Rumble, Young Man, Rumble
People. People complain. People complain about SQL Server. That’s probably why I get paid to deal with it, but whatever.
One complaint I get to hear week in and week out is that SQL Server isn’t using someone’s index, or that there are too many index scans and they’re slow.
That might actually be a composite of like twelve complaints, but let’s not start counting.
Usually when we start examining the queries, query plans, and indexes for these renegades, the reasons for the lack of a seek become apparent.
- There’s no good index to seek to
- The query is written in a way that seeks can’t happen
- A predicate is on two columns
Desperately Seeking Susan
In a query that doesn’t have any of those problems, you’ll naturally get a seek and feel really good about yourself.
CREATE INDEX v ON dbo.Votes(PostId)
WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.PostId = 194812;
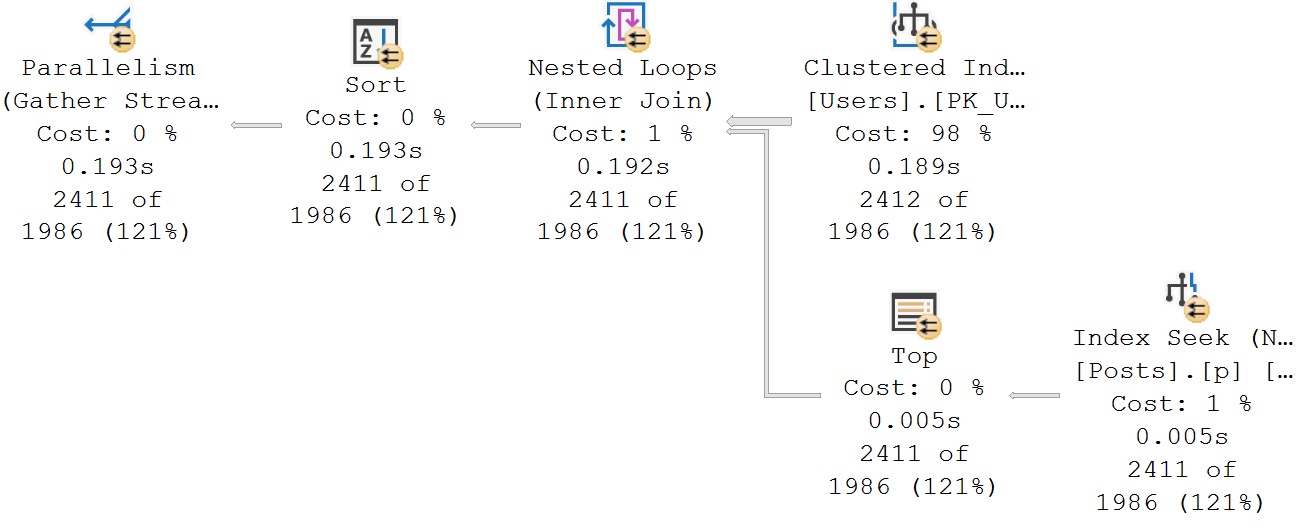
We’re set for success! And look how happy things are. Happy little query plans.

Sargy Bargy
You’re smart people. You’re on top of things. You know that without an index on PostId, the query up above wouldn’t have anything to seek to.
Useful indexes are half the battle. The other half of the battle is not screwing things up.
I’m going to use dynamic SQL as shorthand for any parameterized query. I should probably add that using a local variable would only make things worse.
Don’t do that. Or this.
DECLARE
@sql nvarchar(MAX) = N'',
@PostId int = 194812;
SELECT
@sql = N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE (v.PostId = @PostId
OR @PostId IS NULL);';
EXEC sys.sp_executesql
@sql,
N'@PostId int',
@PostId;
While we’re on the topic, don’t do this either.
