When I was checking out early builds of SQL Server 2019, I noticed a new DMV called dm_db_missing_index_group_stats_query, that I thought was pretty cool.
It helped you tie missing index requests to the queries that requested them. Previously, that took a whole lot of heroic effort, or luck.
With this new DMV, it’s possible to combine queries that look for missing indexes with queries that look for tuning opportunities in the plan cache or in Query Store.
It seems to tie back to dm_db_missing_index_groups, on the index_group_handle column in this DMV joined to the group handle column in the new DMV.
If you’re wondering why I’m not giving you any code samples here, it’s because I’m going to get some stuff built into sp_BlitzIndex to take advantage of it, now that it’s documented.
Special thanks to William Assaf (b|t) for helping to get this done.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I talk to a lot of people about performance tuning. It seems like once someone is close enough to a database for long enough, they’ll have some impression of parameter sniffing. Usually a bad one.
You start to hear some funny stuff over and over again:
We should always recompile
We should always use local variables
We should always recompile and use local variables
Often, even if it means writing unsafe dynamic SQL, people will be afraid to parameterize things.
Between Friends
To some degree, I get it. You’re afraid of incurring some new performance problem.
You’ve had the same mediocre performance for years, and you don’t wanna make something worse.
The thing is, you could be making things a lot better most of the time.
Fewer compiles and recompiles, fewer single-use plans, fewer queries with multiple plans
Avoiding the local variable nonsense is, more often than not, going to get you better performance
A Letter To You
I’m going to tell you something that you’re not going to like, here.
Most of the time when I see a parameter sniffing problem, I see a lot of other problems.
Shabbily written queries, obvious missing indexes, and a whole list of other things.
It’s not that you have a parameter sniffing problem, you have a general negligence problem.
After all, the bad kind of parameter sniffing means that you’ve got variations of a query plan that don’t perform well on variations of parameters.
Once you start taking care of the basics, you’ll find a whole lot less of the problems that keep you up at night.
If that’s the kind of thing you need help with, drop me a line.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Most queries will have a where clause. I’ve seen plenty that don’t. Some of’em have surprised the people who developed them far more than they surprised me.
But let’s start there, because it’s a pretty important factor in how you design your indexes. There are all sorts of things that indexes can help, but the first thing we want indexes to do in general is help us locate data.
Why? Because the easier we can locate data, the easier we can eliminate rows early on in the query plan. I’m not saying we always need to have an index seek, but we generally want to filter out rows we don’t care about when we’re touching the table they’re in.
Burdens
When we carry excess rows throughout the query plan, all sorts of things get impacted and can become less efficient. This goes hand in hand with cardinality estimation.
At the most severe, rows can’t be filtered when we touch tables, or even join them together, and we have to filter them out later.
Equality predicates preserve ordering of other key columns in the index, which may or may not become important depending on what your query needs to accomplish.
Post Where
After the where clause, there are some rather uncontroversial things that indexes can help with:
When you’re trying to figure out a good index for one query, you usually want to start with the where clause.
Not always, but it makes sense in most cases because it’s where you can find gains in efficiency.
If your index doesn’t support your where clause, you’re gonna see an index scan and freak out and go in search of your local seppuku parlor.
After that, look to other parts of your query that could help you eliminate rows. Joins are an obvious choice, and typically make good candidates for index key columns.
At this point, your query might be in good enough shape, and you can leave other things alone.
If so, great! You can make the check out to cache. I mean cash.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Part of reviewing any server necessarily includes reviewing indexes. When you’re working through things that matter, like unused indexes, duplicative indexes, heaps, etc. it’s pretty clear cut what you should do to fix them.
Missing indexes are a different animal though. You have three general metrics to consider with them:
Uses: the number of times a query could have used the index
Impact: how much the optimizer thinks it can reduce the cost of the query by
Query cost: How much the optimizer estimates the query will cost to run
Of those metrics, impact and query cost are entirely theoretical. I’ve written quite a bit about query costing and how it can be misleading. If you really wanna get into it, you can watch the whole series here.
In short: you might have very expensive queries that finish very quickly, and you might have very low cost queries that finish very slowly.
