Indexes are good for so much more than what they’re given credit for by the general public.
One example where indexes can be useful is with the oft-maligned table variable.
Now, they won’t help you get a better estimate from a table variable. In versions prior to the upcoming 2019 release, table variables will only net you a single row estimate.
Yes, you can recompile to get around that. Yes, you can use a trace flag to occasionally be helpful with that.
Those defenses are inadequate, and you know it.
Help How?
Let’s say we have this query against a table variable.
SELECT u.DisplayName, b.Date
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP 1 *
FROM @waypops AS w
WHERE u.Id = w.UserId
ORDER BY w.Date DESC
) AS b
WHERE u.Reputation >= 100000;
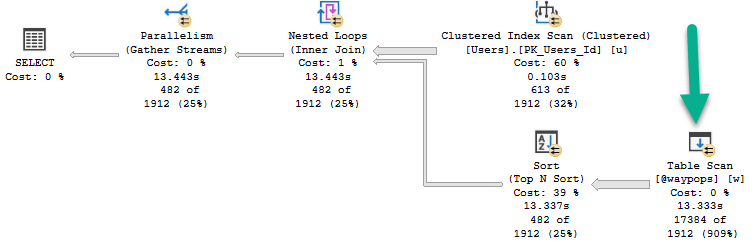
With an unindexed table variable, the plan looks like this:
Sucko
You can see by the helpful new operator time stats in SSMS 18 that this query runs for 13.443 seconds.
Of that, 13.333 seconds is spent scanning the table variable. Bad guess? You bet.
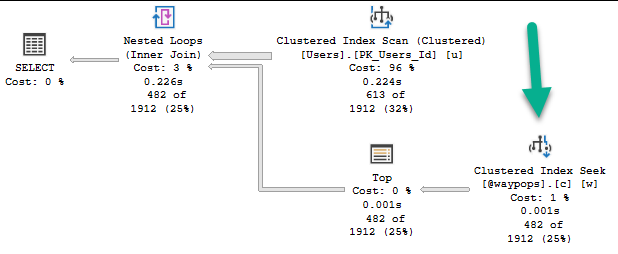
If we change the table variable definition to include an index, the plan changes, and runs much faster.
Holla holla
The query no longer goes parallel, but it runs for 226ms.
A significant change aside from parallelism is that the Top operator is no longer a Top N Sort.
The clustered index has put the table variable data in useful order for our query.
Insertions
The table variable insert looks like this:
DECLARE @waypops TABLE
(
UserId INT NOT NULL,
Date DATETIME NOT NULL
--, INDEX c CLUSTERED(UserId, Date DESC)
);
INSERT @waypops
(UserId, Date)
SELECT b.UserId, b.Date
FROM dbo.Badges AS b
WHERE b.Name IN ( N'Popular Question')
UNION ALL
SELECT b.UserId, b.Date
FROM dbo.Badges AS b
WHERE b.Name IN (N'Notable Question' )
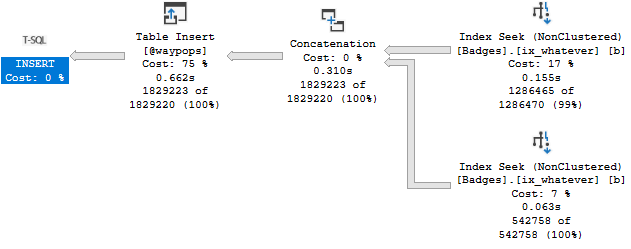
Right now, I’ve got the index definition quoted out. The insert runs for .662ms.
Oh Boy
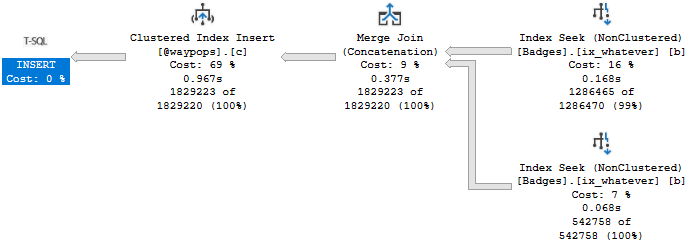
The insert with the index in place runs for .967ms:
Grab an umbrella
Given the 13 second improvement to the final query, I’ll take the ~300ms hit on this one.
Wierda
If you’re wondering why I’ve got the insert query broken up with a UNION ALL, it’s because the alternative really sucks:
DECLARE @waypops TABLE
(
UserId INT NOT NULL,
Date DATETIME NOT NULL
, INDEX c CLUSTERED(UserId, Date DESC)
);
INSERT @waypops
(UserId, Date)
SELECT b.UserId, b.Date
FROM dbo.Badges AS b
WHERE b.Name IN ( N'Popular Question', N'Notable Question')
@_@
This insert takes 1.4 seconds, and introduces a spilling sort operator.
So uh, don’t do that IRL.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A lot has been written about “kitchen sink” queries. A couple of my favorites are by Aaron Bertrand and Gail Shaw.
Both articles have similar start and end points. But I’m going to start at an even worse point.
Catch All Parameters
This is the worst possible idea.
CREATE OR ALTER PROCEDURE dbo.AwesomeSearchProcedure (@SearchString NVARCHAR(MAX))
AS
SET NOCOUNT, XACT_ABORT ON;
SET STATISTICS TIME, IO OFF;
BEGIN
DECLARE @AltString NVARCHAR(MAX) = N'%'
SELECT TOP (1000) p.OwnerUserId, p.Title, p.CreationDate, p.LastActivityDate, p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId LIKE ISNULL(N'%' + @SearchString + N'%', @AltString)
OR p.Title LIKE ISNULL(N'%' + @SearchString + N'%', @AltString)
OR p.CreationDate LIKE ISNULL(N'%' + @SearchString + N'%', @AltString)
OR p.LastActivityDate LIKE ISNULL(N'%' + @SearchString + N'%', @AltString)
OR p.Body LIKE ISNULL(N'%' + @SearchString + N'%', @AltString);
END;
GO
It doesn’t get any better if you do this, either.
