Classico
In the bad old days, which are still your days (but at least you have better days to look forward to), SQL Server’s cost-based optimizer would take a parametrized query, come up with a query plan, and then reuse that plan until:
- Plan cache clearing event
- Plan evicting event
There are a bunch of reasons for those things. They’re not important here.
What is important is the future, where SQL Server will have some more options for getting out of parameter sensitive jams.
I talked about a somewhat related feature called Cardinality Estimation Feedback here. This is a different beast, though.
While Cardinality Estimation Feedback is a between-executions like Memory Grant Feedback, the Parameter Sensitive Plan feature is a heuristic runtime decision, sort of like Adaptive Joins and Batch Mode On Row Store.
Like most things, you’ll need to be in the latest compatibility level, 160, and… it hasn’t been announced yet, but traditionally things like this are Enterprise Only.
Time will tell.
Shellac
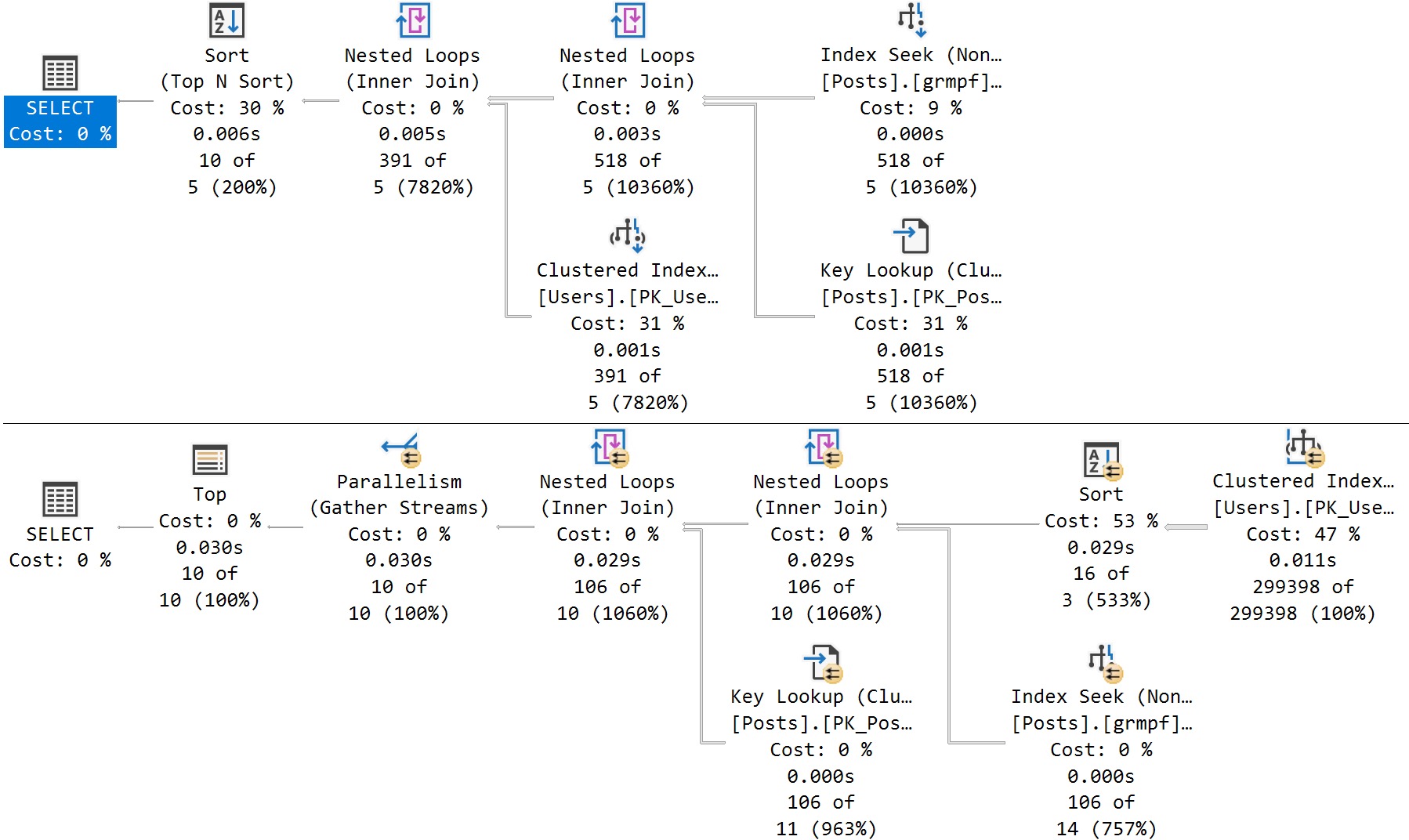
The way this feature works is, rather than caching a single query plan for every other execution to use, it creates what’s called a Dispatcher plan (if your query qualifies).
You’ll see something like this in the properties of the root node of your query plan, and your query will have some additional funny business at the end of it.

And that other thing:
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION
(
PLAN PER VALUE
(
QueryVariantID = 3,
predicate_range
(
[StackOverflow2013].[dbo].[Posts].[ParentId] = @ParentId,
100.0,
1000000.0
)
)
)
Note that I formatted the option part of the query a bit to make it a bit more likable (to me).
The basic message here is that for the @ParentId parameter, there are three plan variants (the limit currently), and this is the third one.
There are also a couple numbers there that indicate the upper and lower bounds for bucketizing the three plan variants.
S/M/L
The basic idea here is to generate small, medium, and large plans for different cardinality estimation ranges.
Most of the examples I’ve been able to come up with have only generated two plans, one for the very low end, and one for the very high end.
As far as I can tell, the limitations for this feature seem to be:
- Only for a single parameter predicate
- The predicate has to be an equality
- You only get three plan choices
- At present, it disassociates queries from the procedures that they live in
In tomorrow’s post, we’ll look at some of the Extended Events attached to this feature that give you some insights into when the feature kicks in, when it doesn’t, and what SQL Server thought about how sensitive your query is.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.