Especially in cases of parameter sniffing, a query plan with a very low cost might get compiled and generate a missing index request. What happens if every other execution of that query re-uses the cheaply-costed plan and runs for a very long time?
You might have a missing index request that looks insignificant.
Likewise, impact is how much the optimizer thinks it can reduce the cost of the current plan by. Often, you’ll create a new index and get a totally different plan. That plan may be more or less expensive that the previous plan. It’s all a duck hunt.
The most reliable of those three metrics is uses. I’m not saying it’s perfect, but there’s a bit less Urkeling there.
When you’re looking at missing index requests, don’t discount those with lots of uses for low cost queries. Often, they’re more important than they look.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
USE StackOverflow;
EXEC dbo.DropIndexes;
/*
CREATE INDEX east
ON dbo.Posts
(PostTypeId, Score, OwnerUserId)
WITH ( MAXDOP = 8,
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = ROW );
*/
DROP TABLE IF EXISTS #t;
GO
SELECT
u.Id,
u.Reputation,
u.DisplayName,
p.Id AS PostId,
p.Title
INTO #t
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE u.Reputation >= 1000
AND p.PostTypeId = 1
AND p.Score >= 1000
ORDER BY u.Reputation DESC;
/*
CREATE INDEX east
ON dbo.Posts(PostTypeId, Score, OwnerUserId);
*/
SELECT
t.Id,
t.Reputation,
(
SELECT
MAX(p.Score)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = t.Id
AND p.PostTypeId IN (1, 2)
) AS TopPostScore,
t.PostId,
t.Title
FROM #t AS t
ORDER BY t.Reputation DESC;
/*
Usually I love replacing select
list subqueries with APPLY
Just show the saved plan here
*/
SELECT
t.Id,
t.Reputation,
pq.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --We have to use outer apply to not restrict results!
(
SELECT
MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = t.Id
AND p.PostTypeId IN (1, 2)
) AS pq
ORDER BY t.Reputation DESC;
/*
TOP (1) also spools
*/
SELECT
t.Id,
t.Reputation,
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS TopPostScore,
t.PostId,
t.Title
FROM #t AS t
ORDER BY t.Reputation DESC;
SELECT
t.Id,
t.Reputation,
pq.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq
ORDER BY t.Reputation DESC;
/*
CREATE INDEX east
ON dbo.Posts(PostTypeId, Score, OwnerUserId);
*/
SELECT
t.Id,
t.Reputation,
pq.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --This one is fast
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq
ORDER BY t.Reputation DESC;
SELECT
t.Id,
t.Reputation,
pa.Score,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --This two is slow...
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pa
ORDER BY t.Reputation DESC;
/*
Use the Score!
*/
SELECT
t.Id,
t.Reputation,
ISNULL(pa.Score, pq.Score) AS TopPostScore,
t.PostId,
t.Title
FROM #t AS t
OUTER APPLY --This one is fast
(
SELECT TOP (1)
p.Score --Let's get the top score here
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq
OUTER APPLY --This two is slow...
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = t.Id
AND pq.Score < p.Score --Then use it as a filter down here
ORDER BY p.Score DESC
) AS pa
ORDER BY t.Reputation DESC;
SELECT
t.Id,
t.Reputation,
ISNULL(pq.Score, 0) AS Score,
t.PostId,
t.Title
INTO #t2
FROM #t AS t
OUTER APPLY --This one is fast
(
SELECT TOP (1)
p.Score --Let's get the top score here
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.OwnerUserId = t.Id
ORDER BY p.Score DESC
) AS pq;
SELECT
t.Id,
t.Reputation,
ISNULL(pa.Score, t.Score) AS TopPostScore,
t.PostId,
t.Title
FROM #t2 AS t
OUTER APPLY
(
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.OwnerUserId = t.Id
AND t.Score < p.Score --Then use it as a filter down here
ORDER BY p.Score DESC
) AS pa
ORDER BY t.Reputation DESC;
/*
What happened?
