If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When writing queries, sometimes you have the pleasure of being able to pass a literal value, parameter, or scalar expression as a predicate.
With a suitable index in place, any one of them can seek appropriately to the row(s) you care about.
But what about when you need to compare the contents of one column to another?
It gets a little bit more complicated.
All About Algorithms
Take this query to start with, joining Users to Posts.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
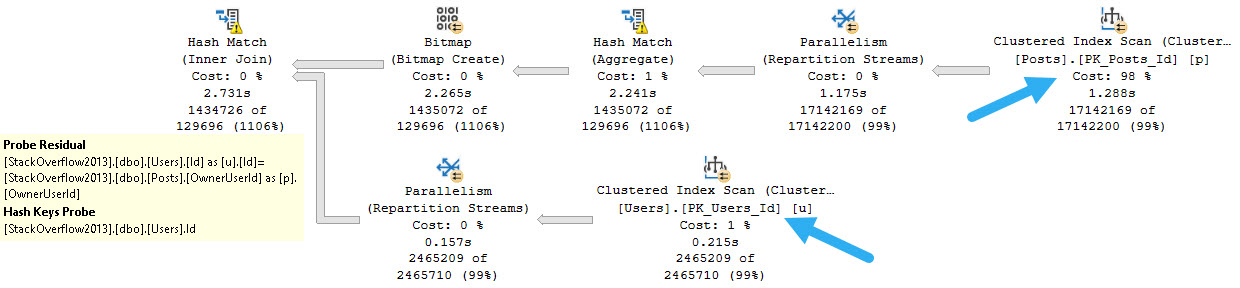
The OwnerUserId column doesn’t have an index on it, but the Id column on Users it the primary key and the clustered index.
But the type of join that’s chosen is Hash, and since there’s no where clause, there’s no predicate to apply to either table for filtering.
jumbo
This is complicated slightly by the Bitmap, which is created on the OwnerUserId column from the Posts table and applied to the Id column from the Users table as an early filter.
The same pattern can generally be observed with Merge Joins. Where things are a bit different is with Nested Loops.
Shoop Da Loop
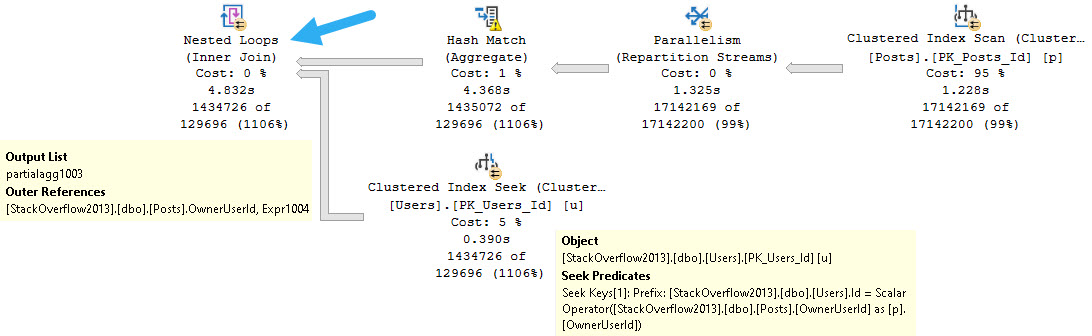
If we use a query hint, we can see what would happen with a Nested Loops Join.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
OPTION(LOOP JOIN);
The plan looks like this now, with a Seek on the Users table.
petting motions
The reason is that this flavor of Nested Loops, known as Apply Nested Loops, takes each row from the outer input and uses it as a scalar operator on the inner input.