DECLARE
@sql nvarchar(MAX) = N'',
@PostId int = 194812;
SELECT
@sql = N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.PostId = ISNULL(@PostId, v.PostId);';
EXEC sys.sp_executesql
@sql,
N'@PostId int',
@PostId;
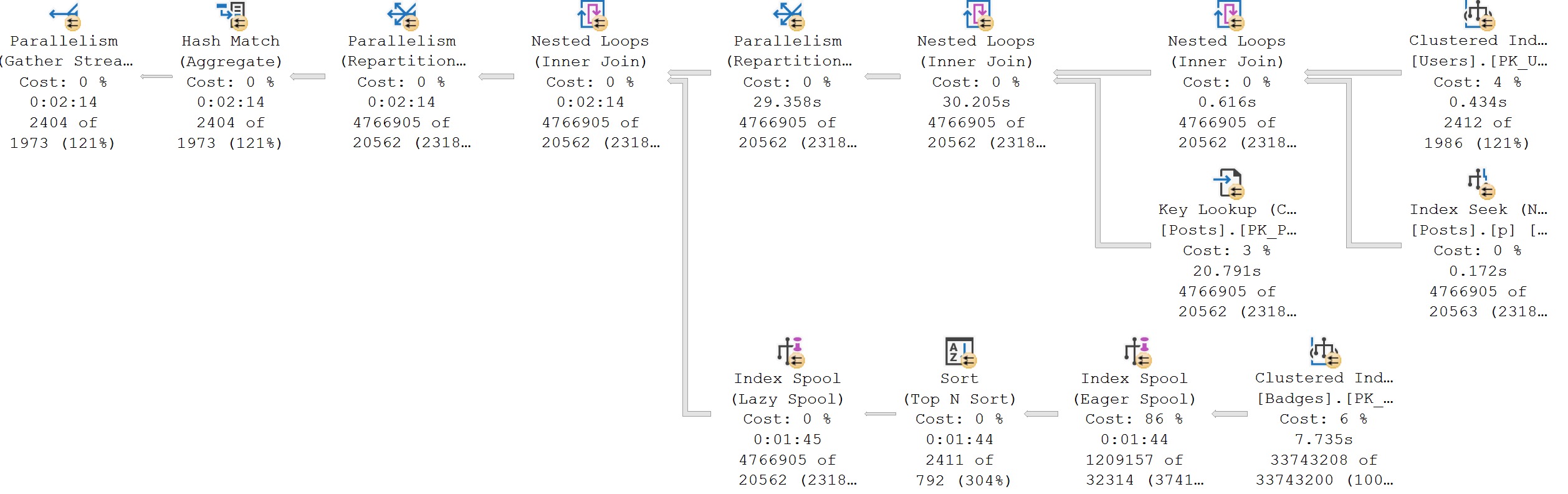
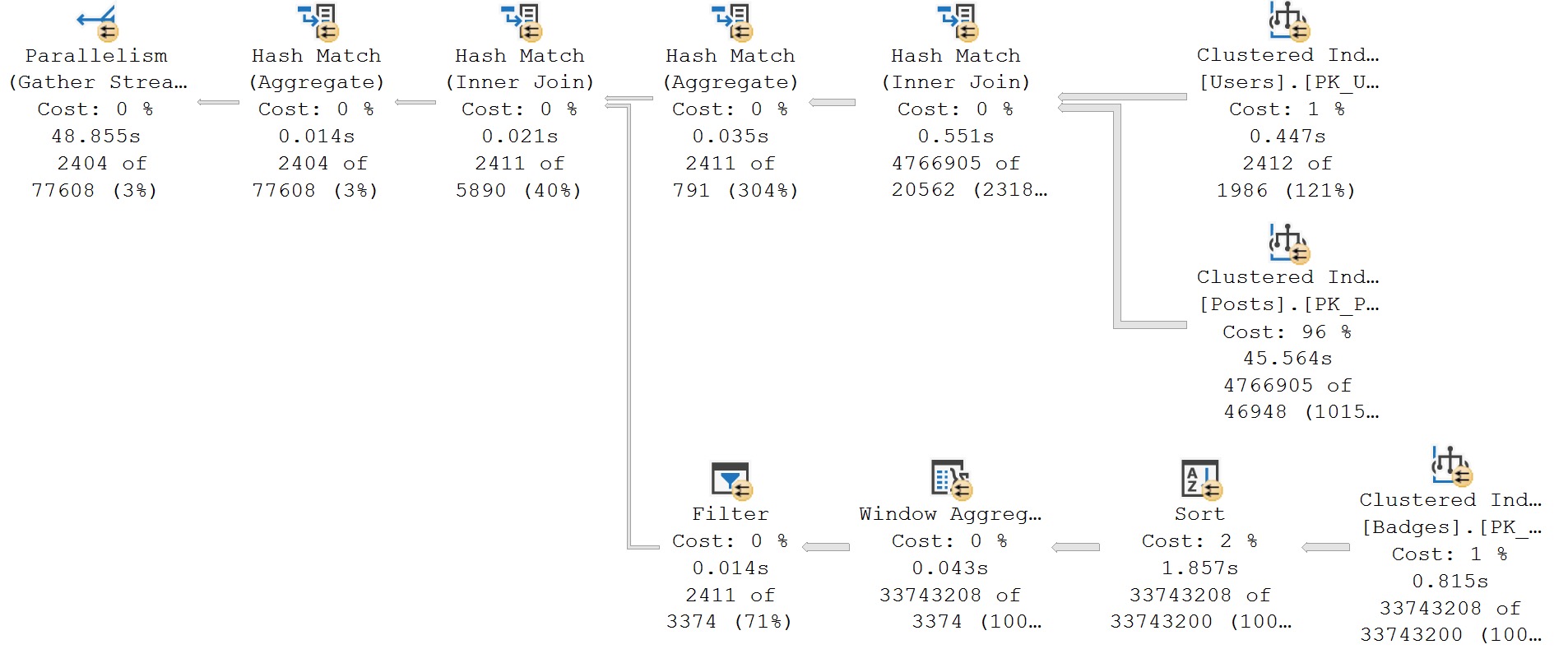
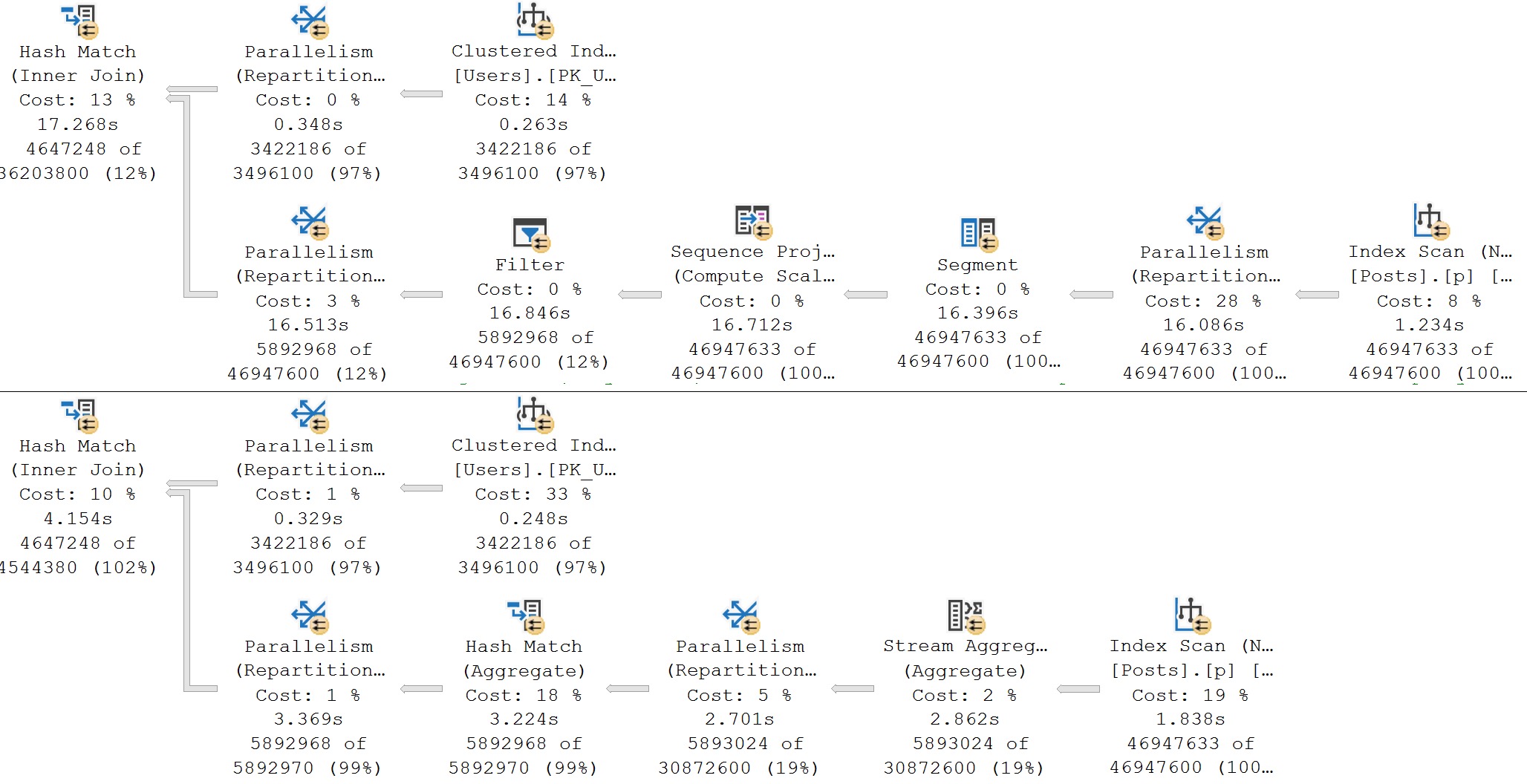