* Index key column order
* (PostTypeId, Score, OwnerUserId)
Other things we could try:
* Shuffling index key order, or creating a new index
* (PostTypeId, OwnerUserId, Score)
* Rewriting the query to use ROW_NUMBER() instead
* Have to be really careful here, probably use Batch Mode
*/
/*
CREATE TABLE dbo.t
(
id int NOT NULL,
INDEX c CLUSTERED COLUMNSTORE
);
*/
SELECT
t.Id,
t.Reputation,
pa.Score,
t.PostId,
t.Title
FROM #t AS t
LEFT JOIN dbo.t AS tt ON 1 = 0
OUTER APPLY
(
SELECT
rn.*
FROM
(
SELECT
p.*,
ROW_NUMBER()
OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
) AS n
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
) AS rn
WHERE rn.OwnerUserId = t.Id
AND rn.n = 1
) AS pa
ORDER BY t.Reputation DESC;
DROP TABLE #t, #t2;
Filtered indexes are really interesting things. Just slap a where clause on your index definition, and you can do all sorts of helpful stuff:
Isolate hot data
Make soft delete queries faster
Get a histogram specific to the span of data you care about
Among other things, of course. There are some annoying things about them though.
They only work with specific ANSI options
If you don’t include the filter definition columns in the index, it might not get used
They only work when queries use literals, not parameters or variables
Majorly
Part of the optimizer’s process consists of expression matching, where things like computed columns, filtered indexes, and indexed views are considered for use in your query.
I mean, if you have any of them. If you don’t, it probably just stares inwardly for a few nanoseconds, wondering why you don’t care about it.
Something that this part of the process is terrible at is any sort of “advanced” expression matching. It has to be exact, or you get whacked.
Here’s an example:
DROP TABLE IF EXISTS dbo.is_deleted;
CREATE TABLE dbo.is_deleted
(
id int PRIMARY KEY,
dt datetime NOT NULL,
thing1 varchar(50) NOT NULL,
thing2 varchar(50) NOT NULL,
is_deleted bit NOT NULL
);
INSERT dbo.is_deleted WITH(TABLOCK)
(
id,
dt,
thing1,
thing2,
is_deleted
)
SELECT
x.n,
DATEADD(MINUTE, x.n, GETDATE()),
SUBSTRING(x.text, 0, 50),
SUBSTRING(x.text, 0, 50),
x.n % 2
FROM (
SELECT
ROW_NUMBER() OVER
(
ORDER BY 1/0
) AS n,
m.*
FROM sys.messages AS m
) AS x;
CREATE INDEX isd
ON dbo.is_deleted
(dt)
INCLUDE
(is_deleted)
WHERE
(is_deleted = 0);
Overly
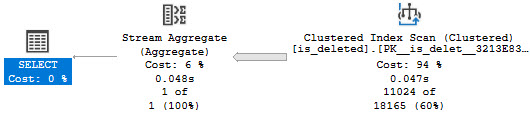
If you run that setup script, you’ll get yourself a table that’s ripe for a filtered index on the is_deleted column.
But it doesn’t work with every type of query pattern. Some people are super fancy and want to find NOTs!
SELECT
COUNT_BIG(*) AS records
FROM dbo.is_deleted AS id
WHERE id.dt >= GETDATE() + 200
AND (NOT 1 = id.is_deleted)
AND 1 = (SELECT 1);
I have the 1 = (SELECT 1) in there for reasons. But we still get no satisfaction.
hurtin
If we try to force the matter, we’ll get an error!
SELECT
COUNT_BIG(*) AS records
FROM dbo.is_deleted AS id WITH(INDEX = isd)
WHERE id.dt >= GETDATE() + 200
AND (NOT 1 = id.is_deleted)
AND 1 = (SELECT 1);
The optimizer says non.
Msg 8622, Level 16, State 1, Line 84
Query processor could not produce a query plan because of the hints defined in this query.
Resubmit the query without specifying any hints and without using SET FORCEPLAN.
It has no problem with this one, though.
SELECT
COUNT_BIG(*) AS records
FROM dbo.is_deleted AS id
WHERE id.dt >= GETDATE() + 200
AND (0 = id.is_deleted)
AND 1 = (SELECT 1);
Underly
It would be nice if there were some more work put into filtered indexes to make them generally more useful.
In much the same way that a general set of contradictions can be detected, simple things like this could be too.
Computed columns have a similar issue, where if the definition is col1 + col2, a query looking at col2 + col1 won’t pick it up.
