Quite Different
Hash spills are nothing like sort spills, in that even with (very fast) disks, there’s no immediate benefit to breaking the hash down into pieces via a spill.
In fact, there are many downsides, especially when memory is severely constrained.
The query that I’m using looks about like this:
SELECT v.PostId, COUNT_BIG(*) AS records FROM dbo.Votes AS v GROUP BY v.PostId HAVING COUNT_BIG(*) > 2147483647
The way this is written, we’re forced to count everything, and then only filter out rows at the end.
The idea is to spend no time waiting on rows to be displayed in SSMS.
Just One Int
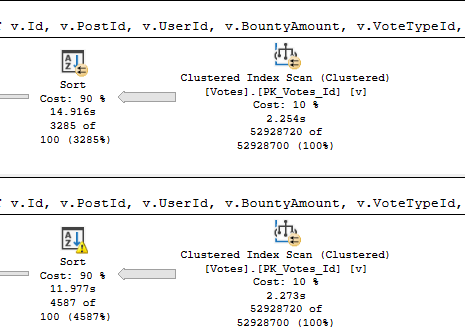
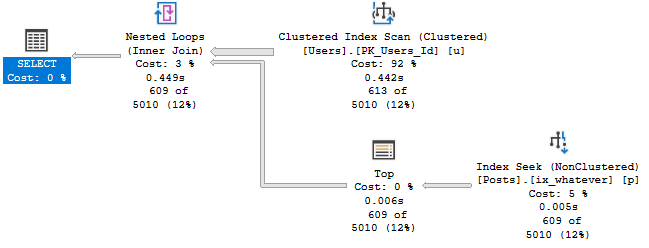
To get an idea what performance looks like, I’m starting with one integer column.
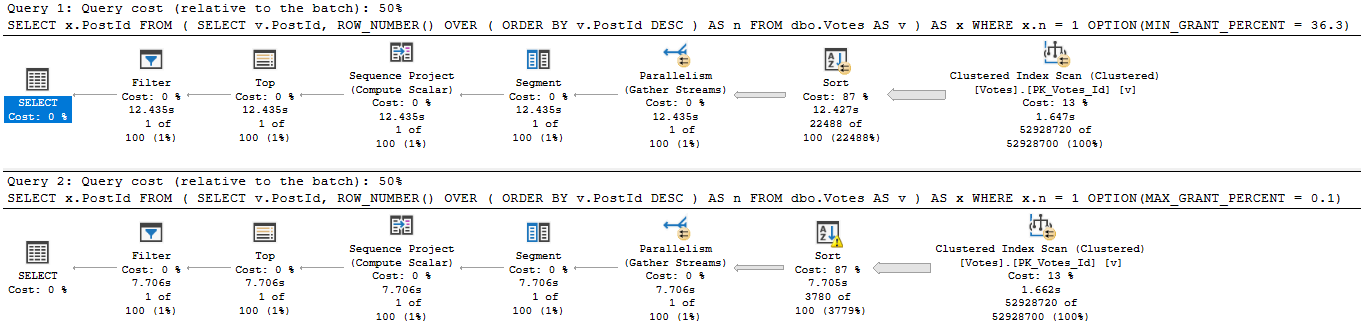
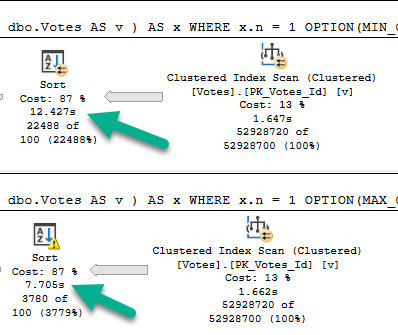
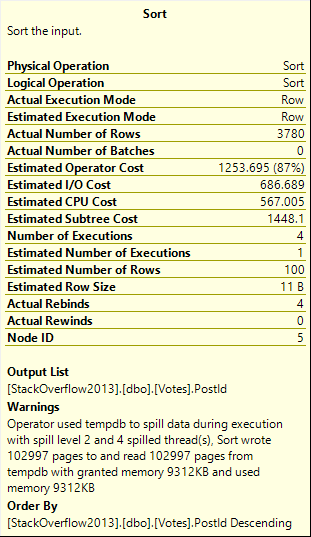
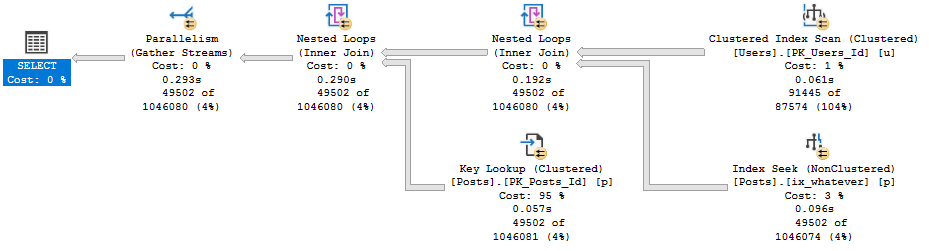
With no spills and a 776 MB memory grant, this runs for about 15 seconds.

