There are many good reasons to parameterize queries.
There are, of course, downsides, too. Parameter sensitivity, AKA parameter sniffing, being the prime one.
But let’s say you consult the internet, or find a consultant on the internet, and they tell you that you ought to parameterize your queries.
It all sounds like a grand idea — you’ll get better plan reuse, and hopefully the plan cache will stop clearing itself out like a drunken ourobouros.
You could even use a setting called forced parameterization, which doesn’t always work.
Apart from the normal rules about when parameteriztion, forced or not, may not work, there’s another situation that can make things difficult.
Client Per Thing
Let’s assume for a second that you have a client-per-database, or client-per-schema model.
If I execute parameterized code like this:
DECLARE @i INT = 2
DECLARE @sql NVARCHAR(MAX) = N'
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Reputation = @ii
'
EXEC sys.sp_executesql @sql, N'@ii INT', @ii = @i;
But from different database contexts (I have a few different versions of StackOverflow on my server, but I’m going to show results from 2013 and 2010), we’ll get separate cached plans, despite them having identical:
Costs
Query Plans
SQL Handles
Query Hashes
Frida Fredo
The same thing would happen with any parameterized code executed in a different context — stored procedures, functions… well. You get the idea.
Forced parameterization may help queries within the same context with plan reuse, but there are certain boundaries they won’t cross.
Don’t get me wrong, here. I’m not complaining. There’s so much that could be different, I wouldn’t want plan reuse across these boundaries. Heck, I may even separate stuff specifically to get different plans. As usual, I don’t want you, dear reader, to be surprised by this behavior.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Having some key lookups in your query plans is generally unavoidable.
You’ll wanna select more columns than you wanna put in a nonclustered index, or ones with large data types that you don’t wanna bloat them with.
Enter the key lookup.
They’re one of those things — I’d say even the most common thing — that makes parameterized code sensitive to the bad kind of parameter sniffing, so they get a lot of attention.
The thing is, most of the attention that they get is just for columns you’re selecting, and most of the advice you get is to “create covering indexes”.
That’s not always possible, and that’s why I did this session a while back on a different way to rewrite queries to sometimes make them more efficient. Especially since key lookups may cause blocking issues.
Milk and Cookies
At some point, everyone will come across a key lookup in a query plan, and they’ll wonder if tuning it will fix performance.
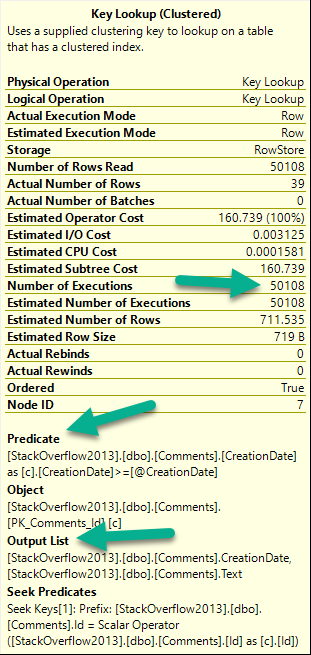
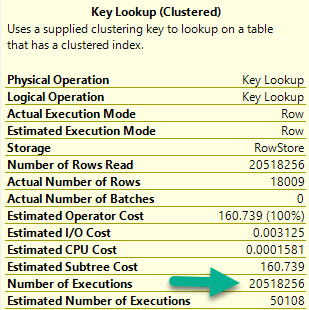
There are three things to pay attention to when you look at a key lookup:
I know what to do
Number of executions: This is usually more helpful in an actual plan
If there are any Predicates involved: That means there are parts of your where clause not in your nonclustered index
If there’s an Output List involved: That means you’re selecting columns not in your nonclustered index
For number of executions, generally higher numbers are worse. This can be misleading if you’re looking at a cached plan because… You’re going to see the cached number, not the runtime number. They can be way different.
Notice I’m not worried about the Seek Predicates here — that just tells us how the clustered index got joined to the nonclustered index. In other words, it’s the clustered index key column(s).
Figure It Out
Here’s our situation: we’re working on a new stored procedure.
CREATE PROCEDURE dbo.predicate_felon (@Score INT, @CreationDate DATETIME)
AS
BEGIN
SELECT *
FROM dbo.Comments AS c
WHERE c.Score = @Score
AND c.CreationDate >= @CreationDate
ORDER BY c.CreationDate DESC;
END;
Right now, aside from the clustered index, we only have this nonclustered index. It’s great for some other query, or something.