It’s a darn shame that such potentially powerful tools don’t get much love.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is one of the most frustrating things I’ve seen from the optimizer in quite a while.
Here are a couple tables, with a foreign key between them:
CREATE TABLE dbo.ct(id int PRIMARY KEY, dt datetime);
CREATE TABLE dbo.ct_fk(id int PRIMARY KEY, dt datetime);
ALTER TABLE dbo.ct ADD CONSTRAINT
ct_c_fk FOREIGN KEY (id) REFERENCES dbo.ct_fk(id);
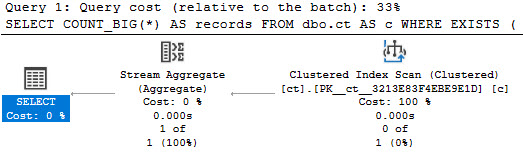
When we use the EXISTS clause, join elimination occurs normally:
SELECT COUNT_BIG(*) AS [?]
FROM dbo.ct AS c
WHERE EXISTS
(
SELECT 1/0
FROM dbo.ct_fk AS cf
WHERE cf.id = c.id
);
all the chickens
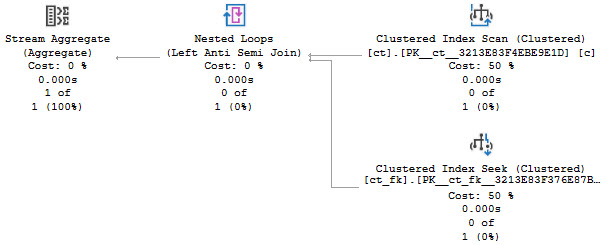
But when we use NOT EXISTS, it… doesn’t.
SELECT COUNT_BIG(*) AS [?]
FROM dbo.ct AS c
WHERE NOT EXISTS
(
SELECT 1/0
FROM dbo.ct_fk AS cf
WHERE cf.id = c.id
);
?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SQL Server comes with some great features for tuning queries:
Computed Columns
Filtered Indexes
Indexed Views
But there’s an interoperability issue when you try to use things together. You can’t create a filtered index with the filter definition on a computed column, nor can you create a filtered index on an indexed view.
If you find yourself backed into a corner, you may need to consider using an indexed view without any aggregation (which is the normal use-case).
Empty Tables
If we try to do something like this, we’ll get an error.
DROP TABLE IF EXISTS dbo.indexed_view;
GO
CREATE TABLE dbo.indexed_view
(
id int PRIMARY KEY,
notfizzbuzz AS (id * 2)
);
GO
CREATE INDEX n
ON dbo.indexed_view (notfizzbuzz)
WHERE notfizzbuzz = 0;
GO
Yes, I’m putting the error message here for SEO bucks.
Msg 10609, Level 16, State 1, Line 19
Filtered index 'nfb' cannot be created on table 'dbo.indexed_view' because the column 'notfizzbuzz' in the filter expression is a computed column.
Rewrite the filter expression so that it does not include this column.
An Indexed View Doesn’t Help
If we run this to create an indexed view on top of our base table, we still can’t create a filtered index, but there’s a different error message.
CREATE OR ALTER VIEW dbo.computed_column
WITH SCHEMABINDING
AS
SELECT
iv.id,
iv.notfizzbuzz
FROM dbo.indexed_view AS iv;
GO
CREATE UNIQUE CLUSTERED INDEX c
ON dbo.computed_column(id);
CREATE INDEX nfb
ON dbo.computed_column(notfizzbuzz)
WHERE notfizzbuzz = 0;
Msg 10610, Level 16, State 1, Line 37
Filtered index 'nfb' cannot be created on object 'dbo.computed_column' because it is not a user table.
Filtered indexes are only supported on tables.
If you are trying to create a filtered index on a view, consider creating an indexed view with the filter expression incorporated in the view definition.
But what a thoughtful error message it is! Thanks, whomever wrote that.
Still Needs Help
We can create this indexed view just fine.
CREATE OR ALTER VIEW dbo.computed_column
WITH SCHEMABINDING
AS
SELECT
iv.id,
iv.notfizzbuzz
FROM dbo.indexed_view AS iv
WHERE iv.notfizzbuzz = 0;
GO
CREATE UNIQUE CLUSTERED INDEX c
ON dbo.computed_column(id);
But if we try to select from it, the view is expanded.