SELECT TOP (1000) p.OwnerUserId, p.Title, p.CreationDate, p.LastActivityDate, p.Body
FROM dbo.Posts AS p
WHERE (p.OwnerUserId LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.Title LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.CreationDate LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.LastActivityDate LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.Body LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL);
Sample Run
In both cases, just searching for a single value results in a query that runs for >2 minutes.
EXEC dbo.AwesomeSearchProcedure @SearchString = N'35004';
GO
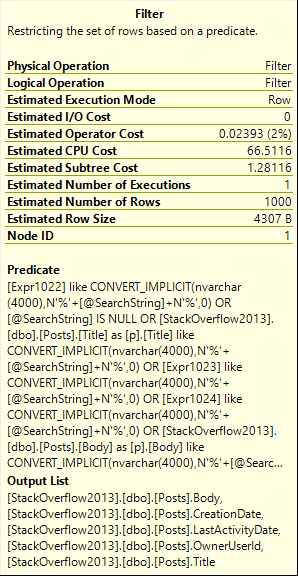
The problem is that we’re just searching for an OwnerUserId, but SQL Server doesn’t know that.
The query plan looks like this:
Badness
See that Filter? That’s where we do all of our search work. We scan the whole Posts table, and push every row across the pipe to the Filter.
Messy
Irritable
This pattern might work on a small amount of data, but like most things that are efficient in small doses this will quickly fall apart when your database reaches a mature size.
My example is pretty simple, too, just hitting one table. In real life, you monsters are going this across joins, throwing in row numbers, distincts, and ordering by the first 10 columns.
It only gets worse as it gets more complicated.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I recently came across a bad locking problem. It was one of those things that happened “suddenly” and “for no reason”.
When I looked at the stored procedure, the code was something like this:
CREATE PROCEDURE dbo.bad_news(@PostTypeId INT)
AS
BEGIN
DECLARE @PTID INT
SELECT @PTID = CASE WHEN @PostTypeId < 1
OR @PostTypeId > 8
THEN 4
END
UPDATE p
SET p.Score += 1
FROM dbo.Posts AS p
WHERE p.PostTypeId = @PTID;
END
I mean, it would look like that if we were using Stack Overflow.
We weren’t, but I’ll leave the rest to your imagination.
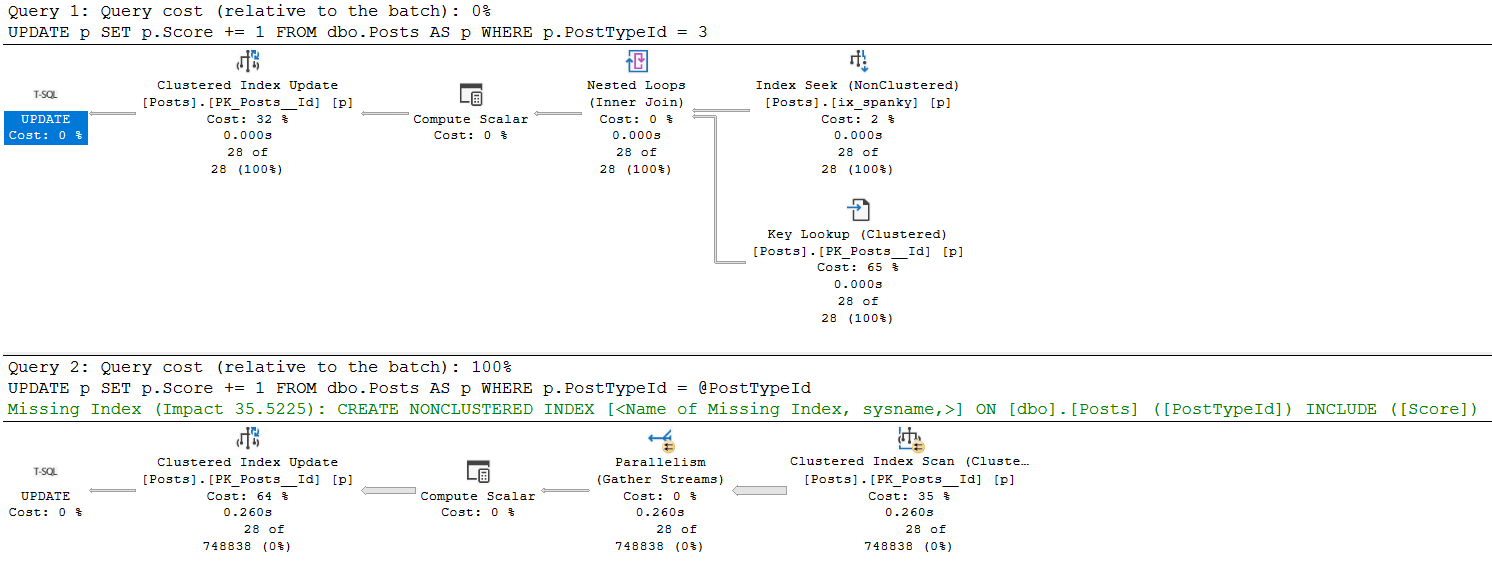
Outside The Proc
We have this index:
CREATE INDEX ix_spanky ON dbo.Posts(PostTypeId);
Let’s run this code, and look at what happens.