CREATE INDEX ix_whatever
ON dbo.Comments (Score, UserId, PostId)
GO
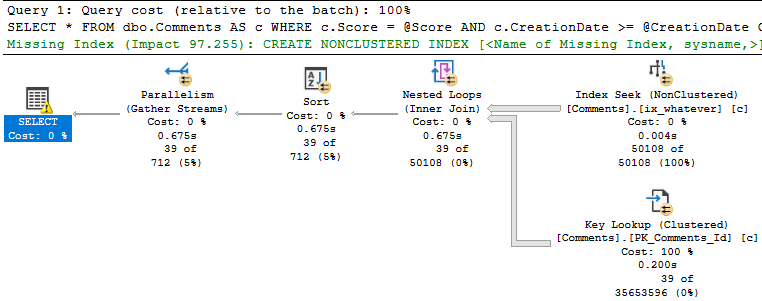
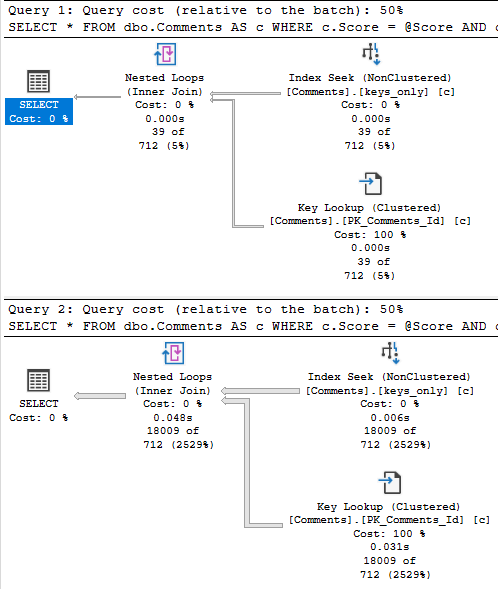
When we run the stored procedure like this, it’s fast.
SQL Server wants an index — a fully covering index — but if we create it, we end up a 7.8GB index that has every column in the Comments table in it. That includes the Text column, which is an NVARCHAR(700). Sure, it fixes the key lookup, but golly and gosh, that’s a crappy index to have hanging around.
Bad Problems On The Rise
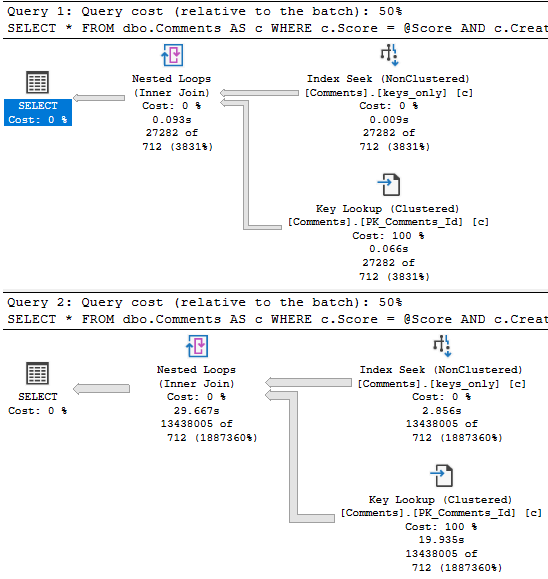
The issue turns up when we run the procedure like this:
EXEC dbo.predicate_felon @Score = 0, --El Zero
@CreationDate = '2013-12-31';
Not so much.
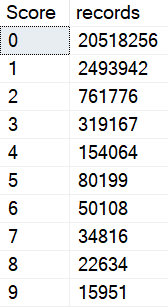
This happens because there are a lot more 0 scores than 6 scores.
Quiet time
Smarty Pants
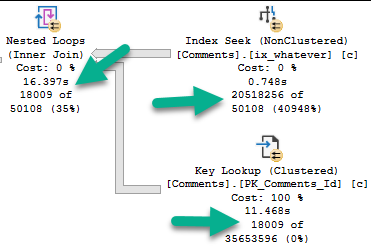
Eagle eyed readers will notice that the second query only returns ~18k rows, but it takes ~18 seconds to do it.
The problem is how much time we spend locating those rows. Sure, we can Seek into the nonclustered index to find all the 0s, but there are 20.5 million of them.
Looking at the actual plan, we can spot a few things.