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0;
If we run the query like this, and look at the end of the output, we’ll see a message at the bottom that our query is safe for auto (simple) parameterization. This may still happen even if the plan doesn’t remain trivial (more detail at the link above!)
DBCC FREEPROCCACHE;
GO
DBCC TRACEON(8607, 3604);
GO
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0;
DBCC TRACEOFF(8607, 3604);
GO
********************
** Query marked as Cachable
** Query marked as Safe for Auto-Param
********************
Making It Work
The two ways we can run this query to get the indexed view to be used are like so:
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc WITH(NOEXPAND)
WHERE cc.notfizzbuzz = 0;
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0
AND 1 = (SELECT 1);
thanks i guess
A Closer Look
If we put those two queries through the ringer, we’ll still see auto (simple) parameterization from the first query:
DBCC FREEPROCCACHE;
GO
DBCC TRACEON(8607, 3604);
GO
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc WITH(NOEXPAND)
WHERE cc.notfizzbuzz = 0;
GO
DBCC TRACEOFF(8607, 3604);
GO
********************
** Query marked as Cachable
** Query marked as Safe for Auto-Param
********************
DBCC FREEPROCCACHE;
GO
DBCC TRACEON(8607, 3604);
GO
SELECT
cc.id,
cc.notfizzbuzz
FROM dbo.computed_column AS cc
WHERE cc.notfizzbuzz = 0
AND 1 = (SELECT 1);
GO
DBCC TRACEOFF(8607, 3604);
GO
********************
** Query marked as Cachable
********************
It’s goofy, but it’s worth noting. Anyway, if I had to pick one of these methods to get the plan I want, it would be the NOEXPAND version.
Using that hint is the only thing that will allow for statistics to get generated on indexed views.
In case you’re wondering, marking the computed column as PERSISTED doesn’t change the outcome for any of these issues.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Implementing soft deletes for an app that’s been around for a while can be tough. In the same way as implementing Partitioning can be tough to add in later to get data management value from (rebuilding clustered indexes on the scheme, making sure all nonclustered indexes are aligned, and all future indexes are too, and making sure you have sufficient partitions at the beginning and end for data movement).
Boy, I really stressed those parentheses out.
If you do either one from the outset, it’s far less painful to manage. The structural stuff is there for you from the beginning, and you can test different strategies early on before data change become difficult to manage.
Queries
The first and most obvious thing is that all your queries now need to only find data that isn’t deleted.
Almost universally, it’s easier to put views on top of tables that have the appropriate bit search for deleted or not deleted rows than to expect people to remember it.
CREATE VIEW dbo.Users_Active
AS
SELECT
u.*
FROM dbo.Users AS u
WHERE u.is_deleted = 0;
CREATE VIEW dbo.Users_Inactive
AS
SELECT
u.*
FROM dbo.Users AS u
WHERE u.is_deleted = 1;
It’s not that views have any magical performance properties; they’re just queries after all, but it gives you an explicit data source.
Indexes
Depending on how your other queries search for data, you may need to start accounting for the is_deleted flag in your indexes. This could make a really big difference if the optimizer stops choosing your narrower nonclustered indexes because it hates key lookups.
Typically, other predicates will give you a selective-enough result set that a residual predicate on a bit field won’t make much difference. If you’ve already got a seek to the portion of data you’re interested in and most of it will be not-deleted, who cares?
And let’s be honest, in most implementations deleted rows will be the minority of data, and searches for it will be far less common. Usually it’s just there for an occasional audit.
In adjacent cases where instead of deleted you need to designate things as currently active, and you may have many inactive rows compared to active rows, filtered indexes can be your best friend.
Coming back to the views, I don’t think that making them indexed is necessary by default, but it might be if you’re using forced parameterization and filtered indexes.
