When you’re reading query plans, you can be faced with an overwhelming amount of information, and some of it is only circumstantially helpful.
Sometimes when I’m explaining query plans to people, I feel like a mechanic (not a Machanic) who just knows where to go when the engine makes a particular rattling noise.
That’s not the worst thing. If you know what to do when you hear the rattle next time, you learned something.
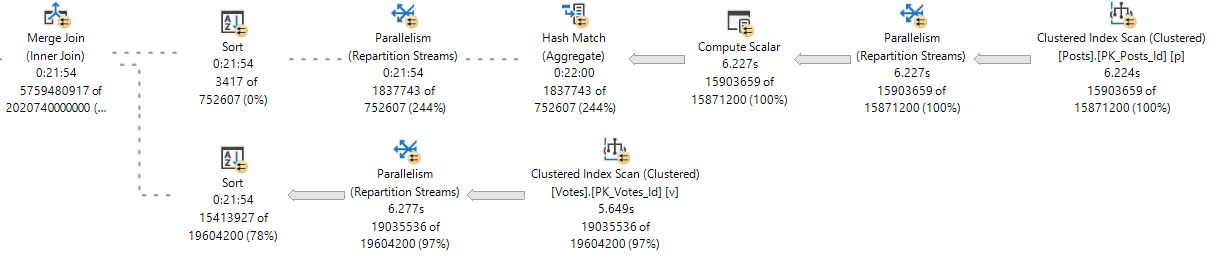
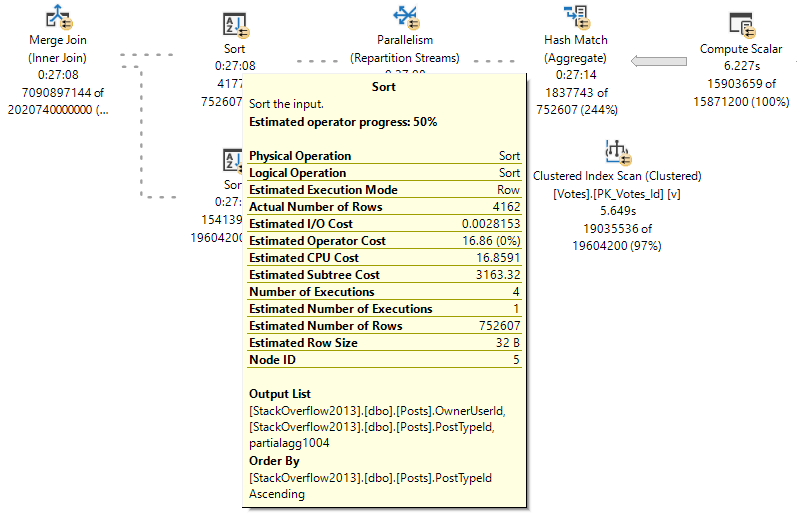
One particular source of what can be a nasty rattle is query plan operators that execute a lot.
Busy Killer Bees
I’m going to talk about my favorite example, because it can cause a lot of confusion, and can hide a lot of the work it’s doing behind what appears to be a friendly little operator.
Something to keep in mind is that I’m looking at the actual plans. If you’re looking at estimated/cached plans, the information you get back may be inaccurate, or may only be accurate for the cached version of the plan. A query plan reused by with parameters that require a different amount of work may have very different numbers.
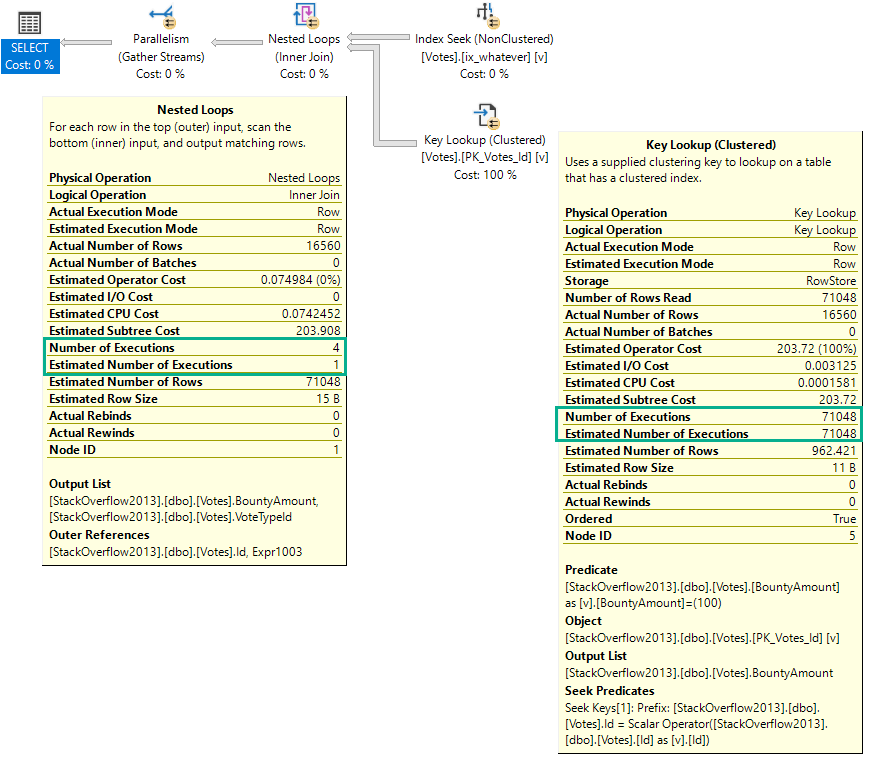
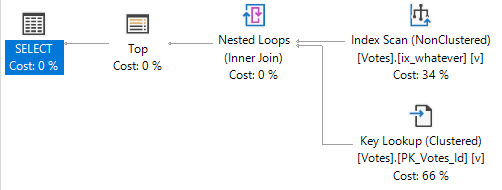
Nested Loops
Let’s look at a Key Lookup example, because it’s easy to consume.