BEGIN TRAN
UPDATE p
SET p.Score += 1
FROM dbo.Posts AS p
WHERE p.PostTypeId = 3;
ROLLBACK
We not only have exclusive locks on pages, but on the entire table now.
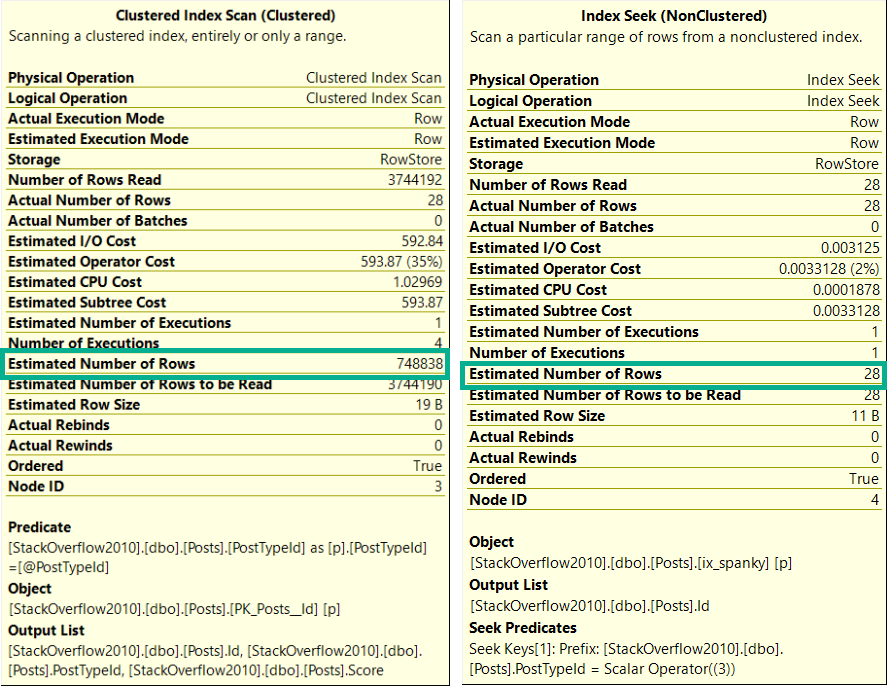
Overestimaters Anonymous
The execution plans for these two queries are much different.
umop
Likewise, the estimates are much different.
upside
Oh So Loco
This is a fairly well-documented outcome of using a “declared variable”, or the optimize for unknown hint.
The optimizer makes a usually-generally-bad guess at the number of rows it’ll have to deal with.
In this case, the stored procedure had been modified to account for bad values passed in from the application.
The outcome was severe blocking because modification queries were taking far more intrusive locks than necessary.
So, you know, don’t do that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There’s a wonderful explanation from Paul White about spill levels here. At the risk of offending the copyright godses, I’m going to quote it here.
Consider the task of sorting 4000MB of data, when we only have 500MB of memory available. Obviously, we cannot sort the whole set in memory at once, but we can break the task down:
We first read 500MB of data, sort that set in memory, then write the result to disk. Performing this a total of 8 times consumes the entire 4000MB input, resulting in 8 sets of sorted data 500MB in size. The second step is to perform an 8-way merge of the sorted data sets. Note that a merge is required, not a simple concatenation of the sets since the data is only guaranteed to be sorted as required within a particular 500MB set at the intermediate stage.
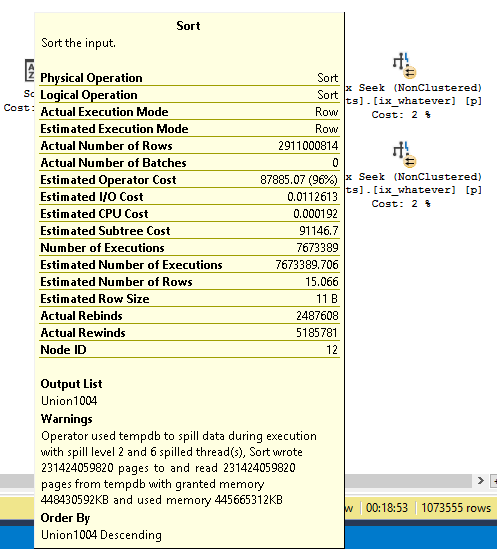
Alright, interesting! That’d make me think that the number of pages involved in the spill would increase the spill level. In real life, I saw spill level 11 once. I wish I had that plan saved.
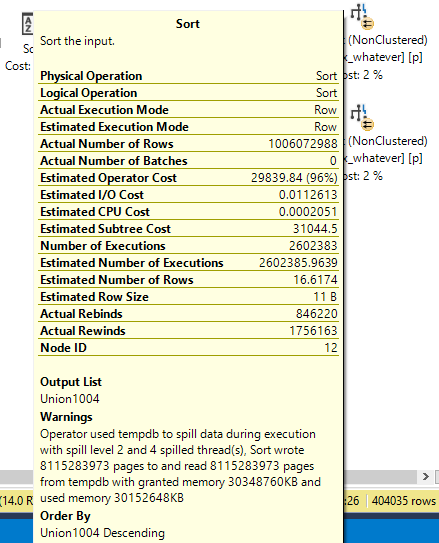
Rowed To Nowhere
Here’s a pretty big spill. But it’s only at level two.
Insert commas.
That’s 8,115,283,973 rows.
Here’s a much larger spill that’s still only at level two.
