If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If you have selective predicates earlier in the index that filter a lot of rows, the SARGability of trailing predicates matters less.
CREATE INDEX shorty ON dbo.a_table(selective_column, non_selective_column);
SELECT COUNT(*) AS records
FROM dbo.a_table AS a
WHERE selective_column = 1
AND ISNULL(non_selective_column, 'whatever') = 'whatever';
Am I saying you should do this? Am I saying that it’s a good example to set?
No. I’m just saying you can get away with it in this situation.
Longer Answer
The less selective other predicates are, the less you can get away with it.
Take these two queries:
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id = 8
AND ISNULL(u.Location, N'') = N'';
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id BETWEEN 8 AND 9693617
AND ISNULL(u.Location, N'') = N'';
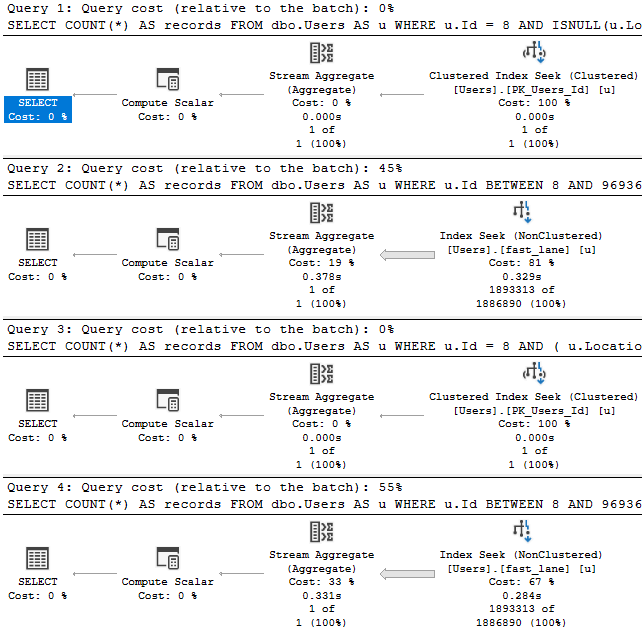
The first one has an equality predicate on the Id, the primary key of the table. It’s going to touch one row, and then evaluate the residual predicate on Location.
The second query has a very non-selective range predicate on Id — still a selective column, just not a selective predicate anymore — so, we do a lot more work (relatively).
If we have this index, and we look at how four logically equivalent queries perform:
CREATE UNIQUE INDEX fast_lane ON dbo.Users(Id, Location);
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id = 8
AND ISNULL(u.Location, N'') = N'';
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id BETWEEN 8 AND 9693617
AND ISNULL(u.Location, N'') = N'';
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id = 8
AND ( u.Location = N''
OR u.Location IS NULL );
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id BETWEEN 8 AND 9693617
AND ( u.Location = N''
OR u.Location IS NULL );
The query plans tell us enough:
Toasty
It really doesn’t matter if we obey the laws of SARGability here.
Expect Depression
There have been many times when explaining SARGability to people that they went back and cleaned up code like this to find it didn’t make much of a difference to performance. That’s because SARGability depends on indexes that can support seekable predicates. Without those indexes, it makes no practical difference how you write these queries.
Again, I’m not condoning writing Fast Food Queries when you can avoid it. Like I said earlier, it sets a bad example.
Once this kind of code creeps into your development culture, it’s hard to keep it contained.
There’s no reason to not avoid it, but sometimes it hurts more than others. For instance, if Location were the first column in the index, we’d have a very different performance profile across all of these queries, and other rewrites might start to make more sense.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Our job now is to figure out how to even things out. To do that, we’re gonna need to mess with out index a little bit.
Right now, we have this one:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, LastActivityDate)
INCLUDE(Score, ViewCount);
Which is fine when we need to Sort a small amount of data.
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
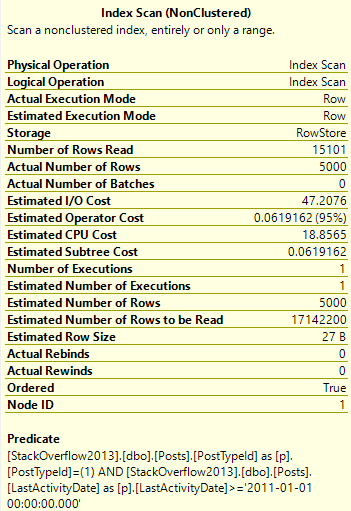
WHERE p.PostTypeId = 4
AND p.LastActivityDate >= '20120101'
ORDER BY p.Score DESC;
There’s only about 25k rows with a PostTypeId of 4. That’s easy to deal with.