CREATE INDEX ix_whatever ON dbo.Votes(VoteTypeId);
SELECT v.VoteTypeId, v.BountyAmount
FROM dbo.Votes AS v
WHERE v.VoteTypeId = 8
AND v.BountyAmount = 100;
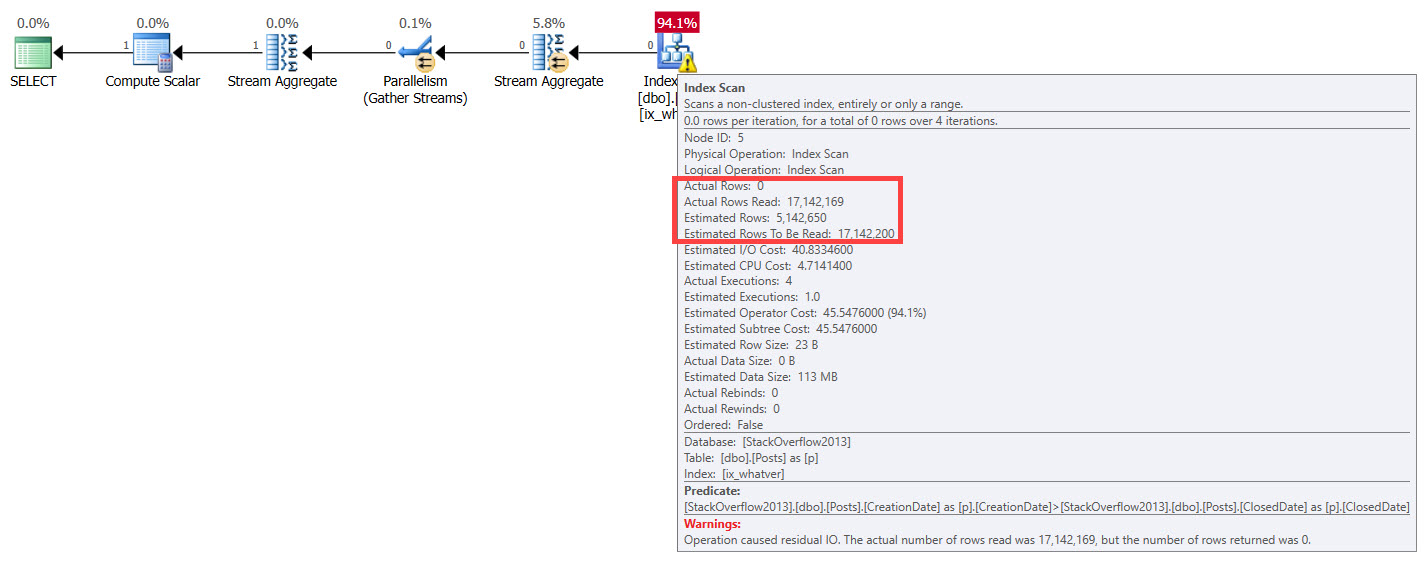
You’d think with “loops” in the name, you’d see the number of executions of the operator be the number of loops SQL Server thinks it’ll perform.
But alas, we don’t see that.
In a parallel plan, you may see the number of executions equal to the number of threads the query uses for the branch that the Nested Loops join executes in.
For instance, the above query runs at MAXDOP four, and coincidentally uses four threads for the parallel nested loops join. That’s because with parallel nested loops, each thread executes a serial version of the join independently. With stuff like a parallel scan, threads work more cooperatively.
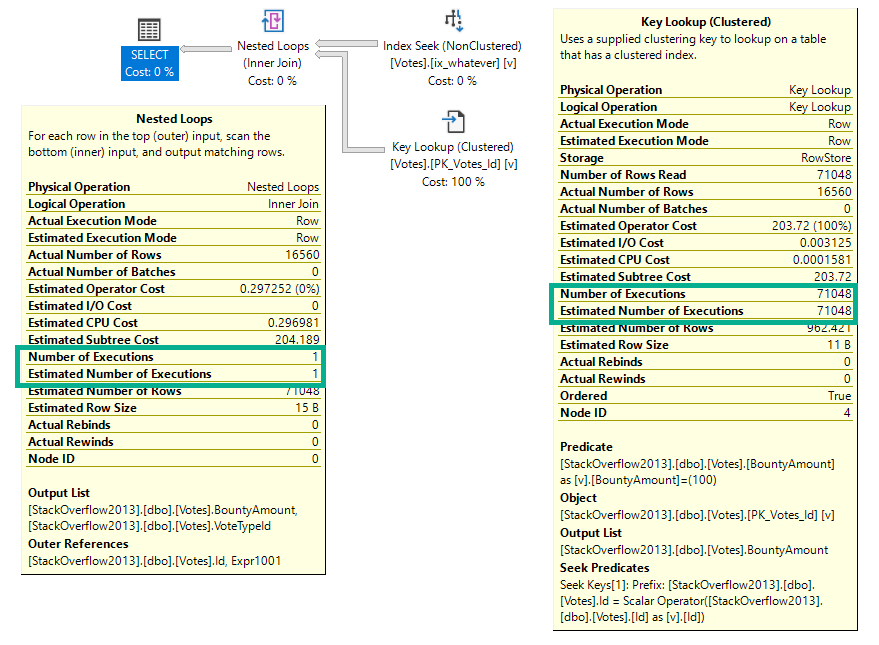
Too Much Speed
If we re-run the same query at MAXDOP 1, the number of executions drops to 1 for the nested loops operator, but remains at 71,048 for the key lookup.
Beat Feet
But here we are at the very point! It’s the child operators of the nested loops join that show how many executions there were, not the nested loops join itself.
Weird, right?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is a short post to “document” something interesting I noticed about… It’s kind of a mouthful.
See, hash joins will bail out when they spill to disk enough. What they bail to is something akin to Nested Loops (the hashing function stops running and partitioning things).
This usually happens when there are lots of duplicates involved in a join that makes continuing to partition values ineffective.
It’s a pretty atypical situation, and I really had to push (read: hint the crap out of) a query in order to get it to happen.
I also had to join on some pretty dumb columns.
Dupe-A-Dupe
Here’s a regular row store query. Bad idea hints and joins galore.