Insert more commas.
That’s um… hang on.
231,424,059,820 rows. It’s crazy that we can add 223,308,775,847 rows to a spill and not need more passes than before.
But hey, okay. That’s cool. I get it.
Waaaaaiiiiitttt
I found level three! With uh 97,142 pages. That’s weird. I don’t get it.
But whatever, it probably can’t get much weirder than
…
SPILL LEVEL 8 FOR 43,913 PAGES 1-800-COME-ON-YO!
This Is Gonna Take More Digging
I’m gonna have my eye on weird spill levels from now on, and I’ll try to follow up as I figure stuff out.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s say we’ve got a simple update query. When we run it, it finishes instantly, and the query plan has no surprises.
BEGIN TRAN
UPDATE u
SET u.Reputation = 2147483647
FROM dbo.Users AS u
WHERE u.Id = 22656;
ROLLBACK
One to the two
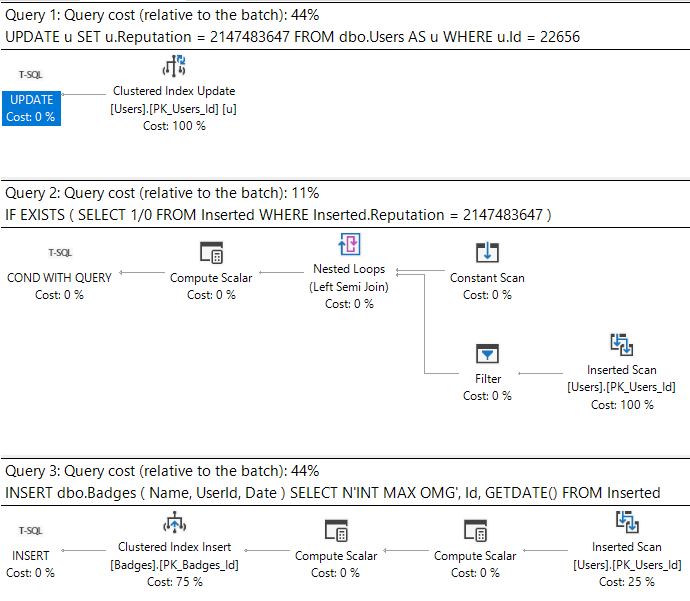
Then one day DevOps comes along and says that every time Reputation gets updated in the Users table, we have to check a bunch of conditions and then do a bunch of stuff based on the value.
One of those checks is to see if anyone has the ?INT MAX? and then insert a row into Badges.
Because I’m lazy (Agile?), I’m going to stick a waitfor in the trigger to simulate all the other checks and actions.
CREATE OR ALTER TRIGGER dbo.one_time
ON dbo.Users
AFTER UPDATE
AS
BEGIN
IF EXISTS ( SELECT 1/0
FROM Inserted
WHERE Inserted.Reputation = 2147483647 )
INSERT dbo.Badges ( Name, UserId, Date )
SELECT N'INT MAX OMG', Id, GETDATE()
FROM Inserted
WAITFOR DELAY '00:00:10.000'
END;
GO
Less Simpler Times
Now when we run our update, the plan looks like this.
Ass-mar
What’s important here is that we can see the work associated with the triggers.
What sucks is when we look at the plan cache.
Back To Easy
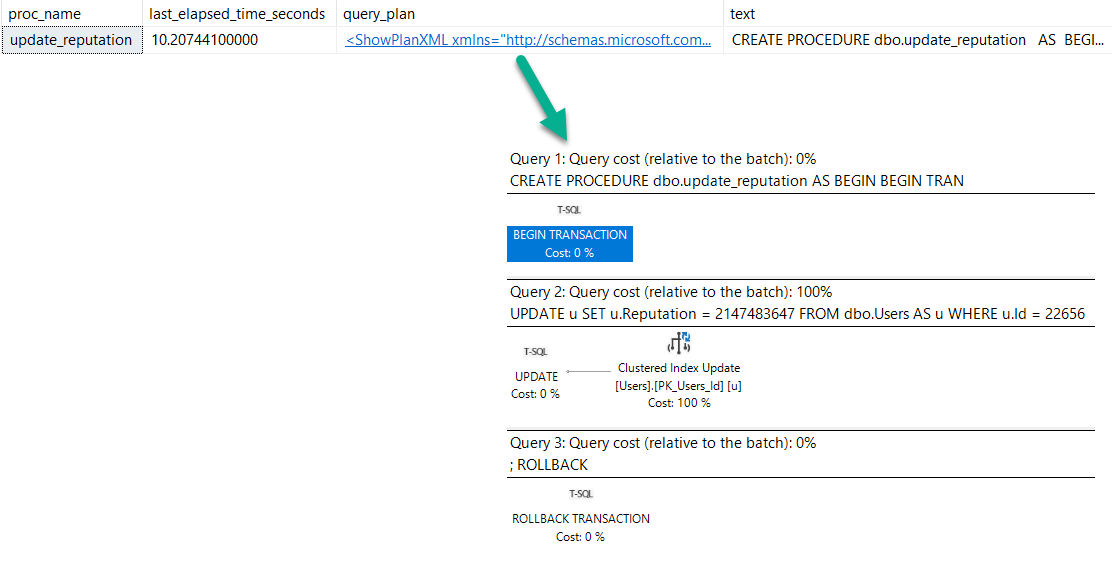
I’m gonna stick that update in a stored procedure to make life a little easier when we go looking for it.