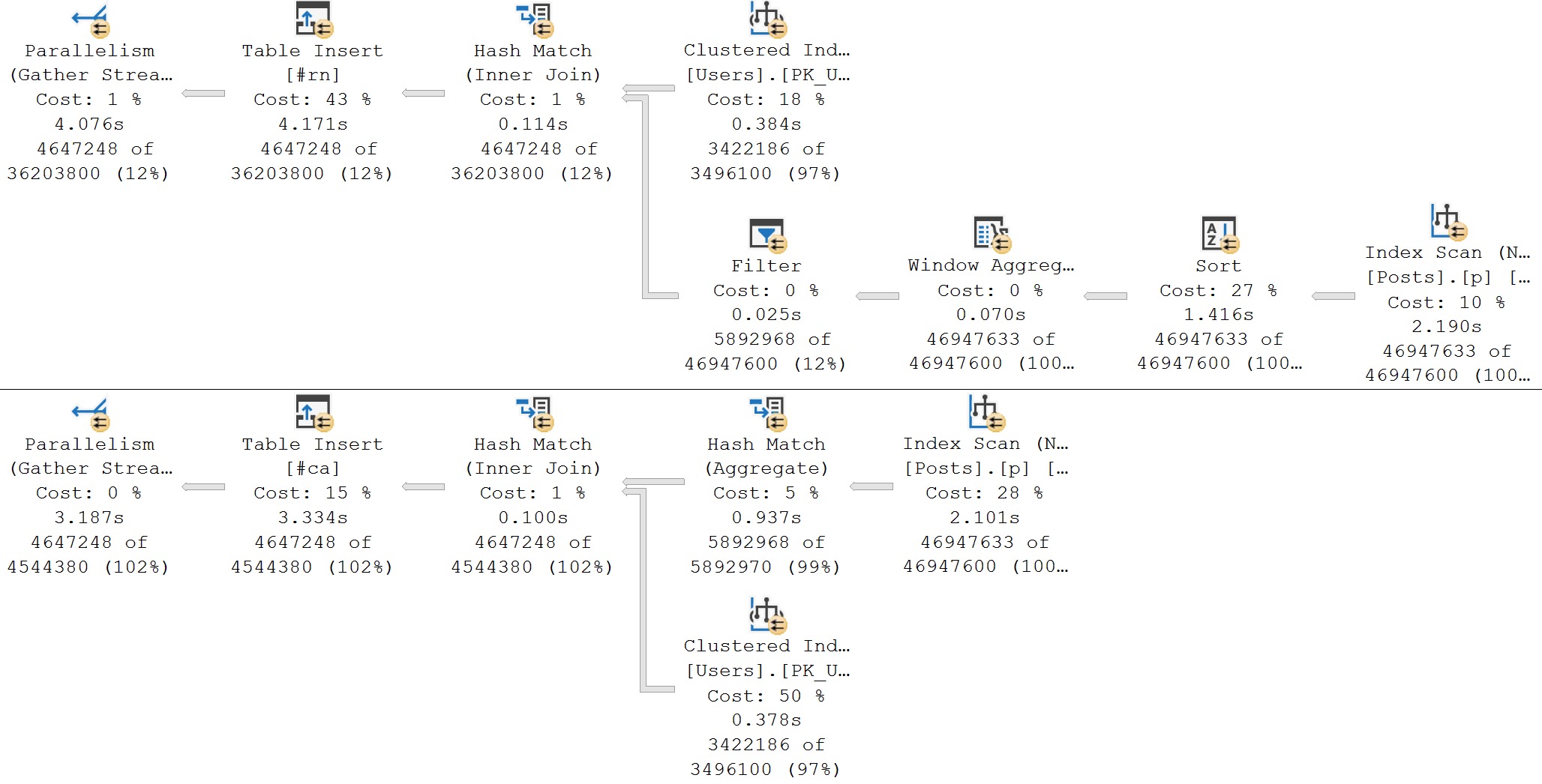
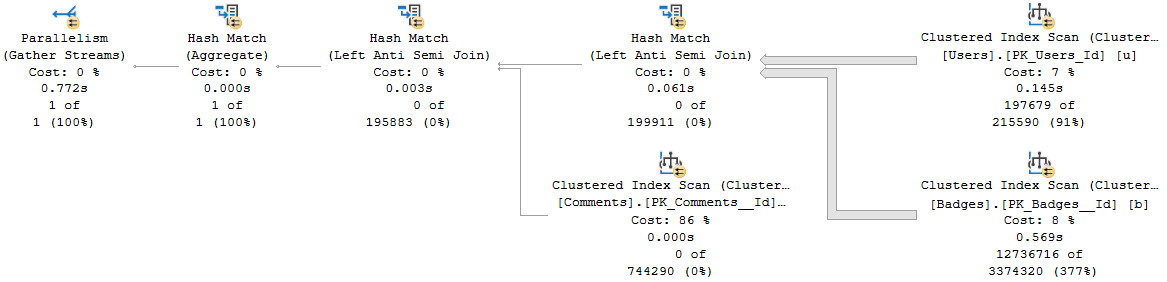
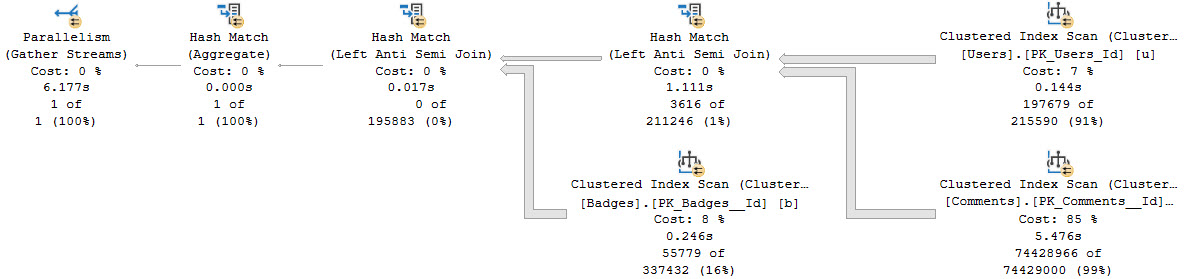
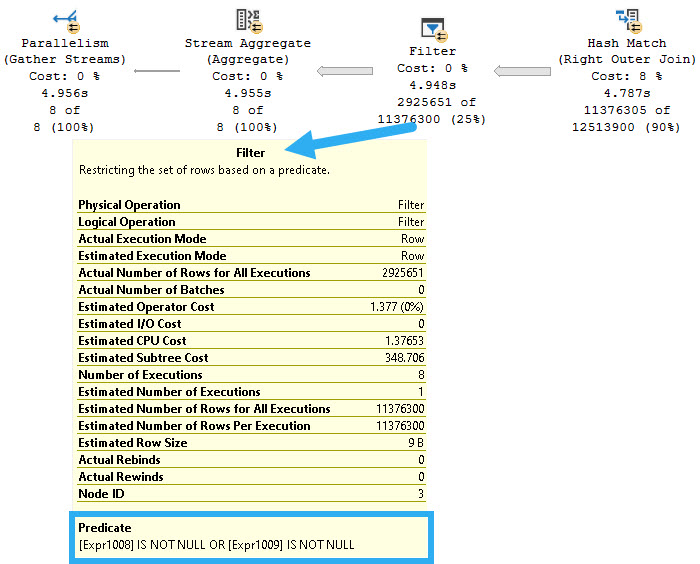