If we drop the grant down to about 10 MB, we spill a bunch, but runtime doesn’t go up too much.

And if we drop it down to 4.5 MB, things go absolutely, terribly, pear shaped.

The difference in both the number of pages spilled and the spill level are pretty dramatic.
Expansive
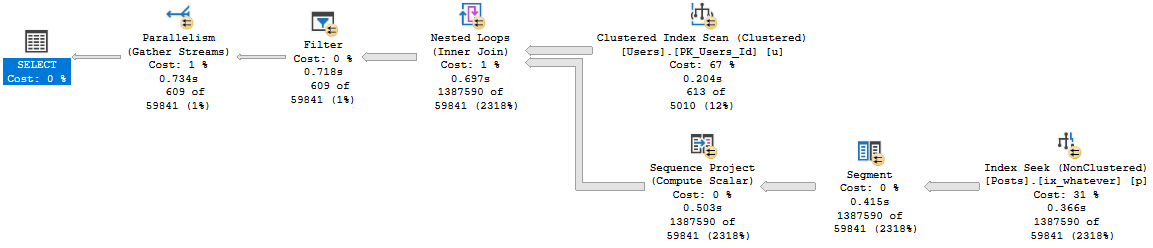
If we expand the query a bit to look like this, memory starts to matter more:
SELECT v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Votes AS v
GROUP BY v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
HAVING COUNT_BIG(*) > 2147483647
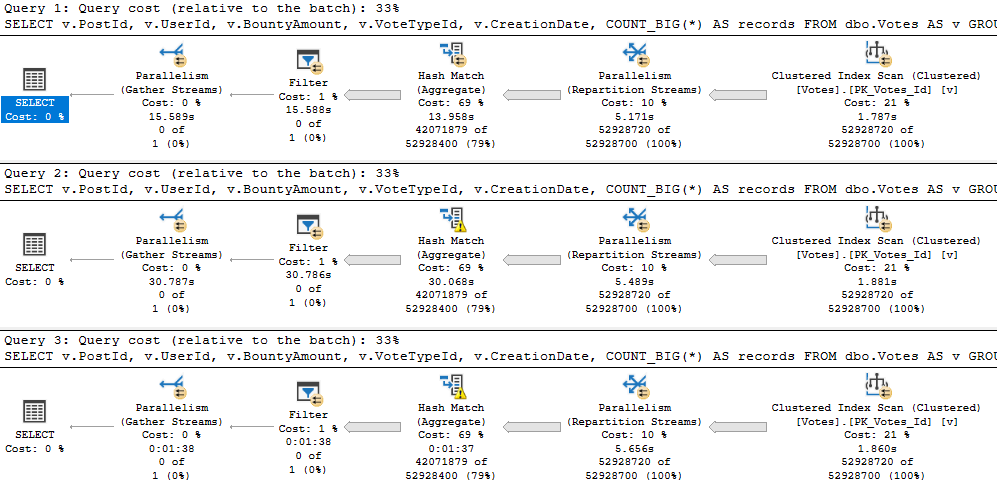
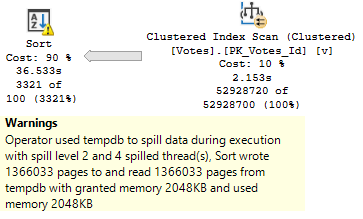
With more columns, the first spill escalates to a higher level faster, and the second spill absolutely wipes out.