SELECT *
FROM dbo.Posts AS p
LEFT JOIN dbo.Votes AS v
ON p.PostTypeId = v.VoteTypeId
WHERE ISNULL(v.UserId, v.VoteTypeId) IS NULL
OPTION (
HASH JOIN, -- If I don't force this, the optimizer chooses Sort Merge. Smart!
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'),
MAX_GRANT_PERCENT = 0.0
);
As it runs, the duplicate-filled columns being forced to hash join with a tiny memory grant cause a bunch of problems.
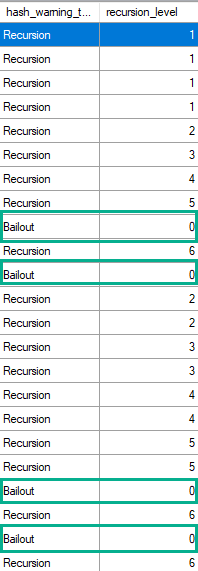
The value is a constant, hard coded in the product, and its value is five (5). This means that before the hash scan operator resorts to a sort based algorithm for any given subpartition that doesn’t fit into the granted memory from the workspace, five previous attempts to subdivide the original partition into smaller partitions must have happened.
At runtime, whenever a hash iterator must recursively subdivide a partition because the original one doesn’t fit into memory the recursion level counter for that partition is incremented by one. If anyone is subscribed to receive the Hash Warning event class, the first partition that has to recursively execute to such level of depth produces a Hash Warning event (with EventSubClass equals 1 = Bailout) indicating in the Integer Data column what is that level that has been reached. But if any other partition later also reaches any level of recursion that has already been reached by other partition, the event is not produced again.
It’s also worth mentioning that given the way the event reporting code is written, when a bail-out occurs, not only the Hash Warning event class with EventSubClass set to 1 (Bailout) is reported but, immediately after that, another Hash Warning event is reported with EventSubClass set to 0 (Recursion) and Integer Data reporting one level deeper (six).
But It’s Different With Batch Mode
If I get batch mode involved, that changes.
CREATE TABLE #hijinks (i INT NOT NULL, INDEX h CLUSTERED COLUMNSTORE);
SELECT *
FROM dbo.Posts AS p
LEFT JOIN dbo.Votes AS v
ON p.PostTypeId = v.VoteTypeId
LEFT JOIN #hijinks AS h ON 1 = 0
WHERE ISNULL(v.UserId, v.VoteTypeId) IS NULL
OPTION (
HASH JOIN, -- If I don't force this, the optimizer chooses Sort Merge. Smart!
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'),
MAX_GRANT_PERCENT = 0.0
);
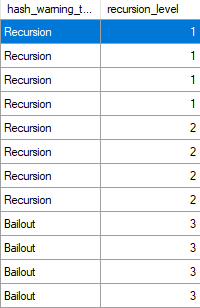
The plan yields several batch mode operations, but now we start bailing out after three recursions.
Creeky
I’m not sure why, and I’ve never seen it mentioned anywhere else.
My only guess is that the threshold is lower because column store and batch mode are a bit more memory hungry than their row store counterparts.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
They also don’t show spills. Say I’ve got a query running, and it’s taking a long time.
I’ve got live query plans turned on, so I can see what it’s up to.
21 minute salute
Hm. Well, that’s not a very full picture. What if I go get the live query plan XML myself?
SELECT deqs.query_plan
FROM sys.dm_exec_sessions AS des
CROSS APPLY sys.dm_exec_query_statistics_xml(des.session_id) AS deqs;
There are three operators showing spills so far.
Leading me on
Frosted Tips
Even if I go look at the tool tips for operators registering spills, they don’t show anything.
Do not serve this operator
It’s fine if SSMS doesn’t decide to re-draw icons with little exclamation points, but if information about runtime and rows processed can be updated in real-ish time, information about spills should be, too.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Okay, so like, an IF branch in a stored proc can be helpful to control logic, but not to control performance.
That’s the most important line in the blog post, now lemme show you why.
All Possible Permutations Thereof
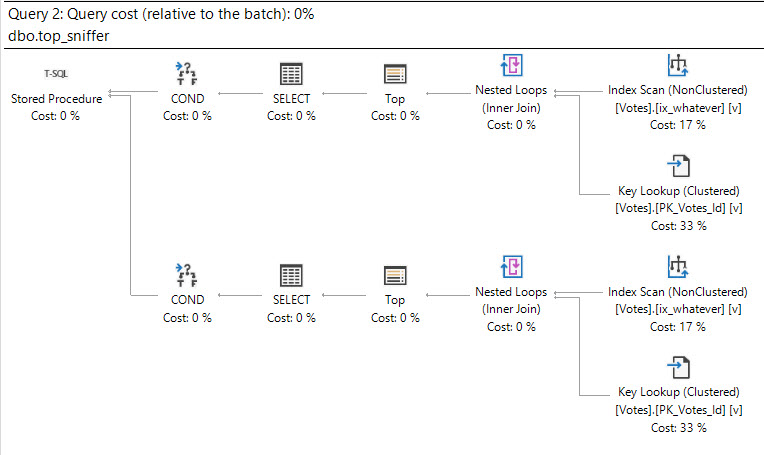
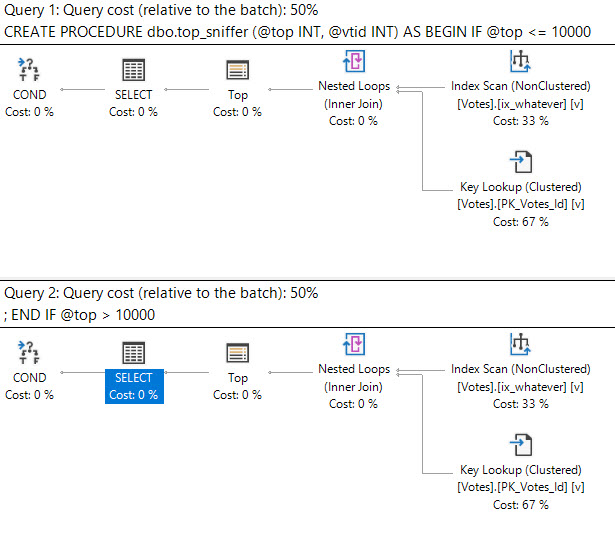
Let’s say for our stored procedure, we want to use a different plan for different TOPs, and our tipping point is 10,000.