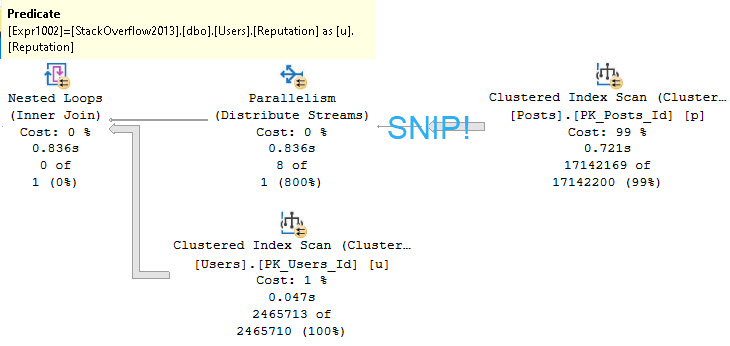
An example of Regular Joe Nested Loops™ looks like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation =
(
SELECT
MIN(p.Score)
FROM dbo.Posts AS p
);
Where the predicate is applied at the Nested Loops operator:
and bert
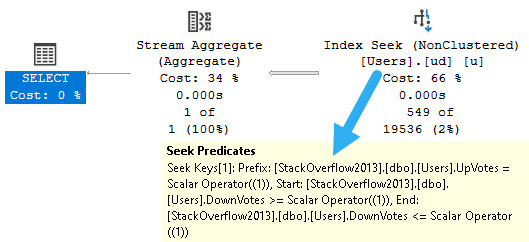
Like most things, indexing is key, but there are limits.
Innermost
Let’s create this index:
CREATE INDEX ud ON dbo.Users(UpVotes, DownVotes);
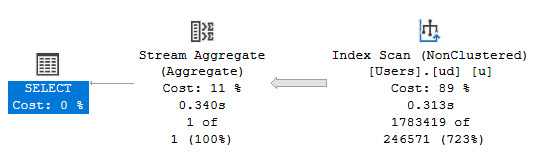
And run this query:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.UpVotes = u.DownVotes;
The resulting query plan looks like this:
did a cuss
But what other choice is there? If we want a seek, we need a particular thing or things to seek to.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.UpVotes = u.DownVotes
AND u.UpVotes = 1;
name game
We seek to everyone with an UpVote of 1, and then somewhat awkwardly search the DownVotes column for values >= 1 and <= 1.
But again, these are specific values we can search for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’m writing this series because as interesting as single operators can be, you rarely run into interesting query plans that are a single operator. I don’t know exactly how many posts this will end up being. I have a list of about 15 things that I’d like to write about.
Anyway, I’d been thinking about something like this for a while, because being able to understand which part of a query generates which part of a query plan can help you focus in on what you need to work on. It’s also helpful to understand how different aspects of your database design and written queries might manifest in query plans.
You know, for performance.
Anyway, I hope you enjoy it. This post will be remarkably empty on first read, but will populate over time.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
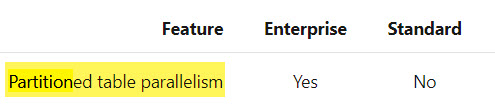
UPDATE 2021-04-14: Microsoft has updated the documentation for all 2016+ versions of SQL Server to indicate that parallelism is available for partitioned tables in non-Enterprise versions.
For the sake of completeness, I did all my testing across both Standard and Developer Editions of SQL Server and couldn’t detect a meaningful difference.
There may be scenarios outside of the ones I tested that do show a difference, but, uh. I didn’t test those.
Obviously.
Every table is going to test this query at different DOPs.