Hunger ManagementHangman
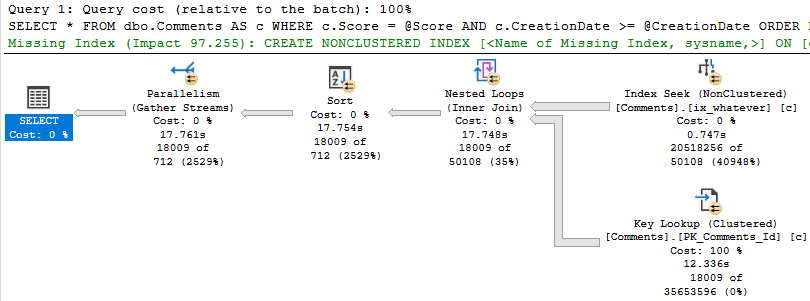
The 18k rows we end up with are only filtered to with they key lookup, but it has to execute 20.5 million times to evaluate that extra predicate.
If we just index the key columns, the key lookup to get the other columns (PostId, Text, UserId) will only execute ~18k times. That’s not a big deal at all.
CREATE NONCLUSTERED INDEX keys_only
ON dbo.Comments ( Score, CreationDate );
This index is only ~500MB, which is a heck of a lot better than nearly 8GB covering the entire thing.
With that in place, both the score 6 and score 0 plans are fast.
rq
Why This Is Effective, and When It Might Not Be
This works here because the date filter is restrictive.
When we can eliminate more rows via the index seek, the key lookup is less of a big deal.
If the date predicate were much less restrictive, say going back to 2011, boy oh boy, things get ugly for the 0 query again.
Of course, returning that many rows will suck no matter what, so this is where other techniques come in like Paging, or charging users by the row come into play.
What? Why are you looking at me like that?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When you find unused indexes, whether using Some Script From The Internet™, sp_BlitzIndex, or Database Telepathy, the first thing most people think of is “wasted space”.
Sure, okay, yeah. That’s valid. They’re in backups, restores, they get hit by CHECKDB. You probably rebuild them if there’s a whisper of fragmentation.
But it’s not the end of the story.
Not by a long shot.
Today we’re going to look at how redundant indexes can clog the buffer pool up.
Holla Back
If you want to see the definitions for the views I’m using, head to this post and scroll down.
Heck, stick around and watch the video too.
LIKE AND SUBSCRIBE.
Now, sp_BlitzIndex has two warnings to catch these “bad” indexes:
Unused Indexes With High Writes
NC Indexes With High Write:Read Ratio
Unused are just what they sound like: they’re not helping queries read data at all. Of course, if you’ve rebooted recently, or rebuilt indexes on buggy versions of SQL Server, you might get this warning on indexes that will get used. I can’t fix that, but I can tell you it’s your job to keep an eye on usage over time.
Indexes with a high write to read ratio are also pretty self-explanatory. They’re sometimes used, but they’re written to a whole lot more. Again, you should keep an eye on this over time, and try to understand both how important they might be to your workload, or how much they might be hurting your workload.
I’m not going to set up a fake workload to generate those warnings, but I am going to create some overlapping indexes that might be good candidates for you to de-clutter.
Index Entrance
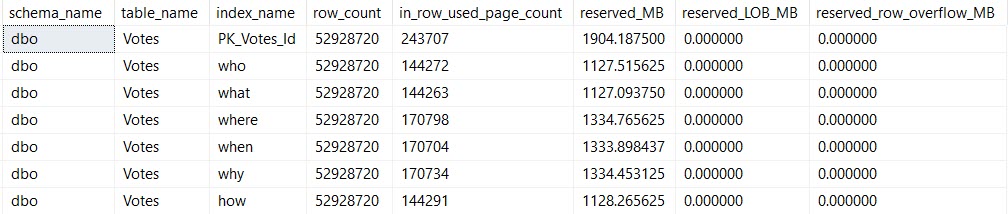
The Votes table is pretty narrow, but it’s also pretty big — 53 million rows or so as of Stack 2013.
Here are my indexes:
CREATE INDEX who ON dbo.Votes(PostId, UserId) INCLUDE(BountyAmount);
CREATE INDEX what ON dbo.Votes(UserId, PostId) INCLUDE(BountyAmount);
CREATE INDEX [where] ON dbo.Votes(CreationDate, UserId) INCLUDE(BountyAmount);
CREATE INDEX [when] ON dbo.Votes(BountyAmount, UserId) INCLUDE(CreationDate);
CREATE INDEX why ON dbo.Votes(PostId, CreationDate) INCLUDE(BountyAmount);
CREATE INDEX how ON dbo.Votes(VoteTypeId, BountyAmount) INCLUDE(UserId);
First, I’m gonna make sure there’s nothing in memory:
CHECKPOINT;
GO 2
DBCC DROPCLEANBUFFERS;
GO
Don’t run that in production. It’s stupid if you run that in production.