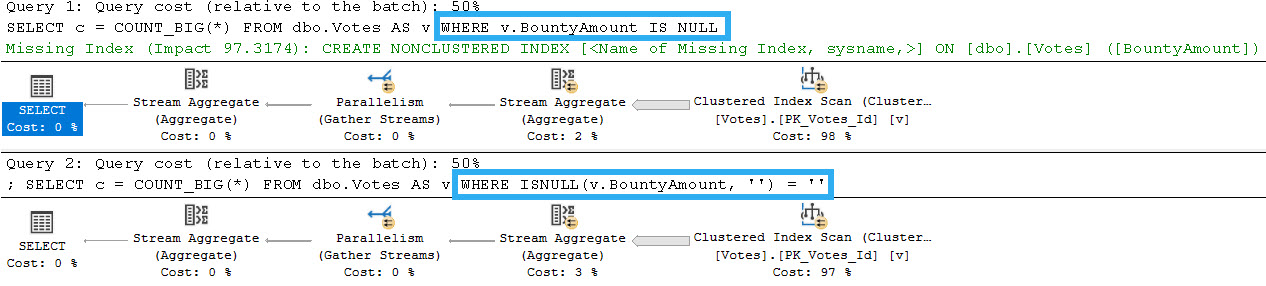
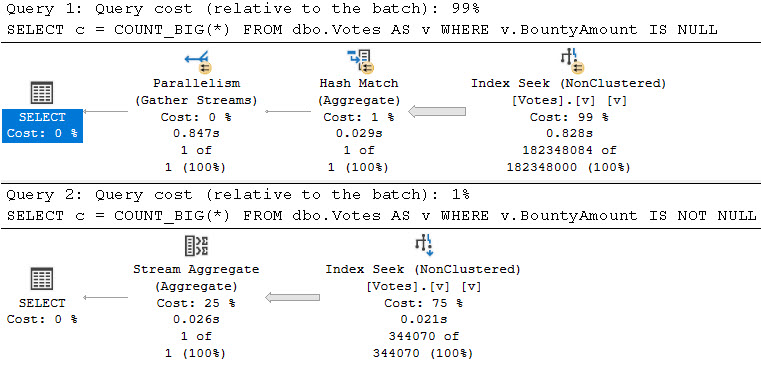
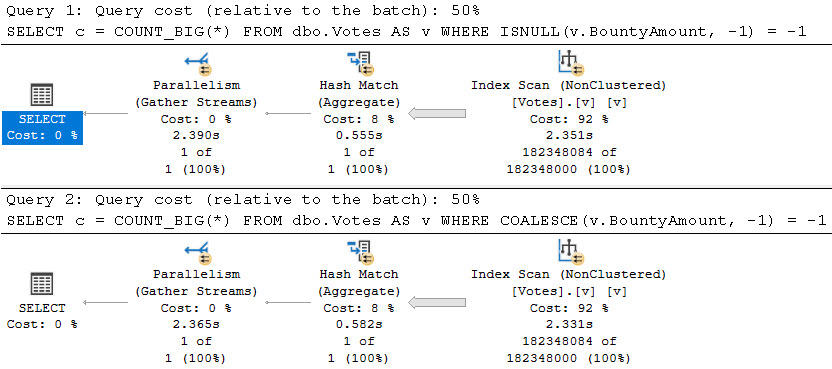
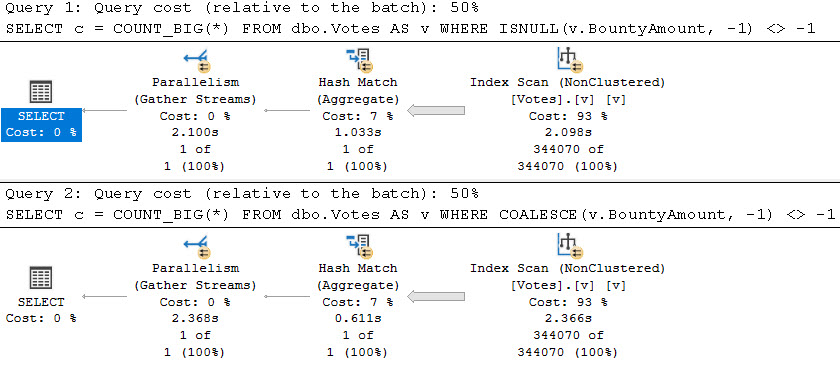
Here’s the query plans for these:
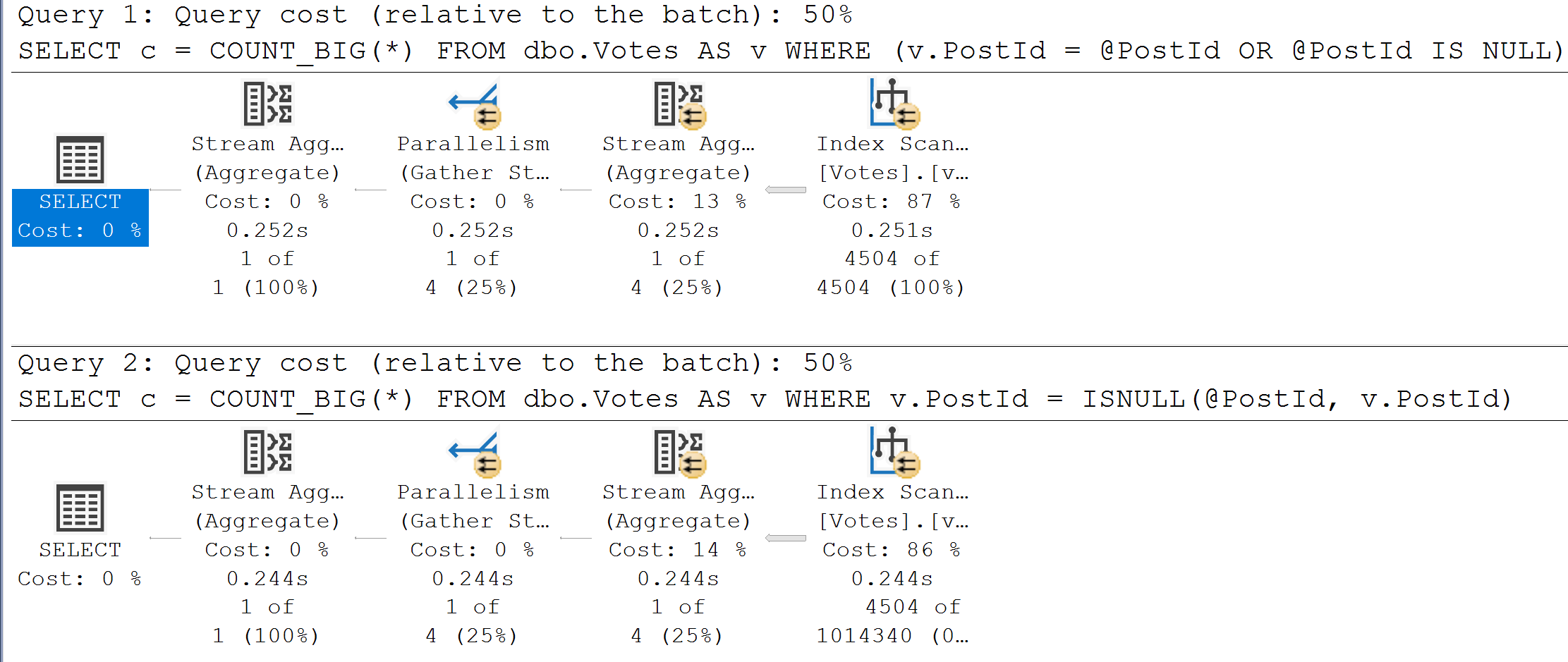
We end up not only scanning the entire index unnecessarily, but the second one gets a really unfavorable cardinality estimate.