SELECT
DATEPART(YEAR, vp.CreationDate) AS VoteYear,
DATEPART(MONTH, vp.CreationDate) AS VoteMonth,
COUNT_BIG(DISTINCT vp.PostId) AS UniquePostVotes,
SUM(vp.BountyAmount) AS TotalBounties
FROM dbo.Votes_p AS vp
GROUP BY
DATEPART(YEAR, vp.CreationDate),
DATEPART(MONTH, vp.CreationDate);
Two Partitions
Here’s the setup:
CREATE PARTITION FUNCTION VoteYear2013_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20130101'
);
GO
CREATE PARTITION SCHEME VoteYear2013_ps
AS PARTITION VoteYear2013_pf
ALL TO ([PRIMARY]);
DROP TABLE IF EXISTS dbo.Votes2013_p;
CREATE TABLE dbo.Votes2013_p
(
Id int NOT NULL,
PostId int NOT NULL,
UserId int NULL,
BountyAmount int NULL,
VoteTypeId int NOT NULL,
CreationDate datetime NOT NULL,
CONSTRAINT PK_Votes2013_p_Id
PRIMARY KEY CLUSTERED (CreationDate, Id)
) ON VoteYear2013_ps(CreationDate);
INSERT dbo.Votes2013_p WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v;
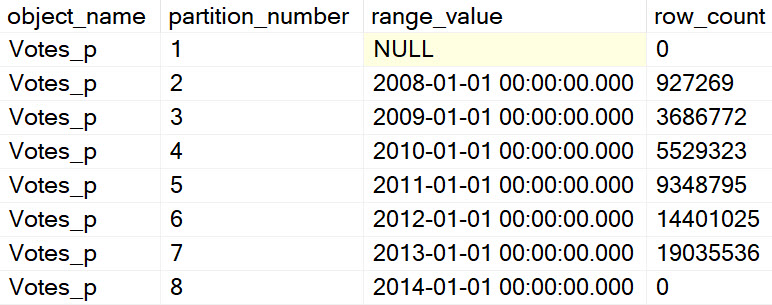
The data split looks like this:
not a good use of partitioning
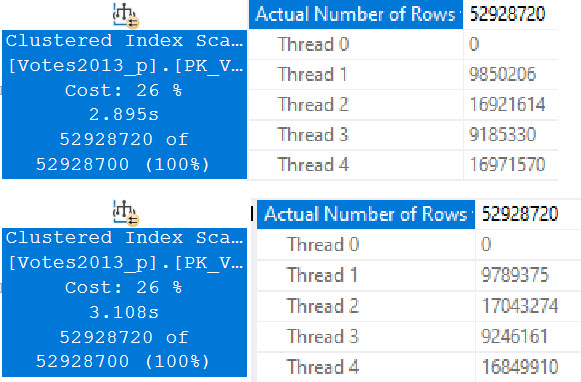
Running our test query at DOP 4, there are slight differences in counts across threads, but slight timing differences can explain that.
bonker
Standard Edition is on top, Developer Edition is at the bottom. There is a ~200ms difference here, but averaged out over multiple runs things end up pretty dead even.
Even looking at the row counts per thread, the distribution is close across both versions. I think it’s decently clear that the four threads work cooperatively across both partitions. A similar pattern continues at higher DOPs, too. I tested 8 and 16, and while there were slight differences in row counts per thread, there was a similar distribution pattern as at DOP 4.
Eight Partitions
Using a different partitioning function:
CREATE PARTITION FUNCTION VoteYear_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20080101',
'20090101',
'20100101',
'20110101',
'20120101',
'20130101',
'20140101'
);
GO
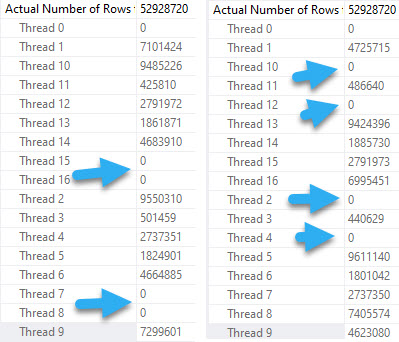
We’re going to jump right to testing the query at DOP 8.
dartford
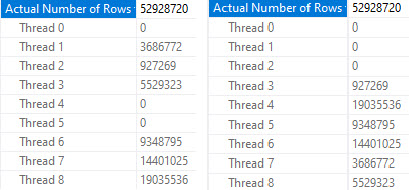
Again, different threads end up getting assigned the work, but row counts match exactly across threads that did get work, and those numbers line up exactly to the number of rows in each partition.
pattern forming
In both queries, two threads scanned a partition with no rows and did no work. Each thread that did scan a partition scanned only one partition.