Now when I go to look at what’s in memory, nothing will be there:
SELECT *
FROM dbo.WhatsUpMemory AS wum
WHERE wum.object_name = 'Votes'
I’m probably not going to show you the results of an empty query set. It’s not too illustrative.
I am going to show you the index sizes on disk:
SELECT *
FROM dbo.WhatsUpIndexes AS wui
WHERE wui.table_name = 'Votes';
Size Mutters
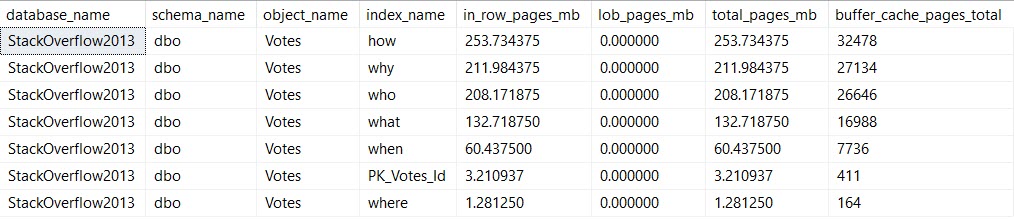
And I am going to show you this update:
UPDATE v
SET v.BountyAmount = 2147483647
FROM dbo.Votes AS v
WHERE v.BountyAmount IS NULL
AND v.CreationDate >= '20131231'
AND v.VoteTypeId > 2;
After The Update
This is when things get more interesting for the memory query.
Life Of A Moran
We’re updating the column BountyAmount, which is present in all of the indexes I created. This is almost certainly an anti-pattern, but it’s good to illustrate the problem.
Pieces of every index end up in memory. That’s because all data needs to end up in memory before SQL Server will work with it.
It doesn’t need the entirety of any of these indexes in memory — we’re lucky enough to have indexes to help us find the 10k or so rows we’re updating. I’m also lucky enough to have 64GB of memory dedicated to this instance, which can easily hold the full database.
But still, if you’re not lucky enough to be able to fit your whole database in memory, wasting space in the buffer pool for unused (AND OH GODD PROBABLY FRAGMENTED) indexes just to write to them is a pretty bad idea.
After all, it’s not just the buffer pool that needs memory.
You also need memory for memory grants (shocking huh?), and other caches and activities (like the plan cache, and compressed backups).
Cleaning up those low-utilization indexes can help you make better use of the memory that you have.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In dramatic fashion, I’m revisiting something from this post about stats updates.
It’s a quick post, because uh… Well. Pick a reason.
Get In Gear
Follow along as I repeat all the steps in the linked post to:
Load > 2 billion rows into a table
Create a stats object on every column
Load enough new data to trigger a stats refresh
Query the table to trigger the stats refresh
Except this time, I’m adding a mAxDoP 1 hint to it:
SELECT COUNT(*)
FROM dbo.Vetos
WHERE UserId = 138
AND PostId = 138
AND BountyAmount = 138
AND VoteTypeId = 138
AND CreationDate = 138
OPTION(MAXDOP 1);
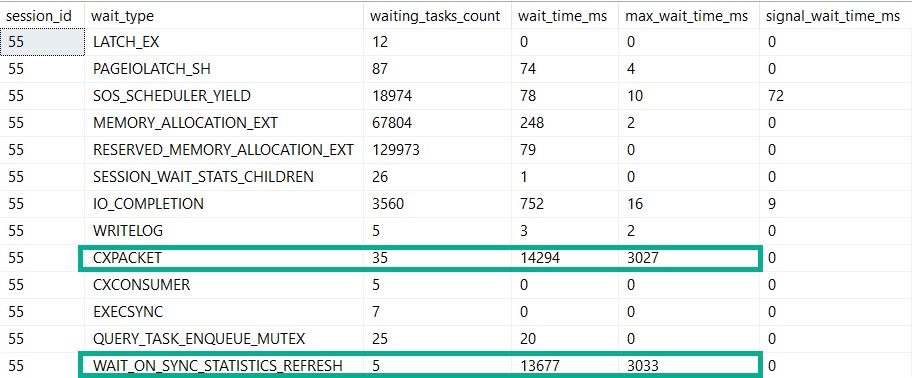
Here’s Where Things Get Interesting
Bothsies
Our MaXdOp 1 query registers nearly the same amount of time on stats updates and parallelism.
If this is madness…
But our plan is indeed serial. Because we told it to be.