That’s the tip of our TOP, if you will. And you will, because my name’s on the blog, pal.
CREATE OR ALTER PROCEDURE dbo.top_sniffer (@top INT, @vtid INT)
AS
BEGIN
IF @top <= 10000
BEGIN
SELECT TOP (@top)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END
IF @top > 10000
BEGIN
SELECT TOP (@top)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END
END;
Soup Sandwich
This goes quite poorly. If we just get estimated plans, here’s that they produce.
The optimizer explores both paths, and the plan cache concurs.
Dead giveaway
If you were to run it with the higher value first, you’d see the same thing for the parallel plans.
Logic, Not Performance
Making plan choices with IF branches like this plain doesn’t work.
The optimizer compiles a plan for both branches based on the initial compile value.
What you end up with is a stored proc that doesn’t do what it’s supposed to do, and parameter sniffing times two.
For a lot more information and examples, check out this Stack Exchange Q&A.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If you saw my post about parameterized TOPs, one thing you may have immediately hated is the index I created.
And rightfully so — it was a terrible index for reasons we’ll discuss in this post.
If that index made you mad, congratulations, you’re a smart cookie.
CREATE INDEX whatever ON dbo.Votes(CreationDate DESC, VoteTypeId)
GO
Yes, my friends, this index is wrong.
It’s not just wrong because we’ve got the column we’re filtering on second, but because there’s no reason for it to be second.
Nothing in our query lends itself to this particular indexing scenrio.
CREATE OR ALTER PROCEDURE dbo.top_sniffer (@top INT, @vtid INT)
AS
BEGIN
SELECT TOP (@top)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
We Index Pretty
The reason I sometimes see columns appear first in an index is to avoid having to physically sort data.
If I run the stored procedure without any nonclustered indexes, this is our query plan:
EXEC dbo.top_sniffer @top = 1, @vtid = 1;
spillo
A sort, a spill, kablooey. We’re not having any fun, here.
With the original index, our data is organized in the order that we’re asking for it to be returned in the ORDER BY.
This caused all sorts of issues when we were looking for VoteTypeIds that were spread throughout the index, where we couldn’t satisfy the TOP quickly.
There was no Sort in the plan when we had the “wrong” index added.
Primal
B-Tree Equality
We can also avoid having to sort data by having the ORDER BY column(s) second in the key of the index, because our filter is an equality.
CREATE INDEX whatever ON dbo.Votes(VoteTypeId, CreationDate DESC)
GO
Having the filter column first also helps us avoid the longer running query issue when we look for VoteTypeId 4.
EXEC dbo.top_sniffer @top = 5000, @vtid = 4;
I like you better.
Table 'Votes'. Scan count 1, logical reads 2262
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 148 ms.
Solving for Sorts
If you’ve been following my blogging for a while, you’ve likely seen me say this stuff before, because Sorts have some issues.
They’re locally blocking, in that every row has to arrive before they can run
They require additional memory space to order data the way you want
They may spill to disk if they don’t get enough memory
They may ask for quite a bit of extra memory if estimations are incorrect
They may end up in a query plan even when you don’t explicitly ask for them
There are plenty of times when these things aren’t problems, but it’s good to know when they are, or when they might turn into a problem.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A while back I promised I’d write about what allows SQL Server to perform two seeks rather than a seek with a residual predicate.
More recently, a post touched a bit on predicate selectivity in index design, and how missing index requests don’t factor that in when requesting indexes.
This post should tie the two together a bit. Maybe. Hopefully. We’ll see where it goes, eh?
If you want a TL;DR, it’s that neighboring index key columns support seeks quite easily, and that choosing the leading column should likely be a reflection of which is filtered on most frequently.
CREATE NONCLUSTERED INDEX whatever
ON dbo.Posts ( PostTypeId, ClosedDate );
CREATE NONCLUSTERED INDEX apathy
ON dbo.Posts ( ClosedDate, PostTypeId );
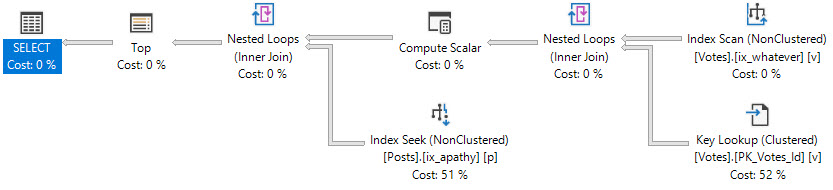
Now let’s run two identical queries, and have each one hit one of those indexes.
SELECT p.Id, p.PostTypeId, p.ClosedDate
FROM dbo.Posts AS p WITH (INDEX = whatever)
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01';
SELECT p.Id, p.PostTypeId, p.ClosedDate
FROM dbo.Posts AS p WITH (INDEX = apathy)
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01';
If you run them a bunch of times, the first query tends to end up around ~50ms ahead of the second, though they both sport nearly identical query plans.