It’s amazing how easy it is to ruin a perfectly good seek with lazy query writing, isn’t it?
Joint Venture
When you compare two columns in tables, you might not always see a seek, even if you have the best index ever.
Let’s use this as an example:
CREATE INDEX p ON dbo.Posts(OwnerUserId, LastEditorUserId)
WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = p.LastEditorUserId;
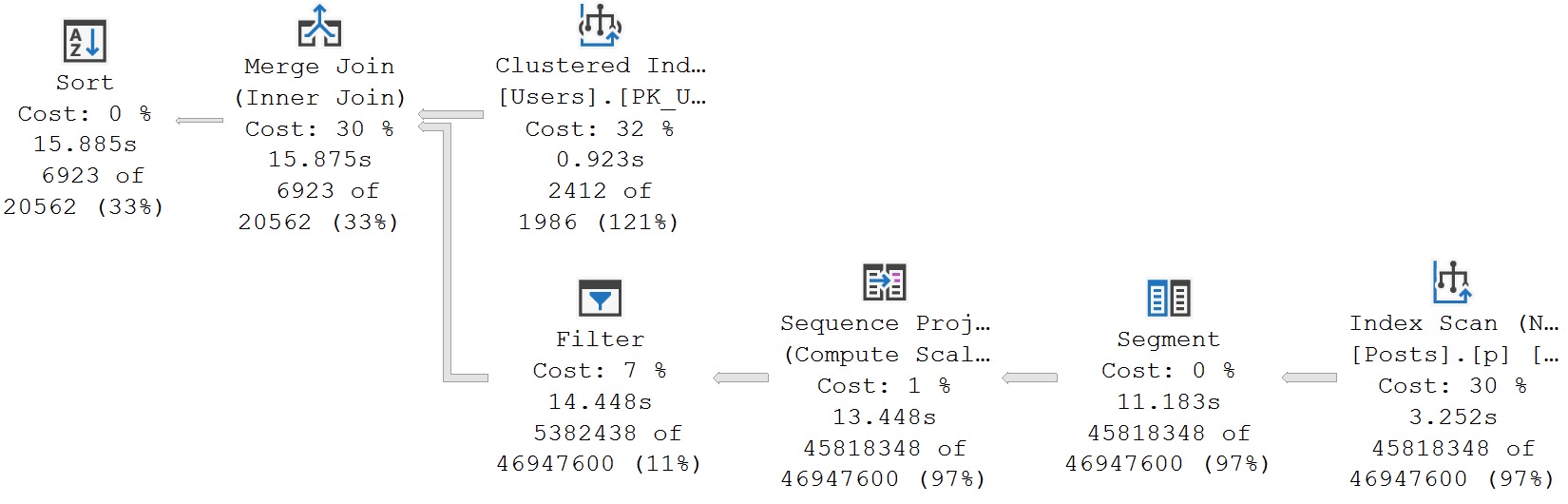
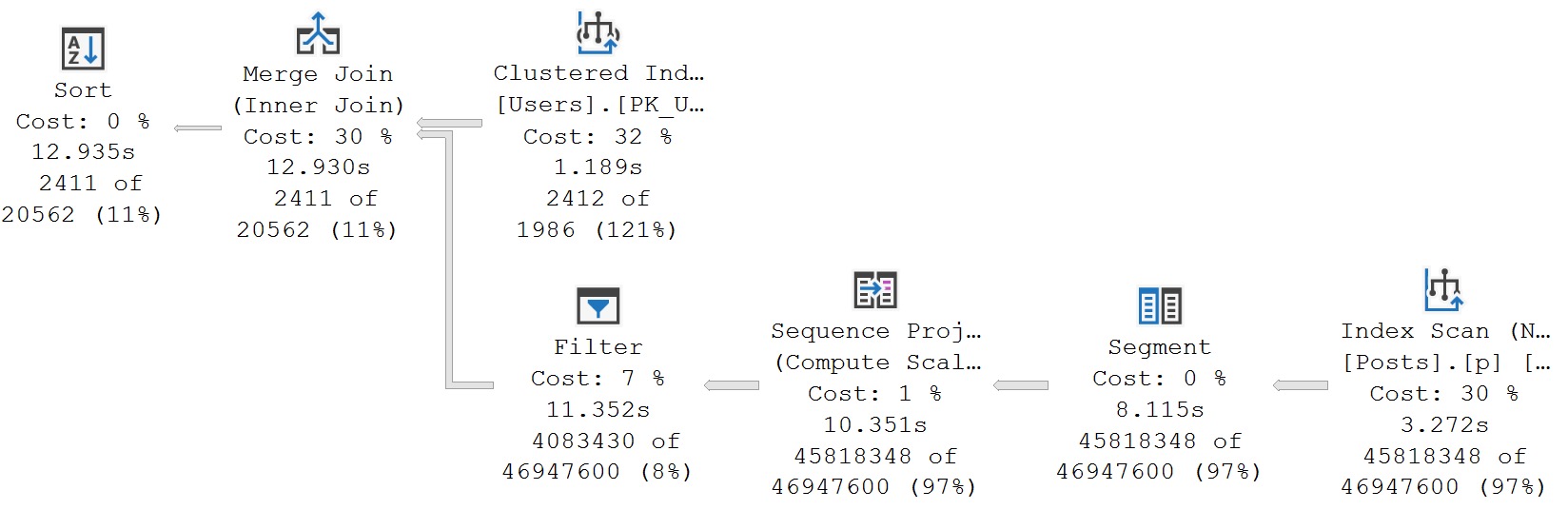
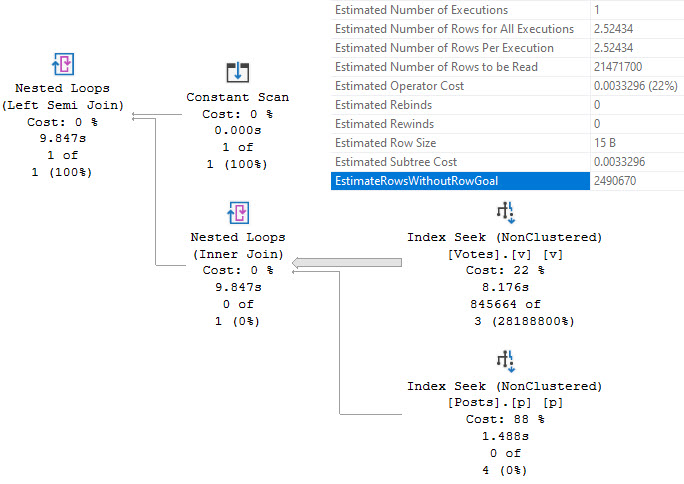
We have an index that matches our predicate, and you might think that having all that data very nicely in order would make SQL Server’s job really easy to match those columns up.
But no. No in every language.

Big ol’ index scan. Even if you try to force the matter, SQL Server says no nein nyet non and all the rest.
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p WITH(FORCESEEK)
WHERE p.OwnerUserId = p.LastEditorUserId;
Msg 8622, Level 16, State 1, Line 56 Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
Who can deal with all that?
Hail Mary
Let’s really dig our heels in and try to make this work. We’ll create an index on both columns individually and see how things go.
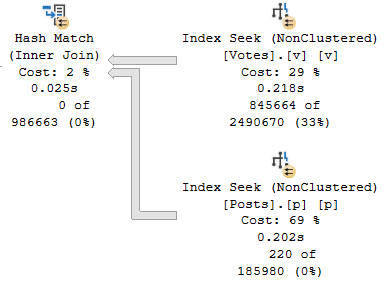
CREATE INDEX p ON dbo.Posts(OwnerUserId) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE); CREATE INDEX pp ON dbo.Posts(LastEditorUserId) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);

Just to be clear, this is horrible. You don’t want this to happen. This sucks, and if you like it you should jump in a deep, deep hole.
Ends Well
Seeks are often the best possible outcome when a small number of rows are sought. OLTP workloads are the prime candidate for seeking seeks. A seek that reads a large portion of the table isn’t necessarily agreeable.
For everyone else, there’s nothing wrong with scans. Especially with column store indexes, you shouldn’t expect seeking to a gosh darn thing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.