By setting maxDOP to 1.
Not Alone
So, if you’re out there in the world wondering why this crazy kinda thing goes down, here’s one explanation.
Are there others? Probably.
But you’ll have to find out by setting MAXdop to 1 on your own.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ve written about all of these separately in various places, so if you’ve been reading my blog(s) and Stack Exchange answers for a while, these may seem old news.
Of course, collecting them all in one place was inspired by another recent Q&A.
Let’s get going.
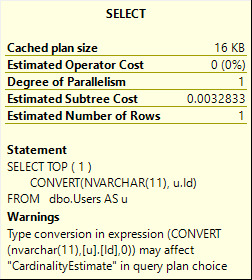
Eyeroll
SELECT TOP ( 1 )
CONVERT(NVARCHAR(11), u.Id)
FROM dbo.Users AS u;
Seems pretty explicit to me, pal.
Yep. I’d ignore this one all day long.
Squints
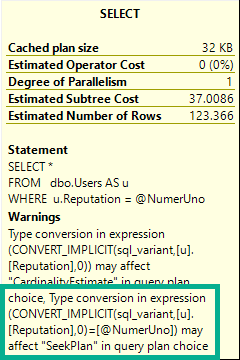
DECLARE @NumerUno SQL_VARIANT = '10000000';
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = @NumerUno;
Cheap haircut
That’s awfully presumptuous.
I don’t even have A index on Reputation, nevermind enough index to facilitate an entire Seek Plan.
I’ve seen this catch people off guard. They fix the implicit conversion, and expect an index seek.
Ah well.
Checks Notes
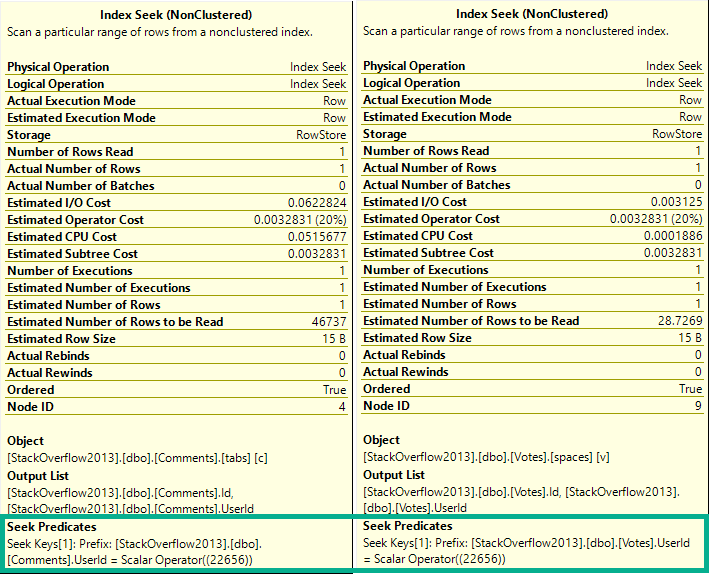
CREATE INDEX tabs
ON dbo.Comments(UserId);
CREATE INDEX spaces
ON dbo.Votes(UserId);
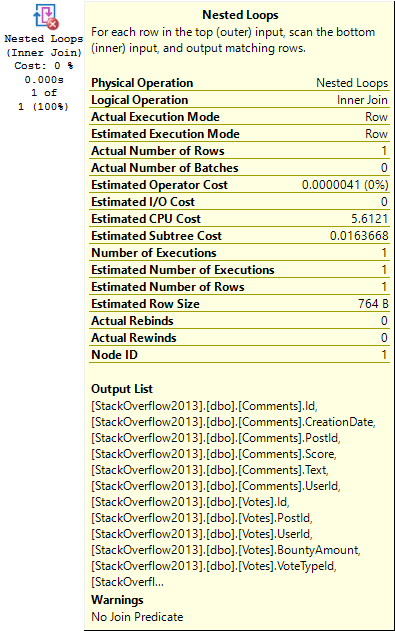
SELECT TOP (1) *
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.UserId = c.UserId
WHERE c.UserId = 22656;
RFC
The check for this happens at the join. There’s no further down-plan check on the index access operations.
If there were, it’d see this:
Complaint Apartment
Only matching rows come out, anyway. The join predicate is, like, implied in the where clause.