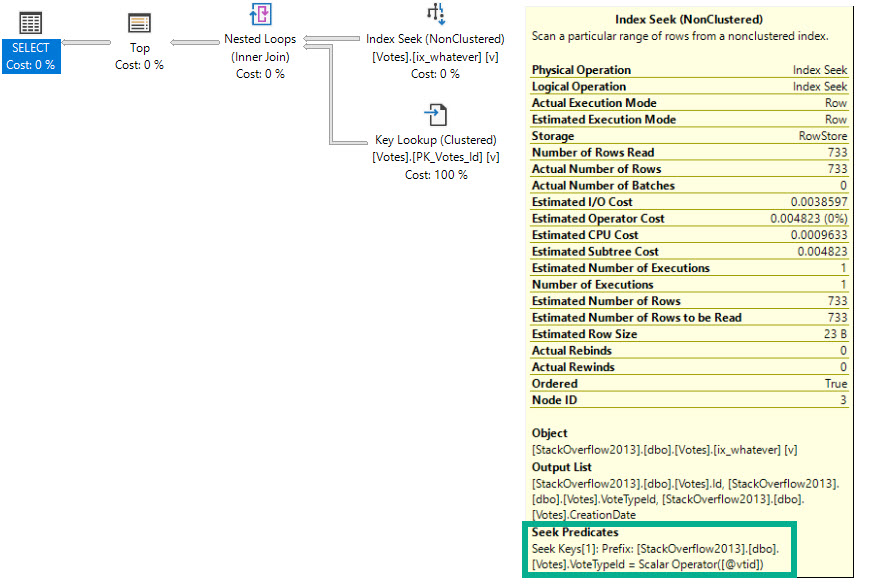
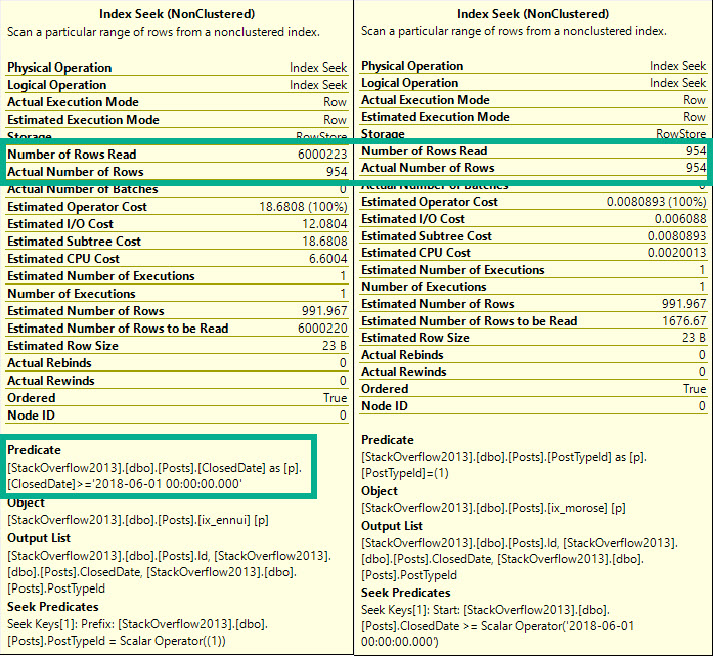
The seek may look confusing, because PostTypeId seems to appear as both a seek and a residual predicate. That’s because it’s sort of both.
The seek tells us where we start reading, which means we’ll find rows starting with ClosedDate 2018-06-01, and with PostTypeId 1.
From there, we may find higher PostTypeIds, which is why we have a residual predicate; to filter those out.
More generally, a seek can find a single row, or a range of rows as long as they’re all together. When the leading column of an index is used to find a range, we can seek to a starting point, but we need a residual predicate to check for other predicates afterwards.
This is why the index rule of thumb for many people is to start indexes with equality predicates. Any rows located will be contiguous, and we can easily continue the seek while applying any other predicates.
Seeky Scanny
There’s also differences in stats time and IO.
Table 'Posts'. Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 156 ms.
Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 106 ms.
Remember that this is how things break down for each predicate:
Lotsa and Nunna
But in neither case do we need to touch all ~6mm rows of PostTypeId 1 to locate the correct range of ClosedDates.
Downstairs Mixup
When does that change?
When we design indexes a little bit more differenter.
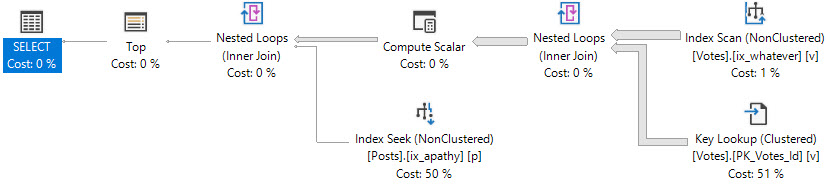
CREATE NONCLUSTERED INDEX ennui
ON dbo.Posts ( PostTypeId ) INCLUDE (ClosedDate);
CREATE NONCLUSTERED INDEX morose
ON dbo.Posts ( ClosedDate ) INCLUDE (PostTypeId);
Running the exact same queries, something changes quite drastically for the first one.
Table 'Posts'. Scan count 1, logical reads 16344, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 297 ms, elapsed time = 301 ms.
Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 187 ms.
This time, the residual predicate hurts us, when we look for a range of values.
Yaw yaw yaw
We do quite a lot of extra reads — in fact, this time we do need to touch all ~6mm rows of PostTypeId 1.
Off By One
Something similar happens if we only rearrange key columns, too.
CREATE NONCLUSTERED INDEX ennui
ON dbo.Posts ( PostTypeId, OwnerUserId, ClosedDate ) WITH ( DROP_EXISTING = ON );
CREATE NONCLUSTERED INDEX morose
ON dbo.Posts ( ClosedDate, OwnerUserId, PostTypeId ) WITH ( DROP_EXISTING = ON );
I have both columns I’m querying in the key of the index this time, but I’ve stuck a column I’m not querying at all between them — OwnerUserId.
This also throws off the range predicate. We read ~30k more pages here because the index is larger.
Table 'Posts'. Scan count 1, logical reads 19375, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 312 ms, elapsed time = 314 ms.
Table 'Posts'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 178 ms.
The Seeks here look identical to the ones when I had columns in the include section of the index.
What’s It All Mean?
Index column placement, whether it’s in the key or in the includes, can have a non-subtle impact on reads, especially when we’re searching for ranges.
Even when we have a non-selective leading column like PostTypeId with an equality predicate on it, we don’t need to read every single row that meets the filter to apply a range predicate, as long as that predicate is seek-able.
When we move the range column to the includes, or we add a column before it in the key, we end up doing a lot more work to locate rows.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In yesterday’s post, we looked at how row goals affected performance when data matching our join and where clauses didn’t exist.
Today we’re going to look at something similar, and perhaps a workaround to avoid the same issues.