It runs for almost 2 minutes.
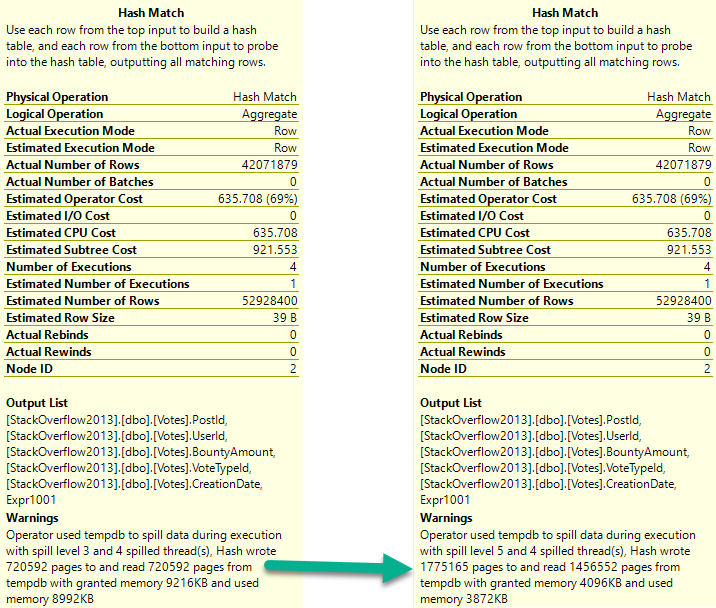
As a side note, I really hate how long that Repartition Streams operator runs for.
Predictably
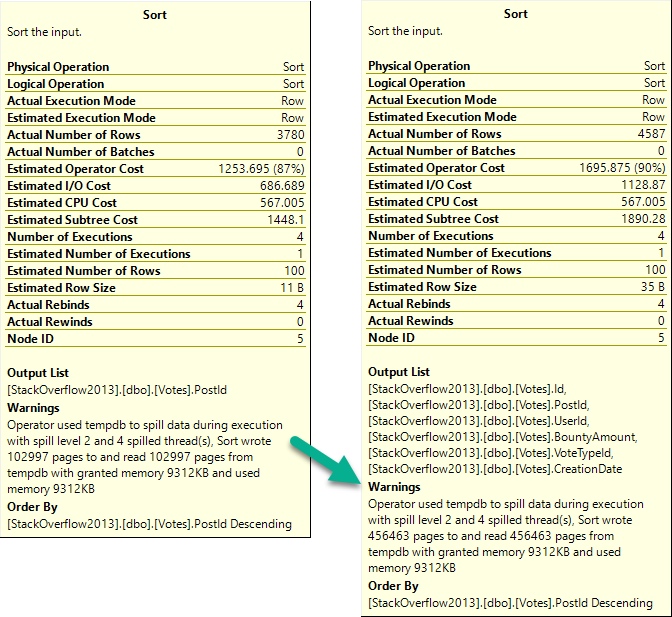
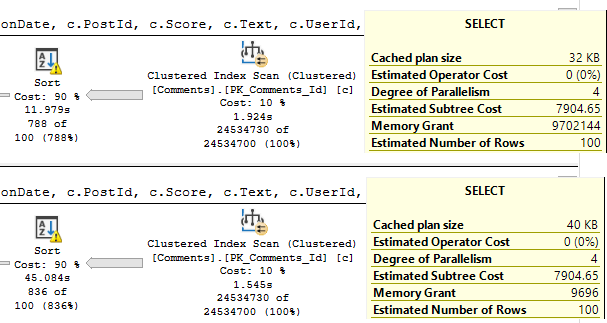
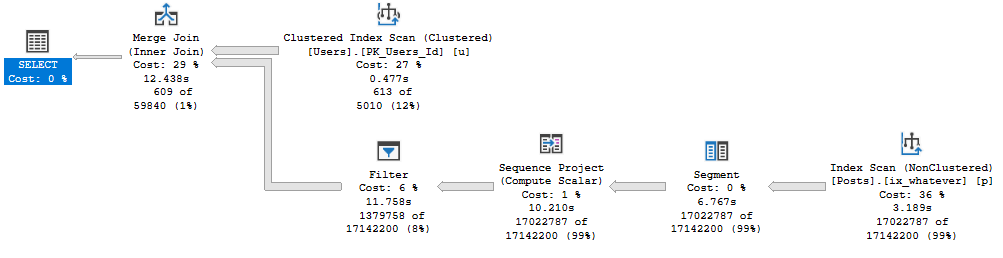
When we get the Comments table involved, that string column beats us right up.