Oh Um Sweatie No No No No No
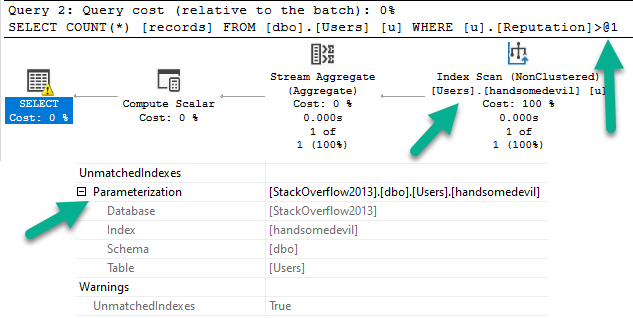
CREATE INDEX handsomedevil
ON dbo.Users(Reputation)
WHERE Reputation > 1000000;
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Reputation > 1000000;
Ayyyyyyyy
So the simple parameterization thing fires off a warning about a filtered index that we used not being used.
yep yep yep yep yep yep
First Of All, Ew.
Genie In A Bottle
This thing needs some boundaries. Maybe like available memory should figure in or something?
Probably?
Call me, I have lots of great ideas.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Instead, let’s talk about a different one: Editable Execution Plans.
We already have this to some degree via query hints and turning optimizer rules on and off.
The problem is that you have to remember all those crazy things, and some hints can affect multiple parts of the plan that you don’t want changed.
If the query you’re changing is in the middle of a big ol’ stored procedure, this process is even more tedious.
Glamorous
Let’s say you wanna experiment with different things, but not without re-running a query over and over to check on the plan with your written hints.
You could change:
Join order
Join types
Index choices
Aggregations
Seeks or Scans
Memory grants and fractions
Basically any element exposed in the XML would be up for grabs — I won’t list them all here, because I think you get the point.
Then you can run your query with your new plan.
If it’s a stunning success, you can force that plan.
Spool Removal
This has downsides, of course.
You could make things worse (but you could do that anyway — trust me, I do it all the time), you could get incorrect results, or errors if you remove certain operators (again, these are all things you can do by being silly anyway).
But, like query hints, this could be a really powerful tool in the hands of experienced query tuners, and people looking to get better at query tuning.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I know, you’re sitting there and you’re staring at this post thinking “but I use Plan Explorer”.
I use it too, sometimes. The problem is that when I’m with a client, they don’t always have it.
More locally, I think there are some things SSMS visualizes better than Plan Explorer.
One example is rows on parallel threads. Another example is the operator times that started showing up a while back in SSMS 18, which aren’t there at all yet.
There’s some other stuff, but this isn’t what the post is about.
Complaint Department
A lot of the complaints people have about query plans in SSMS are with what’s in front of them.
It’s one of the like, 2 episodes I remember. I think a dog dies or something in the other one.
Anyway, the redhead one from the staring meme moves in with the drunk robot one and thinks the apartment is a closet but then opens a door and reveals a big apartment with a great view at the end of the commercial delivery time.
The part of SSMS people complain about.
And I get it. There’s a real lack of attention paid to UX in query plans.
It’s not quite as bad as Extended Events, but it’s there.
BUUUUUUUUUUUUUUUUUUTT…
Button Pusher
I read a lot of posts about query plans, and I rarely see people bring up the properties tab.
And I get it. The F4 button is right next to the F5 button. If you hit the wrong one, you might ruin everything.
But hear me out, dear reader. I care about you. I want your query plan reading experience to be better.
Hit F4.
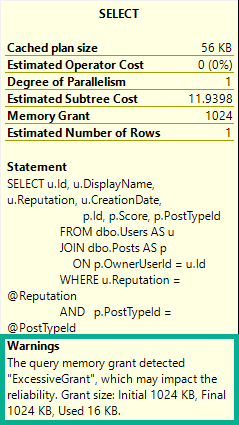
Look at what you can get, just from the SELECT operator:
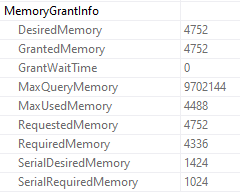
Memory Grant
Ooey, gooey, memory grant info.
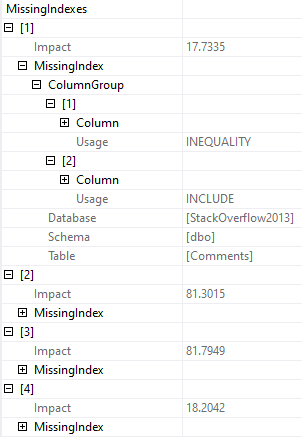
Missing Indexes
If there’s more than one missing index, you can see all of them.
Now, yeah, this sucks because you can’t script them out. Assembling them from here is pretty crappy.
But at least it’s not just the first one that may or may not be the best one.