Here’s our index setup:
CREATE INDEX whatever ON dbo.Votes(CreationDate DESC, VoteTypeId)
GO
Now we’re gonna wrap our query in a stored procedure.
CREATE OR ALTER PROCEDURE dbo.top_sniffer (@top INT, @vtid INT)
AS
BEGIN
SELECT TOP (@top) v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
Video Killed MTV
You know what? I don’t wanna write all this stuff. Let’s do a video.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Over in the Votes table in the Stack Overflow database, a couple of the more popular vote types are 1 and 2.
A vote type of 1 means that an answer was accepted as being the solution by a user, and a vote type of 2 means someone upvoted a question or answer.
I Voted!
What this means is that it’s impossible for a question to ever have an accepted answer vote cast for it. A question can’t be an answer, here.
Unfortunately, SQL Server doesn’t have a way of inferring that.
ANSWER ME!
Anything with a post type id of 1 is a question.
The way the tables are structured, VoteTypeId and PostTypeId don’t exist together, so we can’t use a constraint to validate any conditions that exist between them.
VotanPostan
Lost And Found
When we run a query that looks for posts with a type of 2 (that’s an answer) that have a vote type of 1, we can find 2500 of them relatively quickly.
SELECT TOP (2500)
p.OwnerUserId,
p.Score,
p.Title,
v.CreationDate,
ISNULL(v.BountyAmount, 0) AS BountyAmount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 2 --WHERE VoteTypeId = 2
AND p.PostTypeId = 1
ORDER BY v.CreationDate DESC;
Here’s the stats:
Table 'Posts'. Scan count 0, logical reads 29044
Table 'Votes'. Scan count 1, logical reads 29131
SQL Server Execution Times:
CPU time = 63 ms, elapsed time = 272 ms.
And here’s the plan:
Nelly.
Colossus of Woes
Now let’s ask SQL Server for some data that doesn’t exist.
SELECT TOP (2500)
p.OwnerUserId,
p.Score,
p.Title,
v.CreationDate,
ISNULL(v.BountyAmount, 0) AS BountyAmount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 1 --Where VoteTypeId = 1
AND p.PostTypeId = 1
ORDER BY v.CreationDate DESC;
Here’s the stats:
Table 'Posts'. Scan count 0, logical reads 11504587
Table 'Votes'. Scan count 1, logical reads 11675392
SQL Server Execution Times:
CPU time = 14813 ms, elapsed time = 14906 ms.
You could say things got “worse”.
Not only that, but they got worse for the exact same plan.
Argh.
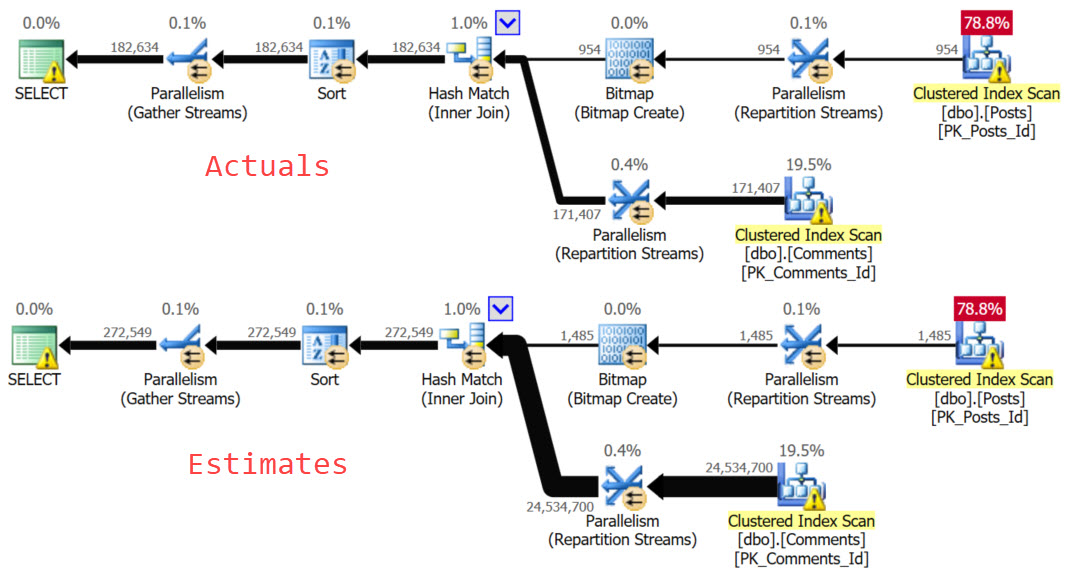
So What Happened?
In the original plan, the TOP asked for rows, and quickly got them.
In the second plan, the TOP kept asking for rows, getting them from the Votes table, and then losing them on the join to Posts.
There was no parameter sniffing, there were no out of date stats, no blocking, or any other oddities. It’s just plain bad luck because of the data’s relationship.
If we apply hints to this query to:
Scan the clustered index on Votes
Choose Merge or Hash joins instead of Nested Loops
Force the join order as written
We get much better performing queries. The plan we have is chosen because the TOP sets a row goal that makes a Nested Loops plan using narrow (though not covering) indexes attractive to the optimizer. When it’s right, like in the original query, you probably don’t even think about it.
When it’s wrong, like in the second query, it can be quite mystifying why such a tiny query can run forever to return nothing.
If you want to try it out for yourself, use these indexes:
CREATE INDEX whatever
ON dbo.Votes( CreationDate, VoteTypeId, PostId );
CREATE NONCLUSTERED INDEX apathy
ON dbo.Posts ( PostTypeId )
INCLUDE ( OwnerUserId, Score, Title );
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Since I know this’ll come out Friday, I get to have fun.
I have a feeling most of you know what Candy Crush is. It’s a mindless, infinite thumb scroll replacement.
When you’re playing, Candy Crush will suggest moves to you. It thinks they’re good ideas. Though I don’t know what the algorithm is, it seems to recommend some goofy stuff.
Take this example. It wants me to move the orange piece. It’s not a bad move, but it’s not the best possible move.