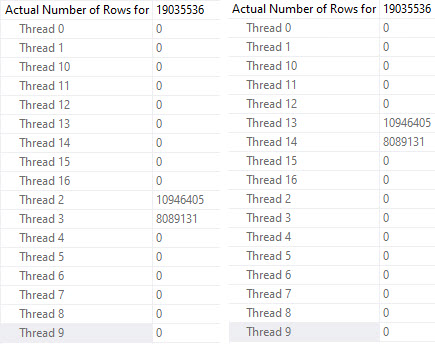
At DOP 16, the skew gets a bit worse, because now four threads do no work.
crap
The remaining threads all seem to split the populated partitions evenly, though again there are slight timing differences that result in different row counts per thread, but it’s pretty clear that there is cooperation here.
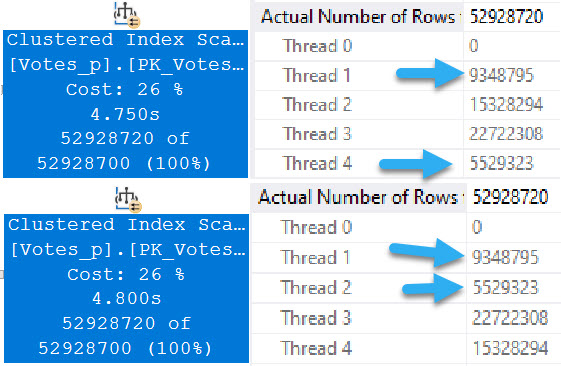
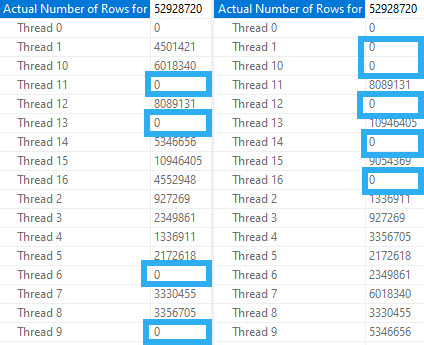
At DOP 4, things get a bit more interesting.
bedhead
In both queries, two threads scan exactly one partition.
The rows with arrows pointing at them represent numbers that exactly match the number of rows in a single partition.
The remaining threads have exactly the same row counts across versions.
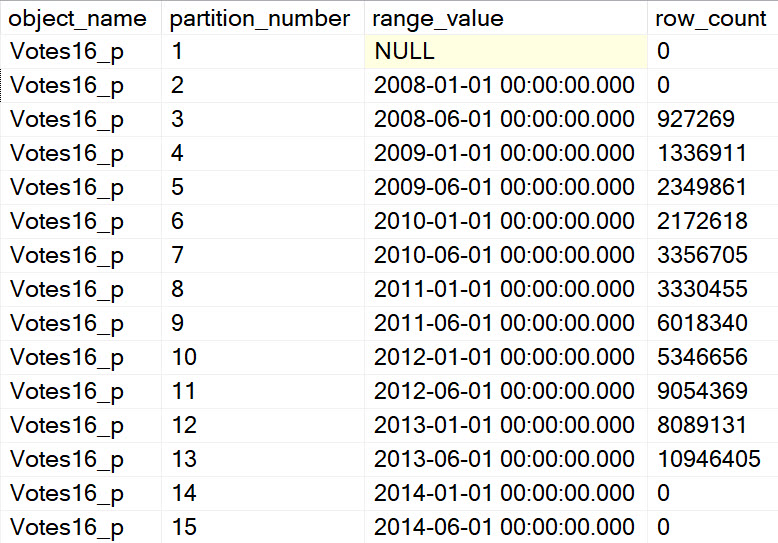
Fifteen Partitions
The results here show mostly the same pattern as before, so I’m keeping it short.
