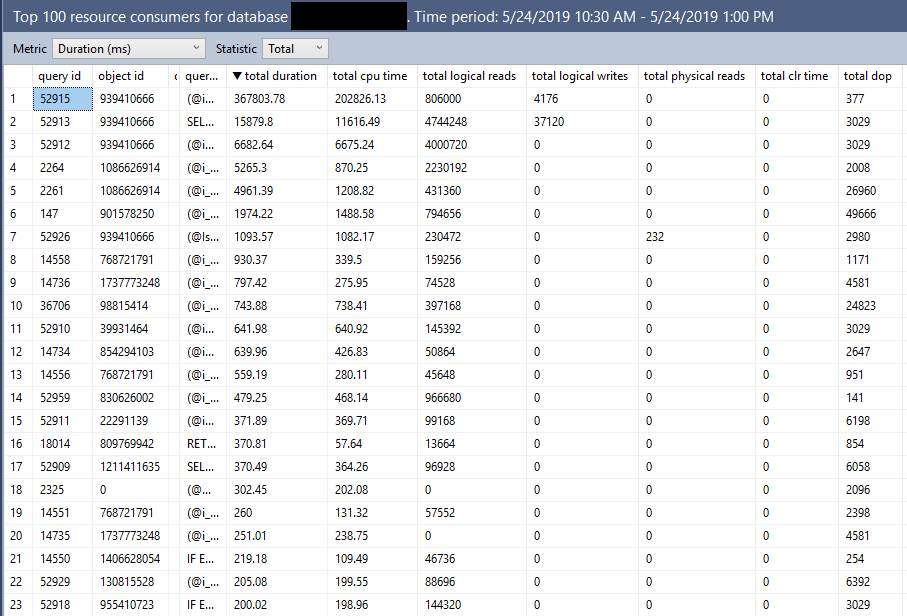
The ugly
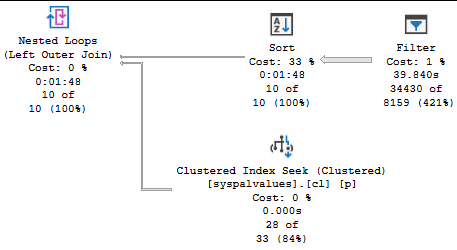
This has nothing to do with TOP as far as I know, but I included it just for fun:
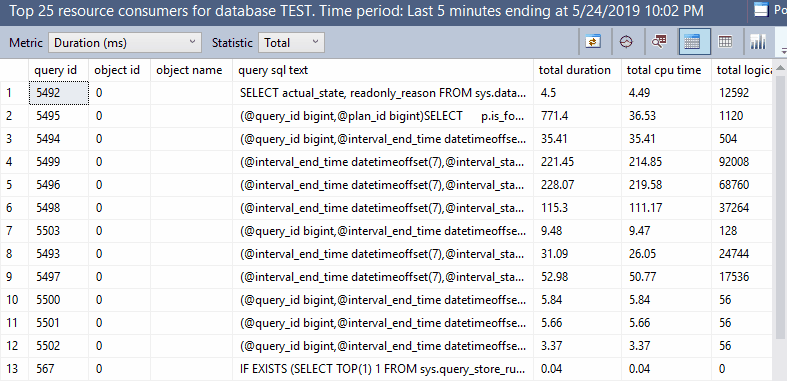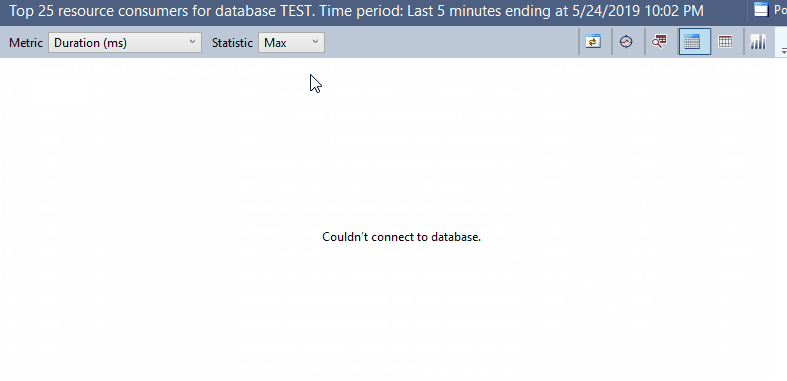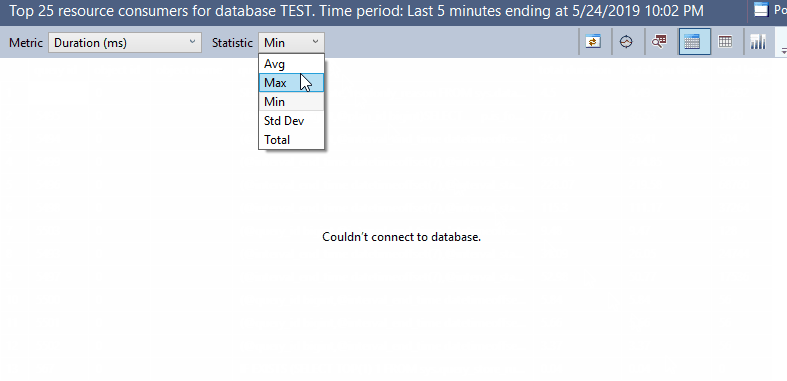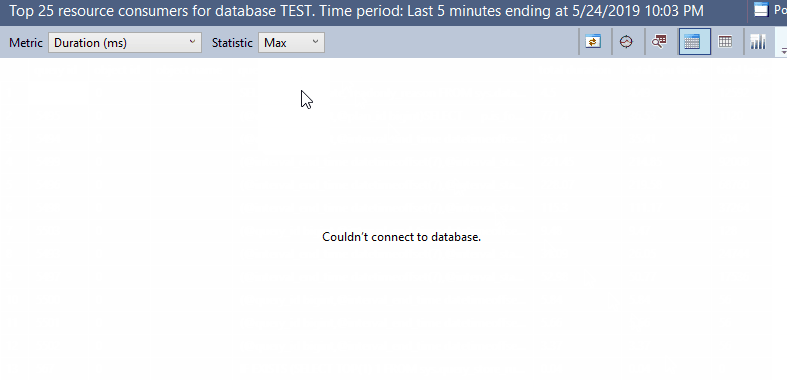
Final thoughts
All of you developers out there should watch your TOPs and make sure you’re using ORDER BY as needed. Otherwise, you might end up with annoyed end users writing blog posts about your code.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.