Savvy Candy Crush players will see the obvious choice. Make five in a row with the purple pieces, get the cookie thing, cookie thing drops down next to the explodey thing, and when you combine it with the wrapped candy thing, all the purple pieces turn into explodey pieces.
Level over, basically.
But Candy Crush isn’t thinking that far ahead. Neither are missing index requests.
SQL Server Does The Same Thing
Let’s take this query, for example. It’s very Post-centric.
SELECT p.OwnerUserId, p.Score, p.Title
FROM dbo.Comments AS c
JOIN dbo.Posts AS p
ON p.OwnerUserId = c.UserId
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01'
ORDER BY p.Score DESC;
Right now, the only indexes I have are clustered, and they’re not on any columns that help this query. Sure, they help other things, and having clustered indexes is usually a good idea.
This is the home run use-case for nonclustered indexes. You know. Organized copies of other parts of your data that users might query.
This is such an obvious move that SQL Server is all like “hey, got a minute?”
This is where things get all jumpy-blinky. Just like in Candy Crush.
Hints-a-Hints
This is the index SQL Server wants:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Posts] ([PostTypeId],[ClosedDate])
INCLUDE ([OwnerUserId],[Score],[Title])
Would this be better than no index? Yes.
Is it the best possible index? No. Not by a long shot.
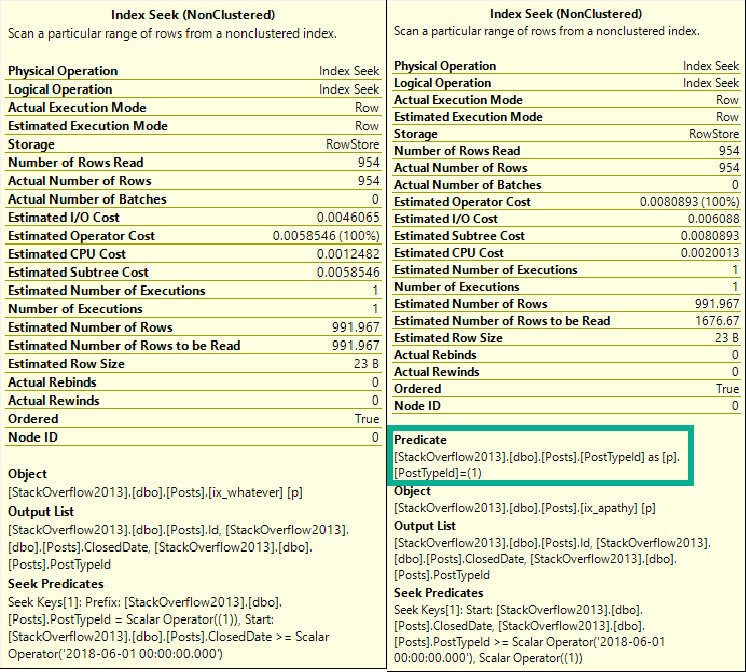
Let’s start with our predicates. SQL Server picked PostTypeId as the leading key column.
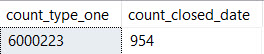
SELECT SUM(CASE p.PostTypeId WHEN 1 THEN 1 ELSE 0 END) AS [count_type_one],
SUM(CASE WHEN p.ClosedDate >= '2018-06-01' THEN 1 ELSE 0 END) AS count_closed_date
FROM dbo.Posts AS p
Is it selective?
That ain’t good
Regardless of selectivity, the missing index request mechanism will always put equality predicates first.
What I’m getting at is that the missing index request isn’t as well thought out as a lot of people hope. It’s just one possible index for a query weighted to helping us find data in the where clause.
With a human set of eyes on it, you may discover one or more better possible indexes. You may even discover one on for the Comments table, too.
Other Issues
There’s also the issue of the included columns it chose. We’re ordering by Score. We’re joining on OwnerUserId.
Those may be helpful as key columns, depending on how much data we end up joining, and how much data we end up sorting.
Guesses. Just guesses.
Complicated Game
If you don’t have anyone doing regular index tuning, missing index hints are worth following because they’re better than nothing.
They’re like… acceptable. Most of the time.
The big things you have to watch out for are the incredibly wide requests, duplicative requests, and ones that want big string columns.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You can read a lot about how indexes might improve queries.
But there are certain query mechanics that indexes don’t solve for, and you can not only get stuck with an index that isn’t really helping, but all the same query problems you were looking to solve.
Understanding how indexes and queries interact together is a fundamental part of query tuning.
In this post, we’re going to look at some query patterns that indexes don’t do much to fix.
Part Of The Problem
Indexes don’t care about your queries. They care about storing data in order.
There are very definite ways that you can encourage queries to use them efficiently, and probably even more definite ways for you to discourage them from using them efficiently.
Even with syntax that seems completely transparent, you can get into trouble.