CREATE PROCEDURE dbo.update_reputation
AS
BEGIN
BEGIN TRAN
UPDATE u
SET u.Reputation = 2147483647
FROM dbo.Users AS u
WHERE u.Id = 22656;
ROLLBACK
END;
After running the proc, here’s what we get back from the plan cache.
SELECT OBJECT_NAME(deps.object_id) AS proc_name,
deps.last_elapsed_time / 1000. / 1000. AS last_elapsed_time_seconds,
deqp.query_plan,
dest.text
FROM sys.dm_exec_procedure_stats AS deps
CROSS APPLY sys.dm_exec_query_plan(deps.plan_handle) AS deqp
CROSS APPLY sys.dm_exec_sql_text(deps.plan_handle) AS dest
WHERE deps.object_id = OBJECT_ID('dbo.update_reputation');
Investigative Reports
We have a procedure reporting that it ran for 10 seconds (which it did, sort of…).
But no mention of the trigger. Hm.
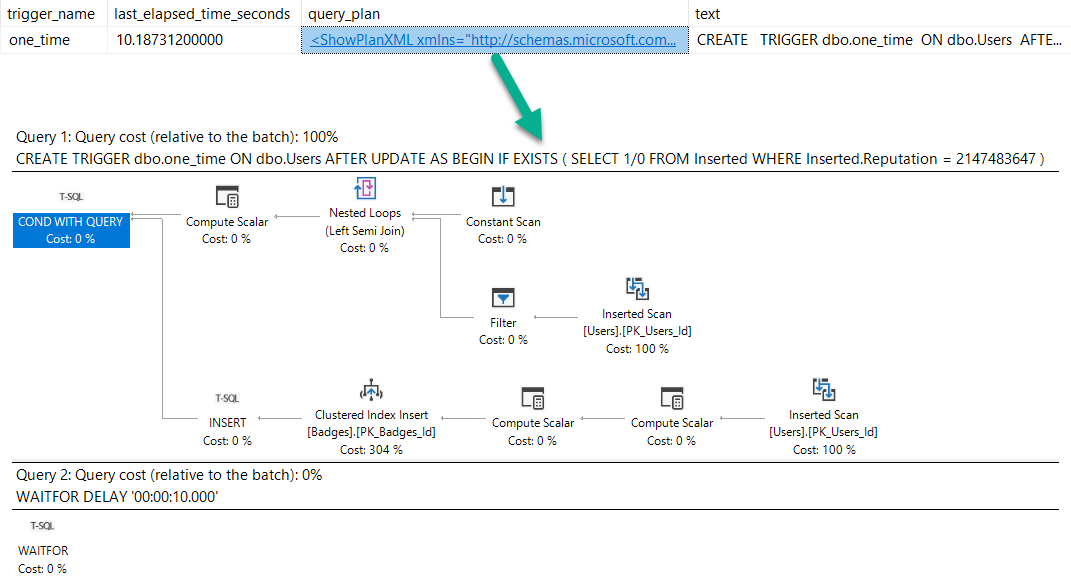
Of course, we can get this information from trigger stats, but we’d have to know to go looking:
SELECT OBJECT_NAME(object_id) AS trigger_name,
dets.last_elapsed_time / 1000. / 1000. AS last_elapsed_time_seconds,
deqp.query_plan,
dest.text
FROM sys.dm_exec_trigger_stats AS dets
CROSS APPLY sys.dm_exec_query_plan(dets.plan_handle) AS deqp
CROSS APPLY sys.dm_exec_sql_text(dets.plan_handle) AS dest
WHERE OBJECT_ID = OBJECT_ID('dbo.one_time');
Get busy
Lying Liars
When seemingly simple modification queries take a long time, things may not be as simple as they appear.
Blocking, and triggers might be at play. Unfortunately, there’s not a great way of linking any of that together right now.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This isn’t quite about the same thing, just about some behavior that I thought was interesting, and how it changes between cardinality estimator versions.
Bad Robot
If you’ve been query tuning for a while, you probably know about SARGability, and that wrapping columns in functions is generally a bad idea.
But just like there are slightly different rules for CAST and CONVERT with dates, the repercussions of the function also vary.
The examples I’m going to look at are for YEAR() and MONTH().
If you want a TL;DR, here you go.
Reality Bites
If you wanna keep going, follow me!
USING
The takeaway here isn’t that doing either of these is okay. You should fully avoid wrapping columns in functions in general.
One of the main problems with issuing queries with non-SARGable predicates is that the people who most often do it are the people who rely on missing index requests to direct tuning efforts, and non-SARGable queries can prevent those requests from surfacing, or ask for an even more sub-optimal index than usual.
If you have a copy of the StackOverflow2013 database, you can replicate the results pretty easily on SQL Server 2017.
They may be slightly different depending on how the histogram is generated, but the overarching theme is the same.
Yarly
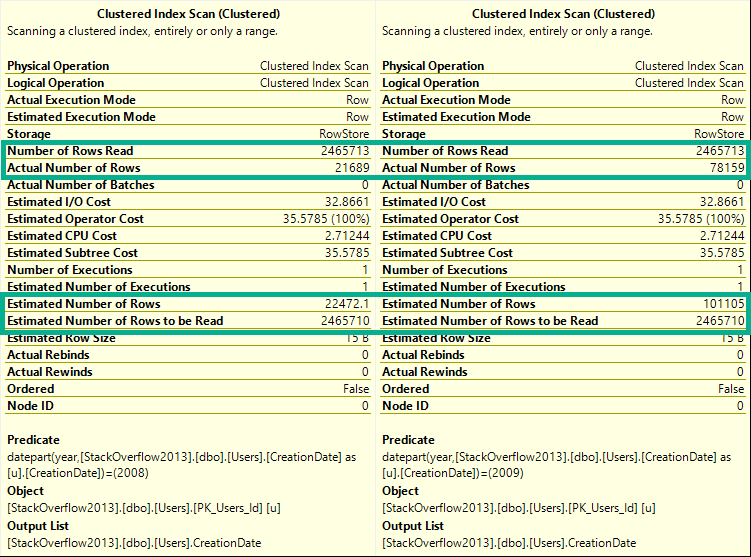
If you run these queries, and look at the estimated and actual rows in the Clustered Index scan tooltip, you’ll see they change for every query.