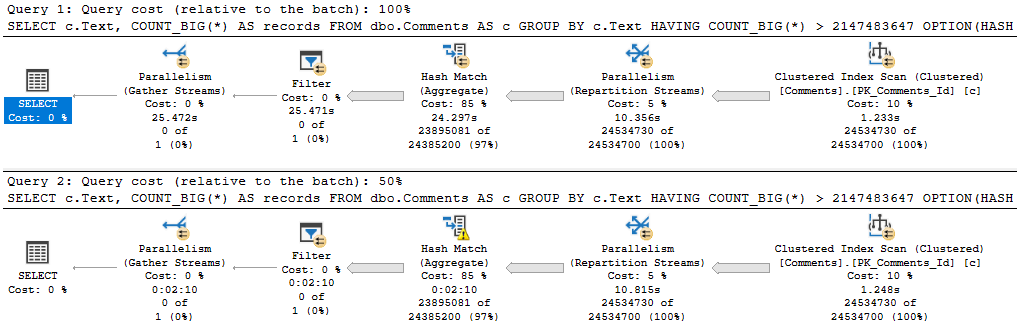
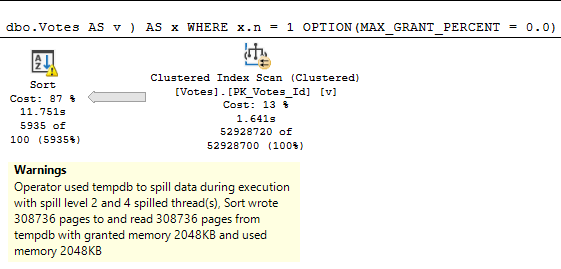
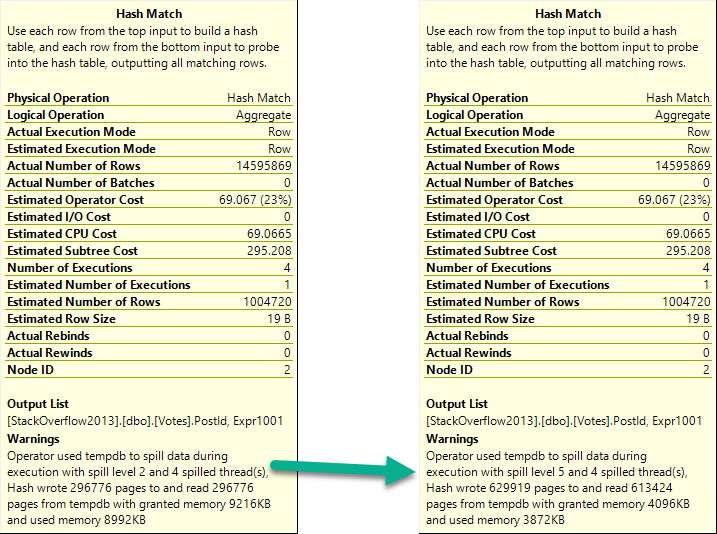
The first query asks for the largest possible grant on my laptop: 9.7GB. The second query gets 10MB.
The spill is godawful.