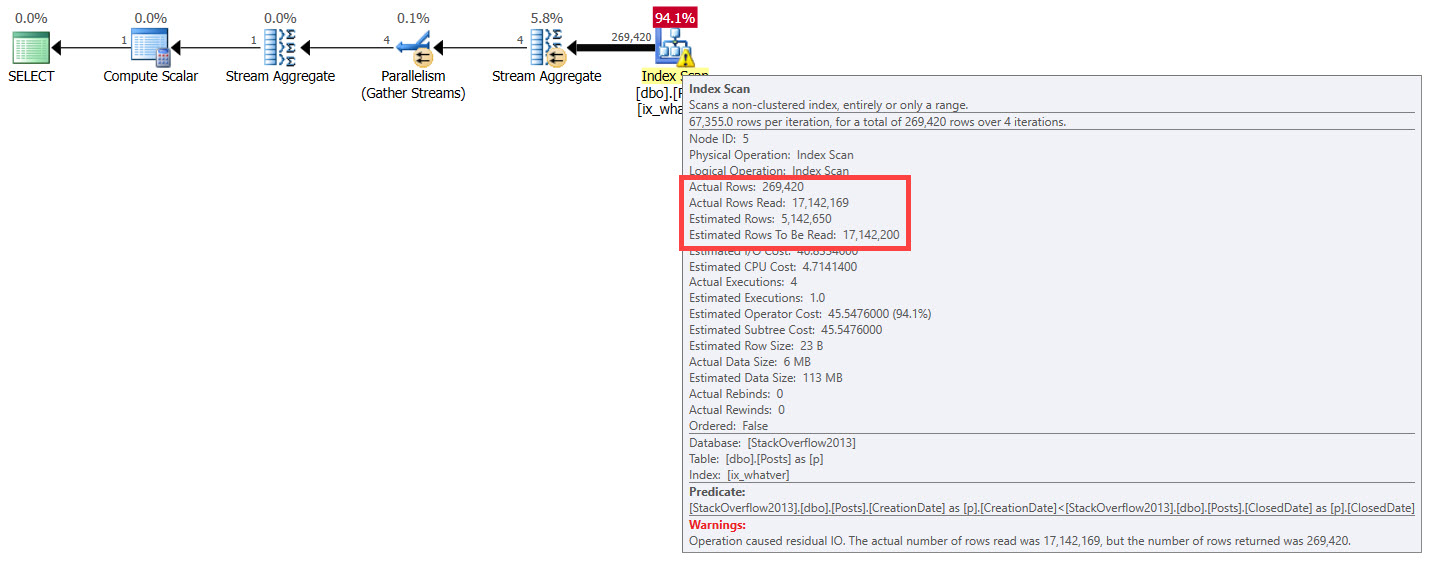
Take the simple example of two date columns: there’s nothing in your index that tracks how two dates in a row relate to each other.
Nothing tracks how many years, months, weeks, days, hours, minutes, seconds, milliseconds, or whatever magical new unit Extended Events has to make itself less usable.
Heck, it doesn’t even track if one is greater or less than another.
Soggy Flautas
Ah, heck, let’s stick with Stack Overflow. Let’s even create an index.
CREATE INDEX whatever
ON dbo.Posts(CreationDate, ClosedDate);
Now let’s look at these super important queries.
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate < p.ClosedDate;
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate > p.ClosedDate;
How much work will the optimizer think it has to do, here? How many rows will it estimate? How will it treat different queries, well, differently? If you said “it won’t”, you’re a smart cookie. Aside from the “Actual rows”, each plan has the same attributes across.
And I’m Homosapien like youAnd we’re Homosapien too
Treachery
Neither of these query plans is terrible on its own.
The problem is really in larger plans, where bad decisions like these have their way with other parts of a query plan.
Nasty little lurkers they are, because you expect things to get better when creating indexes and writing SARGable predicates.
Yet for both queries, SQL Server does the same thing, based on the same guesses on the perceived number of rows at play. It’s one of those quirky things — if it’s a data point we care about, then it’s one we should express somehow.
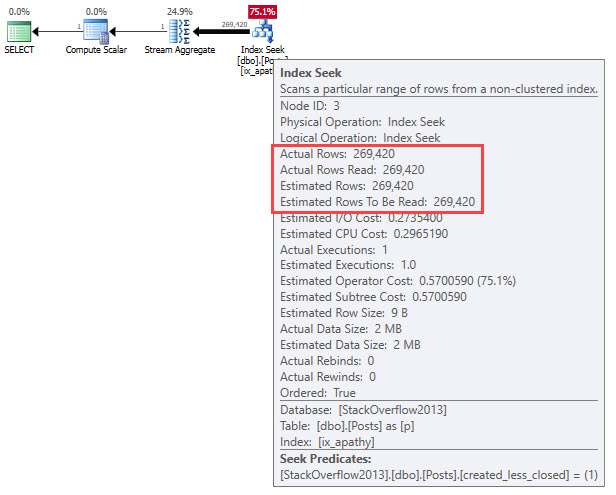
A computed column might work here:
ALTER TABLE dbo.Posts
ADD created_less_closed AS
CONVERT(BIT, CASE WHEN CreationDate < ClosedDate
THEN 1
WHEN CreationDate > ClosedDate
THEN 0
END)
CREATE INDEX apathy
ON dbo.Posts (created_less_closed);
Which means we’d have to change our queries a bit, since expression matching has a hard time reasoning this one out:
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE 1 = CONVERT(BIT, CASE WHEN CreationDate < ClosedDate
THEN 1
WHEN CreationDate > ClosedDate
THEN 0
END)
AND 1 = (SELECT 1);
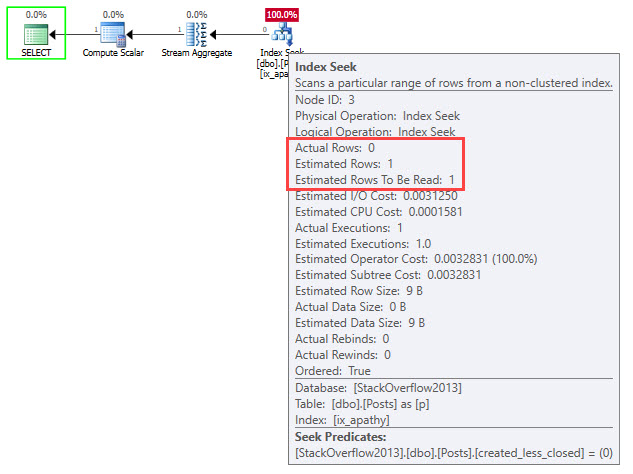
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE 0 = CONVERT(BIT, CASE WHEN CreationDate < ClosedDate
THEN 1
WHEN CreationDate > ClosedDate
THEN 0
END)
AND 1 = (SELECT 1);
BetterButter
What Would Be Better?
Practically speaking, it isn’t the job of an index (or statistic) to track things like this. We need to have data that represents things that are important to users.
Though neither of these plans is terrible in isolation, bad guesses like these flow all through query plans and can lead to other bad decisions and oddities.
It’s one of those terrible lurkers just waiting to turn an otherwise good query into that thing you regard with absolute loathing every time it shows up in [your favorite monitoring tool].
Knowing this, we can start to design our data to better reflect data points we care about. A likely hero here is a computed column to return some value based on which is greater, or a DATEDIFF of the two columns.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.