Goldmine
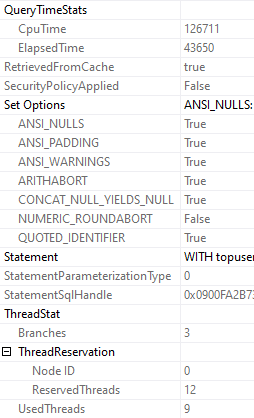
You can see the CPU and elapsed time. Since we’re on the select operator, we get the full plan’s timing.
If you get the properties on individual operators, you can see the timing for (most) specific operators.
One part that I love is ThreadStat, which tells you how many concurrent parallel branches, and how many threads your query reserved and used.
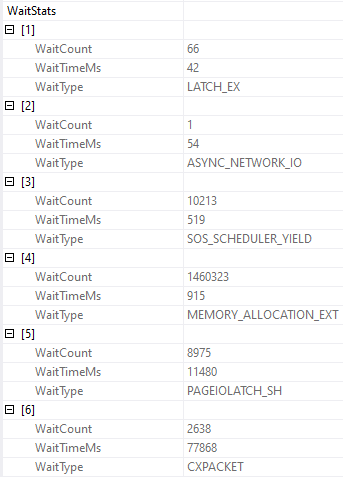
Waist. Waste. Waits.
You can also get wait stats, if you’re into that sort of thing.
And, yeah, this part leaves some data out. You won’t see CXCONSUMER here, or LCK_ waits, which is frustrating.
Nopebooks
Since query plans are what I primarily care about, I’m sticking with SSMS.
And when I look at query plans, I’m hitting F4.
Trust me. If you start poking around in there, you’ll be amazed at what you can find.
If only you knew how bad things really are.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I use it often in my demo queries because I try to make the base query to show some behavior as simple as possible. That doesn’t always work out, but, whatever. I’m just a bouncer, after all.
The problem with very simple queries is that they may not trigger the parts of the optimizer that display the behavior I’m after. This is the result of them only reaching trivial optimization. For example, trivial plans will not go parallel.
If there’s one downside to making the query as simple as possible and using 1 = (SELECT 1), is that people get very distracted by it. Sometimes I think it would be less distracting to make the query complicated and make a joke about it instead.
The Trouble With Trivial
I already mentioned that trivial plans will never go parallel. That’s because they never reach that stage of optimization.
They also don’t reach the “index matching” portion of query optimization, which may trigger missing index requests, with all their fault and frailty.
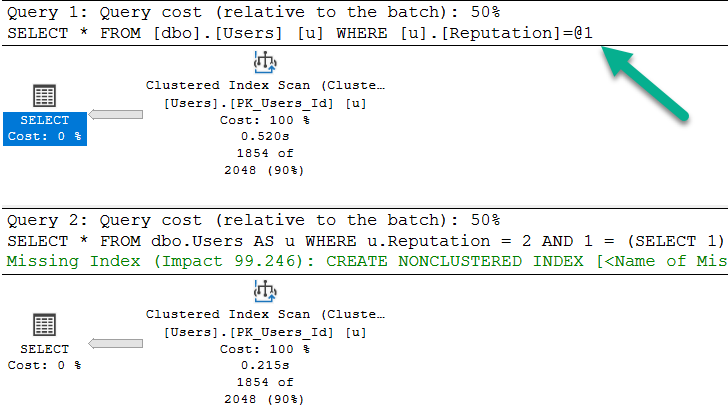
/*Nothing for you*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2;
/*Missing index requests*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2
AND 1 = (SELECT 1);
>greentext
Note that the bottom query gets a missing index request, and is not simple parameterized. The only reason the first query takes ~2x as long as the second query is because the cache was cold. In subsequent runs, they’re equal enough.
What Gets Fully Optimized?
Generally, things that introduce cost based decisions, and/or inflate the cost of a query > Cost Threshold for Parallelism.
Joins
Subqueries
Aggregations
Ordering without a supporting index
As a quick example, these two queries are fairly similar, but…
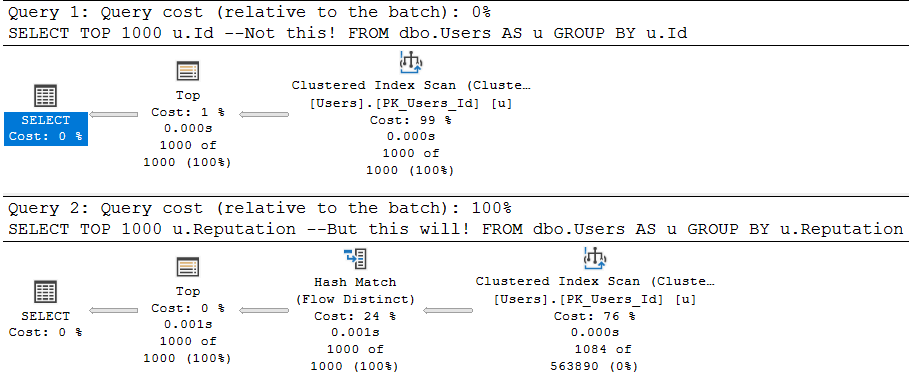
/*Unique column*/
SELECT TOP 1000 u.Id --Not this!