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2008;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2009;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2010;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2011;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2012;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2013;
GO
Here’s a sample from the 2008 and 2009 queries.
Wild For The Night
ED: I took a break from writing this and “went to brunch”.
Any logical inconsistencies will work themselves out eventually.
Cash Your Checks And Come Up
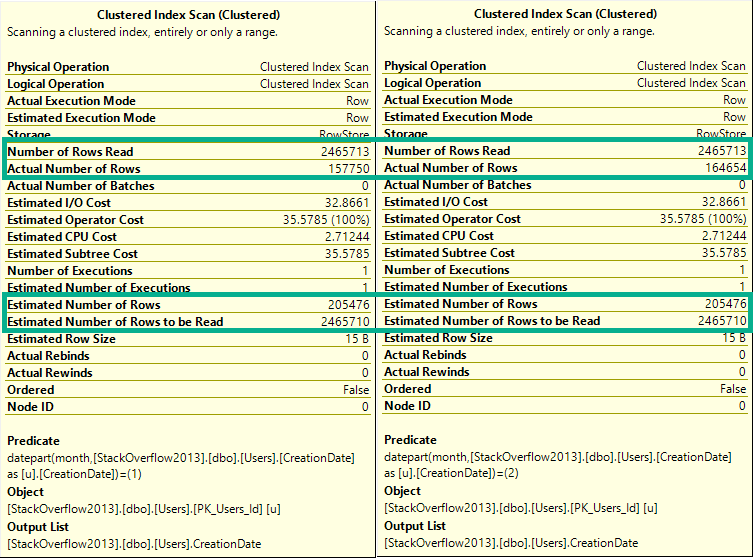
Alright, let’s try that again with by month.
If you hit yourself in the head with a hammer and forgot the TL;DR, here’s what happens:
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 1;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 2;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 3;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 4;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 5;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 6;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 7;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 8;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 9;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 10;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 11;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12;
If you run these, they’ll all have the same guess on the clustered index scan.
To keep things simple, let’s look at the first couple:
BADLY
The difference here is that now every single row estimate will be 205,476.
Lesson learned: The optimizer can make a decent statistical guess at the year portion of a date, but not the month portion.
In a way, you can think of this like a LIKE query.
The optimizer can make a decent guess at ‘YEAR%’, but not at ‘%MONTH%’.
Actual Facts To Snack On And Chew
The same thing happens for both new and old cardinality estimators.
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2008
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE YEAR(u.CreationDate) = 2008
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
Wouldn’t Get Far
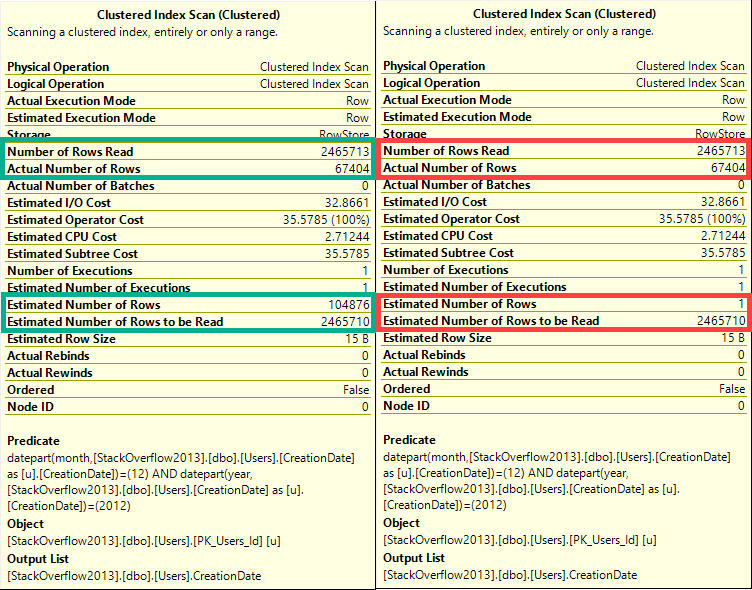
But if we combine predicates, something really different happens between Linda Cardellini estimators.
DECLARE @blob_eater DATETIME;
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
AND YEAR(u.CreationDate) = 2012
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
SELECT @blob_eater = u.CreationDate
FROM dbo.Users AS u
WHERE MONTH(u.CreationDate) = 12
AND YEAR(u.CreationDate) = 2012
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
WRONG
In this case, the old CE (on the right), makes a very bad guess of 1 row.
The new CE (on the left) makes a slightly better, but still not great guess.
Ended
Neither of these is a good way to query date or time data.
You can see in every tooltip that, behind the scenes, the queries used the DATEPART function, which means that also doesn’t help.
The point of this post is that someone may use a function to query the year portion of a date and assume that SQL Server does a good job on any other portion, which isn’t the case.
None of these queries are SARGable, and at no point is a missing index request raised on the CreationDate column, even though if you add one it gets used and reduces reads.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
As a consultant, people sometimes send me query plans. They’re usually estimated, or cached plans.