The problem is here:
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
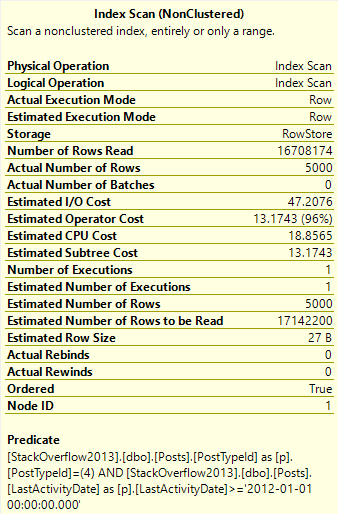
WHERE p.PostTypeId = 1
AND p.LastActivityDate >= '20110101'
ORDER BY p.Score DESC;
Theres 6,000,223 rows with a PostTypeId of 1 — that’s a question.
Don’t get me started on PostTypeId 2 — that’s an answer — which has 11,091,349 rows.
Change Management
What a lot of people try first is an index that leads with Score. Even though it’s not in the WHERE clause to help us find data, the index putting Score in order first seems like a tempting fix to our problem.
CREATE INDEX whatever
ON dbo.Posts(Score DESC, PostTypeId, LastActivityDate)
INCLUDE(ViewCount)
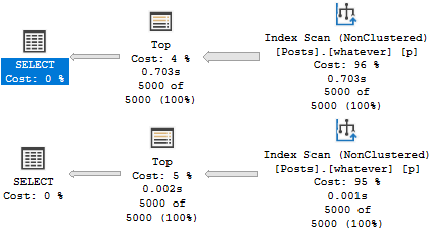
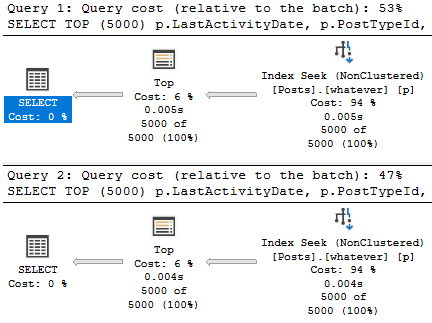
The result is pretty successful. Both plans are likely fast enough, and we could stop here, but we’d miss a key point about B-Tree indexes.
It’s not so bad.
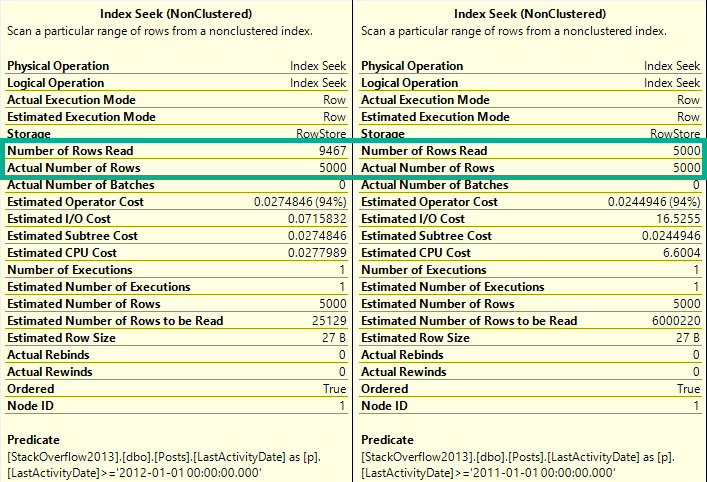
What’s a bit deceptive about the speed is the amount of reads we do to locate our data.
Scan-Some
We only need to read 15k rows to find the top 5000 Questions — remember that these are very common.
We need to read many more rows to find the top 5000… Er… Whatever a 4 means.
Imaginary Readers
Nearly the entire index is read to locate these Post Types.
Meet In The Middle
The point we’d miss if we stopped tuning there is that when we add key columns to a B-Tree index, the index is first ordered by the leading key column. If it’s not unique, then the second column is ordered within each range of values.
Pale Coogi Wave
Putting this together, let’s change our index a little bit:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, Score DESC, LastActivityDate)
INCLUDE(ViewCount) WITH (DROP_EXISTING = ON);
With the understanding that seeking to a single PostTypeId column will bring us to an ordered Sort column for that range of values.
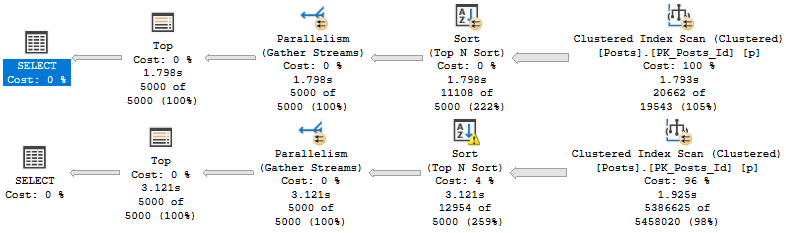
Now our plans look like this:
???
Which allows us to both avoid the Sort and keep reads to a minimum.
reed les
Interior Design
When designing indexes, it’s important to keep the goal of queries in mind. Often, predicates should be the primary consideration.