CREATE PARTITION FUNCTION VoteYear16_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20080101',
'20080601',
'20090101',
'20090601',
'20100101',
'20100601',
'20110101',
'20110601',
'20120101',
'20120601',
'20130101',
'20130601',
'20140101',
'20140601'
);
GO
At DOP 4 and 8, threads work cooperatively across partitions. Where things get interesting (sort of) is at DOP 16.
craptastic
The four empty partitions here result in 4 threads doing no work in Developer/Enterprise Edition, and 5 threads doing no work in Standard Edition.
donkey
At first, I thought this might be a crack in the case, so I did things a little bit differently. In a dozen or so runs, the 5 empty threads only seemed to occur in the Standard Edition query. Sometimes it did, sometimes it didn’t. But it was at least something.
Fifteen Partitions, Mostly Empty
I used the same setup as above, but this time I didn’t fully load data from Votes in:
INSERT dbo.Votes16e_p WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.CreationDate >= '20130101';
And… Scene!
flop
That’s Just Great
Aside from one case where an extra thread got zero rows in Standard Edition, the behavior across the board looks the same.
Most of the behavior is sensible, but cases where multiple threads get no rows and don’t move on to other partitions is a little troubling.
Not that anyone has partitioning set up right anyway.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There was a three-part series of posts where I talked about a weird performance issue you can hit with parameterized top. While doing some query tuning for a client recently, I ran across a funny scenario where they were using TOP PERCENT to control the number of rows coming back from queries.
With a parameter.
So uh. Let’s talk about that.
Setup Time
Let’s start with a great index. Possibly the greatest index ever created.
CREATE INDEX whatever
ON dbo.Votes
(VoteTypeId, CreationDate DESC)
WITH
(
MAXDOP = 8,
SORT_IN_TEMPDB = ON
);
GO
Now let me show you this stored procedure. Hold on tight!
CREATE OR ALTER PROCEDURE dbo.top_percent_sniffer
(
@top bigint,
@vtid int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT TOP (@top) PERCENT
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
Cool. Great.
Spool Hardy
When we execute the query, the plan is stupid.
EXEC dbo.top_percent_sniffer
@top = 1,
@vtid = 6;
GO
the louis vuitton of awful
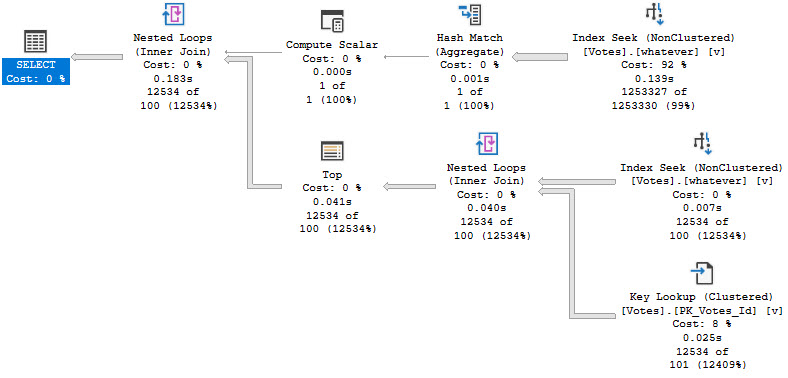
We don’t use our excellent index, and the optimizer uses an eager table spool to hold rows and pass the count to the TOP operator until we hit the correct percentage.
This is the least ideal situation we could possibly imagine.
Boot and Rally
A while back I posted some strange looking code on Twitter, and this is what it ended up being used for (among other things).
CREATE OR ALTER PROCEDURE dbo.top_percent_sniffer
(
@top bigint,
@vtid int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN;
WITH pct AS
(
SELECT
records =
CONVERT(bigint,
CEILING(((@top * COUNT_BIG(*)) / 100.)))
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
)
SELECT
v.*
FROM pct
CROSS APPLY
(
SELECT TOP (pct.records)
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC
) AS v;
END;
GO
better butter
Soul Bowl
This definitely has drawbacks, since the expression in the TOP always gives a 100 row estimate. For large numbers of rows, this plan could be a bad choice and we might need to do some additional tuning to get rid of that lookup.
There might also be occasions when using a column store index to generate the count would be benefit, and the nice thing here is that since we’re accessing the table in two different ways, we could use two different indexes.
But for reliably small numbers of rows, this is a pretty good solution.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.