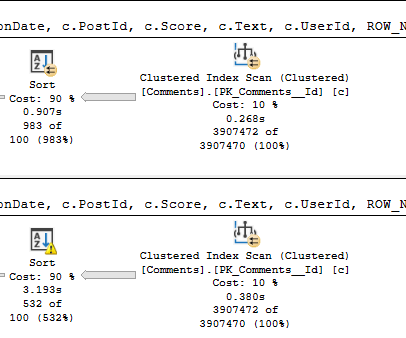
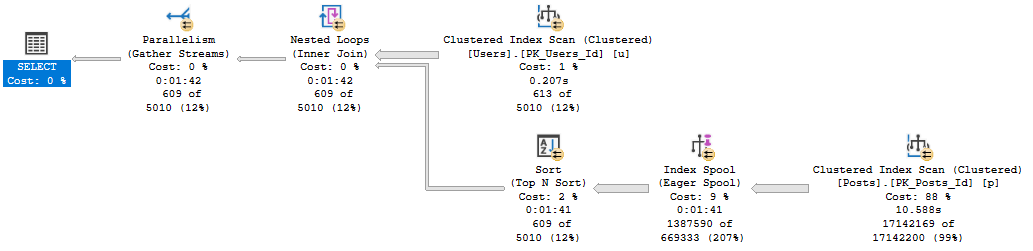
When we reduce the memory grant to 4.5MB, the spill runs another 1:20, for a total of 3:31.

Those spills are the root cause of why these queries run longer than any we’ve seen to date in this series.
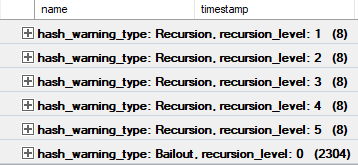
Something quite funny happens when Hashes of any variety spill “too much” — which you can read about in more detail here.
There’s an Extended Event called “hash warning” that we can use to track recursion and bailout.
Here’s the final output aggregated:
In Which I Belabor The Point Anyway, Despite Saying…
Not to belabor the point too much, but if we select and group all the columns in the Comments table, things get a bit worse.
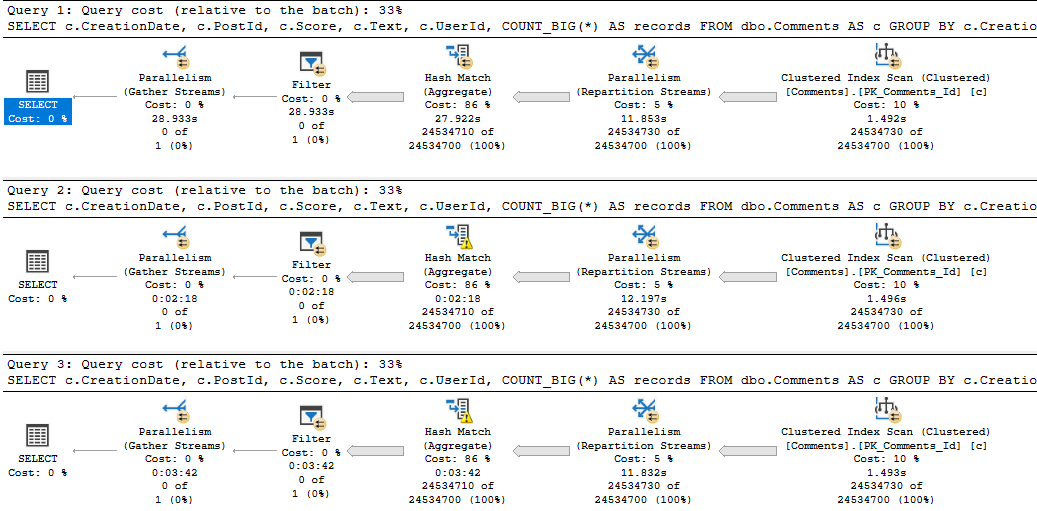
Three minutes of spills. What a time to be alive.
But, yeah, the bulk of the trouble here is caused by the string column.
Adding in some numbers and a date on top doesn’t have a profound effect.
Taking Up
While Sort Spills certainly dragged query performance down a bit when memory was severely limited, Hash Spills were far more detrimental.
If I had to choose between which one to investigate first, it’d be Hash spills.
But again, small spills are often not worth the effort, and in some cases, you may always see spills.
If your server is totally under-provisioned from a memory perspective, or if there are multiple concurrent memory consuming operations (i.e. they can’t share intra-query memory), it may not be possible for a large enough grant to be give to satisfy all of them.
This is part of why writing very large queries can be perilous, and it’s usually worth splitting them up.
In tomorrow’s post, we’ll look at hash joins.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.