CREATE TABLE dbo.Users(id int, is_deleted bit);
GO
CREATE INDEX u ON dbo.Users (id) WHERE is_deleted = 0;
GO
SELECT
u.id, u.is_deleted
FROM dbo.Users AS u
WHERE u.is_deleted = 0;
Under simple parameterization, this can be fine. Under forced parameterization, things can get weird.
tutor the tutors
Tables and Tables
In some cases, it might be easier to create tables specifically for deleted rows so you don’t have unnecessary data in your main tables. You can implement this easily enough with after triggers. Just make sure they’re designed to handle multiple rows.
If you want something out of the box, you might mess with:
Temporal tables
Change Data Capture
Change Tracking
However, none of those help you deal with who deleted rows. For that, you’ll need an Audit.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
We’ve got a set of missing index requests for a single table, and we’ve got the queries asking for them.
Going back to our queries and our index requests, all the queries have two things in common:
They filter on OwnerUserId
They order by Score
There are of course other elements in the where clause to attend to, but our job is to come up with one index that helps all of our queries.
Query Real Hard
To recap, these are our queries.
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY p.Score DESC;
GO 10
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.CreationDate >= '20130101'
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.LastActivityDate >= '20130101'
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score > 0
ORDER BY p.Score DESC;
Index Real Dumb
Which means that all of our missing index requests are going to be on maybe a couple key columns, and then include every other column in the Posts table.
This is a bad idea, so we’re going to dismiss the includes and focus on keys.
CREATE INDEX [OwnerUserId_LastActivityDate_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [LastActivityDate]);
CREATE INDEX [OwnerUserId_Score_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [Score]);
CREATE INDEX [OwnerUserId_PostTypeId_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [PostTypeId]);
CREATE INDEX [OwnerUserId_CreationDate_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId], [CreationDate]);
CREATE INDEX [OwnerUserId_Includes]
ON [StackOverflow2013].[dbo].[Posts] ([OwnerUserId]);
Now that we’ve got a more sane bunch of requests to focus on, let’s do something thinking.
I hate thinking, so we won’t do a lot of it.
Indexes put data in order, and equality predicates preserve ordering of secondary index columns. That makes putting the key on (OwnerUserId, Score) a no-brainer. One could make an entire career out of avoiding sorting in the database.
But now we have three other columns to think about: LastActivityDate, PostTypeId, and CreationDate.
We could spend a whole lot of time trying to figure out the best order here, considering things like: equality predicates vs inequality predicates, and selectivity, etc.
But what good would it do?
Dirty Secret
No matter what order we might put index key columns in after Score, it won’t matter. Most of our queries don’t search on OwnerUserId and then Score. Only one of them does, and it doesn’t search on anything else.
That means that most of the time, we’d be seeking to OwnerUserId, and then performing residual predicates against other columns we’re searching on.
On top of that, we’d have whatever overhead there is of keeping things in order when we modify data in the key of the index. Not that included columns are free-of-charge to modify, but you get my point. There’s no order preserved in them.
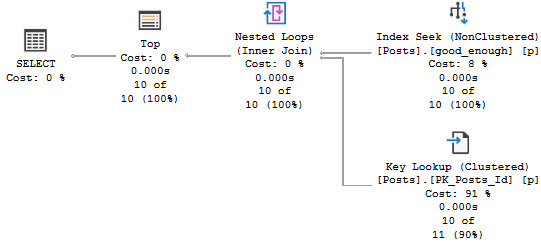
In reality, a good-enough-index for the good-enough-optimizer to come up with a good-enough-plan looks like this:
CREATE INDEX good_enough
ON dbo.Posts
(OwnerUserId, Score)
INCLUDE
(PostTypeId, CreationDate, LastActivityDate);
Planama
The index above does two things:
It helps us search on a selective predicate on OwnerUserId
It keeps Score in order after the quality so the order by is free
It has all the other potential filtering elements so we can apply predicates locally
It teaches us that include column order doesn’t matter
All of the query plans will look roughly like this, regardless of the where clause:
you can do it
What Difference Does It Make?
Alright, so we’ve got one good-enough index for a bunch of different queries. By adding the index, we got all of them to go from taking ~600ms to taking 0ms.
What else did we do?
We made them faster without going parallel
They no longer need memory to sort data
And we did it without creating a gigantic covering index.
Of course, the optimizer still thinks we need indexes…
of what?
But do we really need them?
No.
77% of nothing is nothing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.