That’s not bad! You can get a sense of some important things based on them, but there’s a ton of detail in actual plans that makes life easier.
One example is with parameter sniffing: estimated and cached plans look like they did something completely reasonable.
Getting an actual plan is tough, though, especially if it’s a long running query, or the query runs modifications.
Containers Are All The Rage
What if query plan XML had enough information in it for you to “execute” the query locally without returning any results?
What if you could press play, fast forward, and rewind on a query plan?
What if you could try things like using the new or old CE or other hints on the query?
What if parameters could be masked (but differentiated internally) to test parameter sniffing?
This might be possible with the right information collected, even if some of it is imperfect. In newer versions of SQL Server, even information about statistics is gathered by the plan.
With the direction Microsoft is finally going in collecting runtime information about queries, I wouldn’t be surprised if something like this became possible.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
sql_variant can have a maximum length of 8016 bytes. This includes both the base type information and the base type value. The maximum length of the actual base type value is 8,000 bytes.
Since the optimizer needs to plan for your lazinessindecisivenesslack of respect for human life inexperience, you can end up getting some rather enormous memory grants, regardless of the type of data you store in variant columns.
Ol’ Dirty Demo
Here’s a table with a limited set of columns from the Users table.
CREATE TABLE dbo.UserVariant
(
Id SQL_VARIANT,
CreationDate SQL_VARIANT,
DisplayName SQL_VARIANT,
Orderer INT IDENTITY
);
INSERT dbo.UserVariant WITH(TABLOCKX)
( Id, CreationDate, DisplayName )
SELECT u.Id, u.CreationDate, u.DisplayName
FROM dbo.Users AS u
In all, about 2.4 million rows end up in there. In the real table, the Id column is an integer, the CreationDate column is a DATETIME, and the DisplayName column is an NVARCHAR 40.
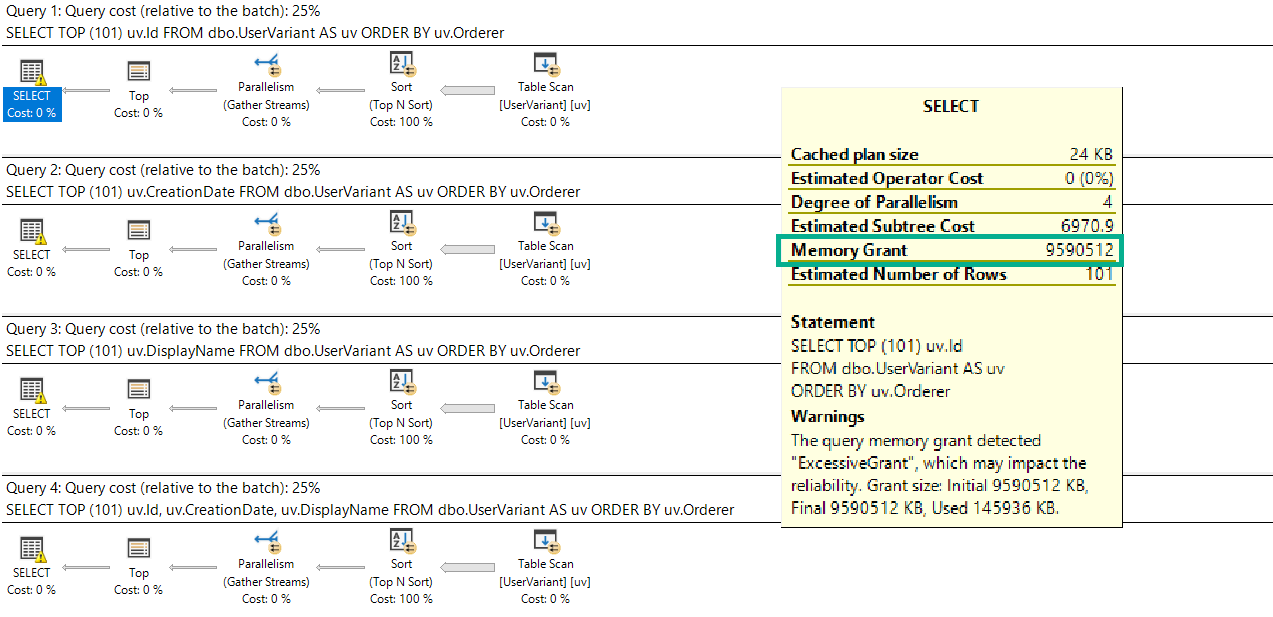
Sadly, no matter which column we select, the memory grant is the same:
SELECT TOP (101) uv.Id
FROM dbo.UserVariant AS uv
ORDER BY uv.Orderer;
SELECT TOP (101) uv.CreationDate
FROM dbo.UserVariant AS uv
ORDER BY uv.Orderer;
SELECT TOP (101) uv.DisplayName
FROM dbo.UserVariant AS uv
ORDER BY uv.Orderer;
SELECT TOP (101) uv.Id, uv.CreationDate, uv.DisplayName
FROM dbo.UserVariant AS uv
ORDER BY uv.Orderer;
It’s also the maximum memory grant my laptop will allow: about 9.6GB.
Large Marge
Get’em!
As if there aren’t enough reasons to avoid sql_variant, here’s another one.
Thanks for reading.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There’s a lot of excitement (alright, maybe I’m sort of in a bubble with these things) about SQL Server 2019 being able to inline most scalar UDFs.
But there’s a sort of weird catch with them. It’s documented, but still.
If you use GETDATE in the function, it can’t be inlined.
Say What?
Let’s look at three examples.