Other times, we need to take ordering and grouping into account. For example, if we’re using window functions, performance might be unacceptable without indexing the partition by and order by elements, and we may need to move other columns to parts of the index that may not initially seem ideal.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
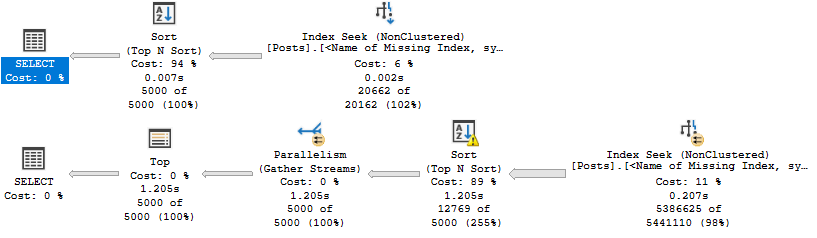
I asked you to design one index to make two queries fast.
If we look at the plans with no supporting indexes, we’ll see why they need some tuning.
Get a job
In both queries, the optimizer will ask for a “missing index”. That’s in quotes because, gosh darnit, I wouldn’t miss this index.
Green Screen
Nauseaseated
If we add it, results are mixed, like cheap scotch.
Keep Walking
Sure, there’s some improvement, but both aren’t fast. The second query does a lot of work to sort data.
We have an inkling that if we stopped doing that, our query may get quicker.
Let’s stop and think here: What are we ordering by?
Of course, it’s the thing in the order by: Score DESC.
Where Do We Go Now?
It looks like that missing index request was wrong. Score shouldn’t have been an included column.
Columns in the include list are only ordered by columns in the key of the index.
If we wanna fix that Sort, we need to make it a key column.
But where?
Get to work.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 4
AND p.LastActivityDate >= '20120101'
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.LastActivityDate >= '20110101'
ORDER BY p.Score DESC;
Get to work.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
While helping a client out with a performance problem recently, I ran into something kind of funny when creating a computed column.
They were experiencing performance problems because of a join involving a substring.
Weird, right? Like, if I tried to show you this in a presentation, you’d chase me out of the room.
But since they were nice enough to hire me, I went about fixing the problem.
Computer Magic
The “obvious” — and I apologize if this isn’t obvious to you, dear reader — was to add a computed column to work around the issue.
Adding a computed column gives you the expression that you’re generating on the fly and trying to join on. Because manipulating column data while you’re joining or filtering on it is generally a bad idea. Sometimes you can get away with it.
But here’s something that messed me up, a uh… seasoned database professional.
The query was doing something like this (not exactly, but it’s good enough to get us moving):
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE SUBSTRING(u.DisplayName, 1, LEN(u.DisplayName) - 4)
= SUBSTRING(u.DisplayName, 1, LEN(u.DisplayName) - 4);
Matching strings from the beginning to the end minus four characters.
I wanted to look smart, so I did this:
ALTER TABLE dbo.Users
ADD DisplayNameComputed
AS SUBSTRING(DisplayName, 1, LEN(DisplayName) - 4);
I didn’t want to persist it right away — that can lock the table and take longer — and because I knew I was going to index it.
The problem is that when I tried to index it:
CREATE INDEX dummy
ON dbo.Users(DisplayNameComputed);
I got this error:
Msg 537, Level 16, State 3, Line 21
Invalid length parameter passed to the LEFT or SUBSTRING function.
And when I tried to select data from the table, the same error.
In the real query, there was a predicate that avoided columns with too few characters, but it was impossible to apply that filter to the index.
There’s also other restrictions on filtered index where clauses, like you can’t like LIKE ‘____%’, or LEN(col) > 4, etc.
Case Of Mace
Having done a lot of string splitting in my life, I should have been more defensive in my initial computed column definition.
What I ended up using was this:
ALTER TABLE dbo.Users
ADD DisplayNameComputed
AS SUBSTRING(DisplayName, 1, LEN(DisplayName)
- CASE WHEN LEN(DisplayName) < 4 THEN LEN(DisplayName) ELSE 4 END);
A bit more verbose, but it allowed me to create my computed column, select from the table, and create my index.
AND THEY ALL LIVED HAPPILY EVER AFTER
Just kidding, there was still a lot of work to do.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If you compare the things that non-SARGable queries cause issues with alongside the things that bad implicit conversions cause issues with, it’s an identical list.
Increased CPU
Inefficient use of indexes
Poor cardinality estimation
Maybe a bad memory grant based on that
Some “row by row” event
Though we often bucket the problems separately, they’re really the same thing.
That’s because, under the covers, something similar happens.
Four letters
If you replace “CONVERT_IMPLICIT” with any other function, like ISNULL, COALESCE, DATEADD, DATEDIFF, etc. you may see the same performance degradation.
Probably not the most thought provoking thing you’ve ever heard, but if you understand why one is bad and not the other, this may help you.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.