FROM dbo.Users AS u
GROUP BY u.Id;
/*Non-unique column*/
SELECT TOP 1000 u.Reputation --But this will!
FROM dbo.Users AS u
GROUP BY u.Reputation;
One attempts to aggregate a unique column (the pk of the Users table), and the other aggregates a non-unique column.
The optimizer is smart about this:
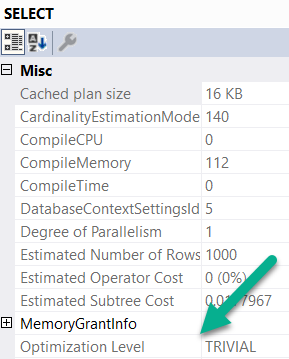
Flowy
The first query is trivially optimized. If you want to see this, hit F4 when you’re looking at a query plan. Highlight the root operator (select, insert, update, delete — whatever), and look at the optimization level.
wouldacouldashoulda
Since aggregations have no effect on unique columns, the optimizer throws the group by away. Keep in mind, the optimizer has to know a column is unique for that to happen. It has to be guaranteed by a uniqueness constraint of some kind: primary key, unique index, unique constraint.
The second query introduces a choice, though! What’s the cheapest way to aggregate the Reputation column? Hash Match Aggregate? Stream Aggregate? Sort Distinct? The optimizer had to make a choice, so the optimization level is full.
What About Indexes?
Another component of trivial plan choice is when the choice of index is completely obvious. I typically see it when there’s either a) only a clustered index or b) when there’s a covering nonclustered index.
If there’s a non-covering nonclustered index, the choice of a key lookup vs. clustered index scan introduces that cost based decision, so trivial plans go out the window.
Here’s an example:
CREATE INDEX ix_creationdate
ON dbo.Users(CreationDate);
SELECT u.CreationDate, u.Id
FROM dbo.Users AS u
WHERE u.CreationDate >= '20131229';
SELECT u.Reputation, u.Id
FROM dbo.Users AS u
WHERE u.Reputation = 2;
SELECT u.Reputation, u.Id
FROM dbo.Users AS u WITH(INDEX = ix_creationdate)
WHERE u.Reputation = 2;
With an index only on CreationDate, the first query gets a trivial plan. There’s no cost based decision, and the index we created covers the query fully.
For the next two queries, the optimization level is full. The optimizer had a choice, illustrated by the third query. Thankfully it isn’t one that gets chosen unless we force the issue with a hint. It’s a very bad choice, but it exists.
When It’s Wack
Let’s say you create a constraint, because u loev ur datea.
ALTER TABLE dbo.Users
ADD CONSTRAINT cx_rep CHECK
( Reputation >= 1 AND Reputation <= 2000000 );
When we run this query, our newly created and trusted constraint should let it bail out without doing any work.
SELECT u.DisplayName, u.Age, u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation = 0;
But two things happen:
my name is bogus
The plan is trivial, and it’s auto-parameterized.
The auto-parameterization means a plan is chosen where the literal value 0 is replaced with a parameter by SQL Server. This is normally “okay”, because it promotes plan reuse. However, in this case, the auto-parameterized plan has to be safe for any value we pass in. Sure, it was 0 this time, but next time it could be one within the range of valid reputations.
Since we don’t have an index on Reputation, we have to read the entire table. If we had an index on Reputation, it would still result in a lot of extra reads, but I’m using the clustered index here for ~dramatic effect~
Table 'Users'. Scan count 1, logical reads 44440
Of course, adding the 1 = (SELECT 1) thing to the end introduces full optimization, and prevents this.
The query plan without it is just a constant scan, and it does 0 reads.
Rounding Down
So there you have it. When you see me (or anyone else) use 1 = (SELECT 1), this is why. Sometimes when you write demos, a trivial plan or auto-parameterization can mess things up. The easiest way to get around it is to add that to the end of a query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.