Numero Uno
CREATE OR ALTER FUNCTION dbo.YearDiff(@d DATETIME)
RETURNS INT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @YearDiff INT;
SET @YearDiff = DATEDIFF(HOUR, @d, GETDATE())
RETURN @YearDiff
END;
GO
This function can’t be inlined. It uses the GETDATE function directly in a calculation.
I’m not bothered by that! After all, it’s documented.
In writing.
Numero Dos
CREATE OR ALTER FUNCTION dbo.i_YearDiff(@d DATETIME)
RETURNS INT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @YearDiff INT;
DECLARE @i DATETIME = GETDATE()
SET @YearDiff = DATEDIFF(HOUR, @d, @i)
RETURN @YearDiff
END;
GO
I was thinking that maybe if we just calculated the date once in a variable and then use that, we’d be able to inline the function.
But no.
No we can’t.
Numero Tres
CREATE OR ALTER FUNCTION dbo.NothingToSeeHere(@d DATETIME)
RETURNS INT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @YearDiff INT;
DECLARE @i DATETIME = GETDATE()
SET @YearDiff = 1;
RETURN @YearDiff
END;
GO
What if we don’t even touch GETDATE? Hm?
No.
Still no.
Kinda Weird, Right?
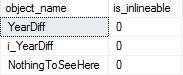
If you’re using SQL Server 2019 and want to find functions that can’t be inlined, start here:
SELECT OBJECT_NAME(m.object_id) AS object_name,
m.is_inlineable
FROM sys.sql_modules AS m
JOIN sys.objects AS o
ON o.object_id = m.object_id
WHERE o.type = 'FN'
AND m.is_inlineable = 0;
None of these functions can be inlined:
Bummer.
Unfortunately, the only real solution here is to rewrite the function entirely as an inline table valued function.
CREATE OR ALTER FUNCTION dbo.InlineYearDiff(@d DATETIME)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT DATEDIFF(HOUR, @d, GETDATE()) AS TimeDiff
GO
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I wanted to show you two situations with two different kinds of spools, and how they differ with the amount of work they do.
I’ll also show you how you can tell the difference between the two.
Two For The Price Of Two
I’ve got a couple queries. One generates a single Eager Index Spool, and the other generates two.
SELECT TOP (1)
u.DisplayName,
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
AND u.LastAccessDate >= b.Date) AS [Whatever],
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id) AS [Total Badges]
FROM dbo.Users AS u
ORDER BY [Total Badges] DESC;
GO
SELECT TOP (1)
u.DisplayName,
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
AND u.LastAccessDate >= b.Date ) AS [Whatever],
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
AND u.LastAccessDate >= b.Date) AS [Whatever],
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id) AS [Total Badges]
FROM dbo.Users AS u
ORDER BY [Total Badges] DESC;
GO
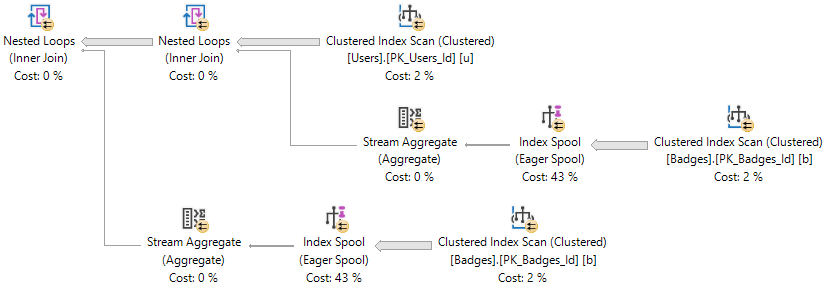
The important part of the plans are here:
UnoDos
The important thing to note here is that both index spools have the same definition.
The two COUNT(*) subqueries have identical logic and definitions.
Fire Sale
The other type of plan is a delete, but with a different number of indexes.
/*Add these first*/
CREATE INDEX ix_whatever1 ON dbo.Posts(OwnerUserId);
CREATE INDEX ix_whatever2 ON dbo.Posts(OwnerUserId);
/*Add these next*/
CREATE INDEX ix_whatever3 ON dbo.Posts(OwnerUserId);
CREATE INDEX ix_whatever4 ON dbo.Posts(OwnerUserId);
BEGIN TRAN
DELETE p
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ROLLBACK
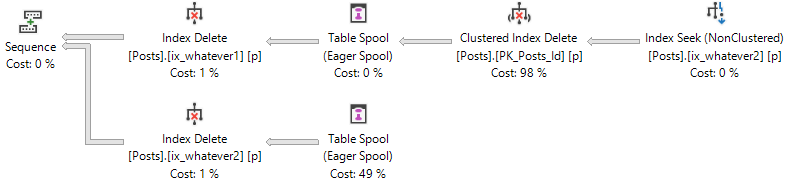
With two indexesWith four indexes
Differences?
Using Extended Events to track batch completion, we can look at how many writes each of these queries will do.
The select query with two spools does twice as many reads (and generally twice as much work) as the query with one spool
The delete query with four spools does identical writes as the one with two spools, but more work overall (twice as many indexes need maintenance)
Looking at the details of each select query, we can surmise that the two eager index spools were populated and read from separately.
In other words, we created two indexes while this query ran.
For the delete queries, we can surmise that a single spool was populated, and read from either two or four times (depending on the number of indexes that need maintenance).
Another way to look at it, is that in the select query plans, each spool has a child operator (the clustered index scan of Badges). In the delete plans, three of the spool operators have no child operator. Only one does, which signals that it was populated and reused (for Halloween protection).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.